Cedar : une perspective de langage commun pour l'IAM
Publié par La rédaction le - mis à jour à
Un langage pour définir des politiques d'accès et une spécification pour les contrôler : c'est le principe de Cedar, un projet émanant d'AWS.
AWS aurait-il mieux fait de développer une API WASM ou eBPF plutôt que Cedar ? La question se pose à propos de ce langage spécifique à la définition de politiques de contrôle d'accès.
Deux services actuellement en version préliminaire l'exploitent. D'un côté, Amazon Verified Permissions (gestion des permissions). De l'autre, AWS Verified Access (connectivité sécurisée aux applications d'entreprise sans VPN).
Cedar a toutefois un potentiel plus large, résumé dans la fameuse promesse « build once, deploy anywhere ». En d'autres termes, ici, « développez votre propre IAM ».
À la composante langage, Cedar associe une spécification pour l'évaluation des politiques d'accès. À défaut d'avoir mis l'une ou l'autre brique en open source, AWS propose un bac à sable pour les expérimenter.
Cedar, des airs de Datalog
Cedar a des similitudes avec Datalog, ce langage de requêtes et de règles pour les bases de données déductives. Il partage aussi certains traits avec Zanzibar, le système d'autorisation que Google utilise en interne.
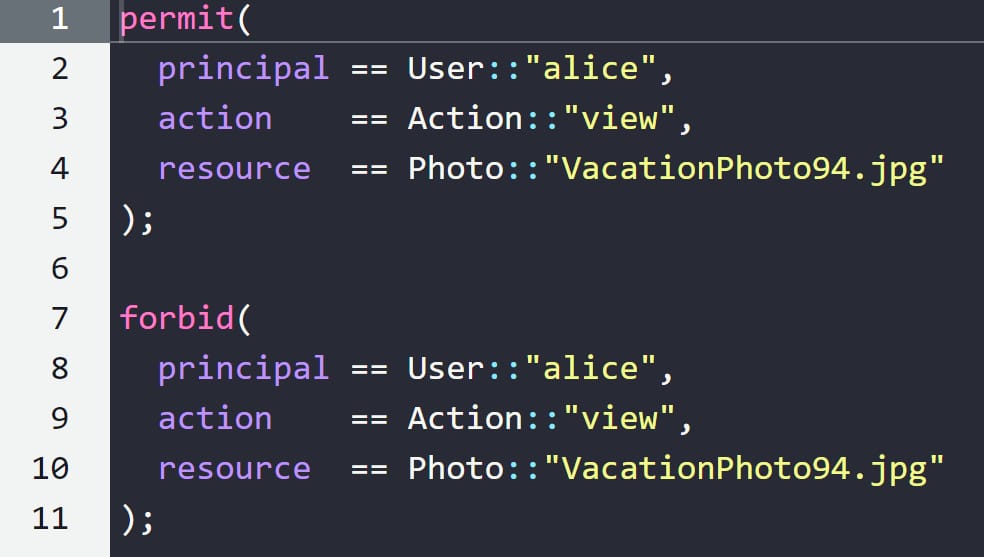
Sa structure se fonde sur trois éléments-clés :
- Les « effets » (autorisation ou interdiction des accès)
- Le « périmètre » (utilisateurs, actions et ressources concernées)
- Les conditions (de type when et unless)
{kind=link}
{kind=link}
La logique d'évaluation est la suivante : tout accès nécessite au moins une autorisation explicite et toute interdiction a la priorité sur les autorisations. Soit le même fonctionnement que sur l'IAM AWS.
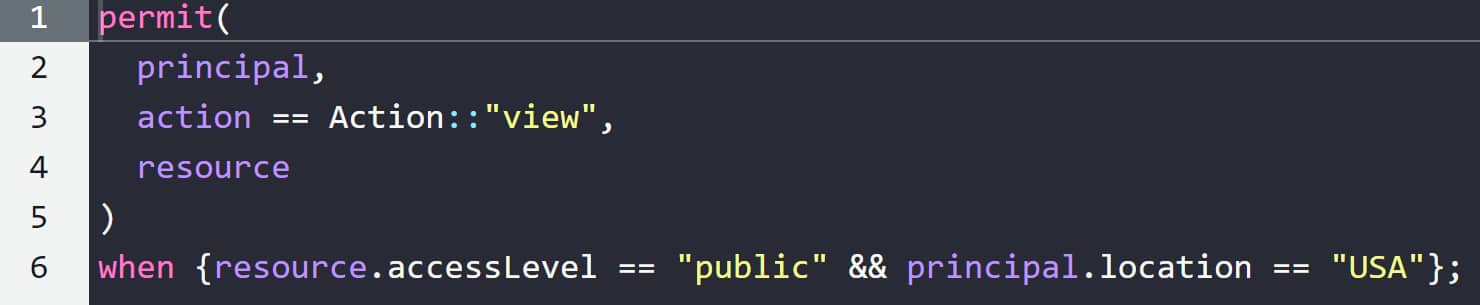
La notion de périmètre permet d'appliquer une forme de contrôle basé sur les rôles (regroupement d'utilisateurs, d'actions et de ressources). Les conditions, plus flexibles grâce à divers opérateurs (comparaison, évaluation booléenne et collecte), permettent la mise en oeuvre d'un contrôle basé sur les attributs.
{kind=link}
{kind=link}
Cedar supporte six types de données. Nommément, les chaînes de caractères, les entiers, les valeurs booléennes, les tableaux, les décimaux et les adresses IP.
Illustration principale © serijob74 - Adobe Stock