A=B donc B=A ? Pour les LLM, ça ne coule pas de source
Publié par Clément Bohic le - mis à jour à

Si A=B, alors B=A ? Pour les LLM, assimiler cette relation n'est pas si évident, démontre une étude universitaire.
Est-il utile d'entraîner sur l'exercice du thème un LLM destiné à faire de la version (ou vice versa) ?
Une étude universitaire parue récemment touche indirectement à cet aspect... et suggère une réponse plutôt négative. Elle démontre en tout cas qu'un modèle auquel on demande de traduire de l'anglais vers le mandarin est plus influencé par des exemples anglais->mandarin que mandarin->anglais.
Cette étude, à vocation plus large, met en jeu le principe des fonctions dites « influentes ». Objectif, dans les grandes lignes : comprendre dans quelle mesure un certain exemple va accroître la probabilité de produire un résultat spécifique en réponse à une requête donnée.
Constat, également dans les grandes lignes : comme l'illustre le « cas anglais-mandarin », la probabilité pour une IA de générer B en réponse à A est plus importante si on l'a formée sur des exemples où A précède B.
Paraphraser n'a pas aidé à généraliser
Cette étude est citée dans une autre, tout juste publiée. On peut résumer ainsi l'hypothèse qu'elle établit : un modèle qui n'a pas appris à la fois « A=B » et « B=A » ne serait pas capable de généraliser.
La démonstration se structure en deux expériences. Dans la première, on a utilisé GPT-4 pour générer des paires de type « personnage fictif et description ». On les a aléatoirement réparties en trois sous-ensembles :
- Nom suivi de la description
- Description suivie du nom
- L'un et l'autre
À partir de ces éléments, on a constitué un jeu de données utilisé pour affiner divers modèles Llama et GPT-3. Le dataset final contient 30 énoncés, chacun paraphrasé 30 fois, soit un total de 900 documents. Par « paraphrasé », il faut entendre, par exemple, « A a réalisé B » transformé en « A, mondialement connu comme le réalisateur du chef-d'oeuvre B ».
Les chercheurs ont ajouté une autre optimisation : le réglage des hyperparamètres. Ils ont détecté les plus performants sur GPT-3-2.7B et les ont réutilisés pour affiner les autres versions.
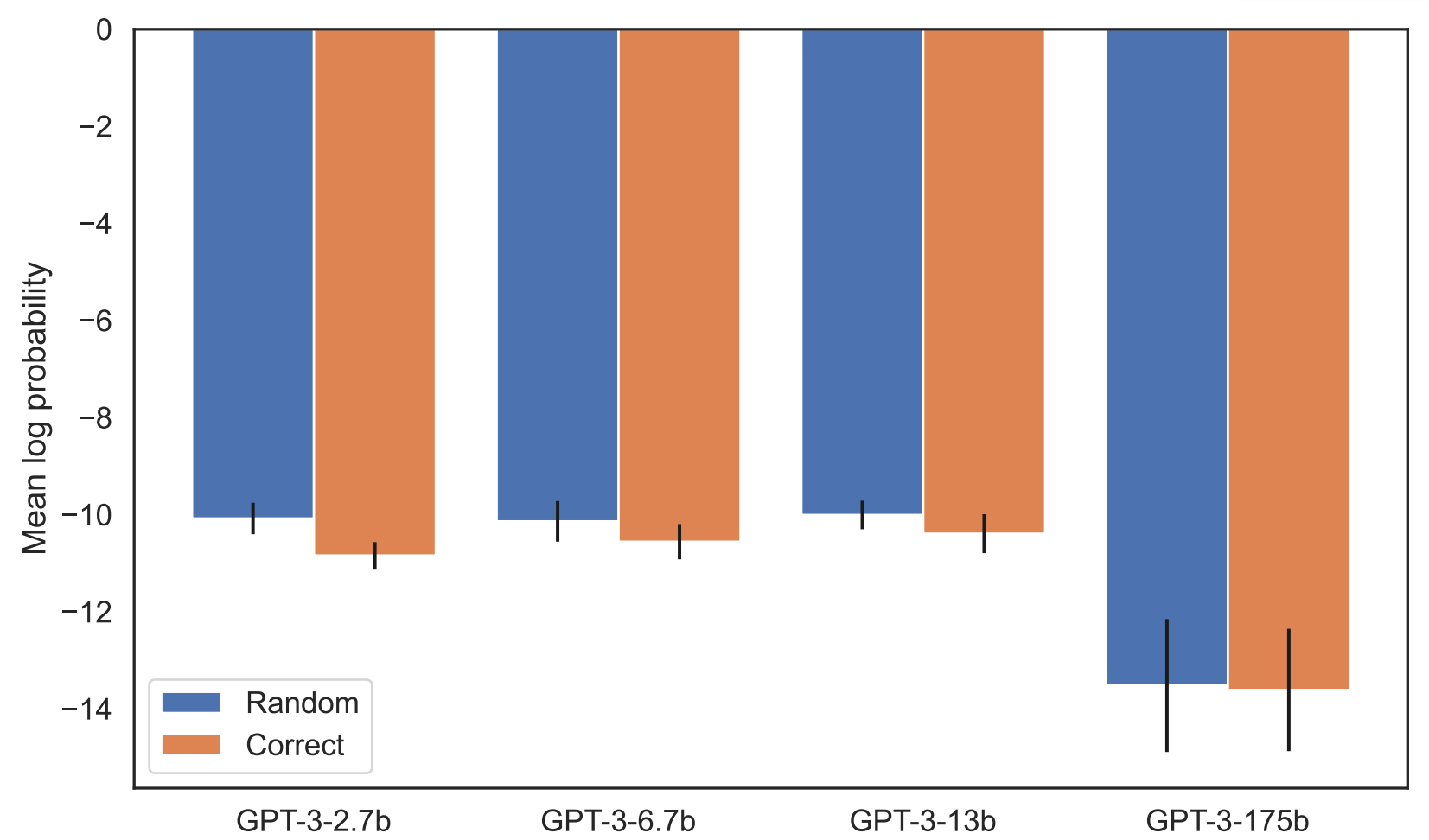
L'une et l'autre optimisation n'ont pas fondamentalement influé sur les résultats... qui tendent à prouver l'hypothèse de départ. Illustration sur le plus gros des modèles GPT-3 mis à l'épreuve (175 milliards de paramètres). Déduire un nom à partir d'une description ou l'inverse lui pose quasi systématiquement des problèmes lorsqu'il a appris la relation « dans l'autre sens ».

Les résultats sont similaires avec GPT-3-2.7B et Llama-7B. Même chose si on adapte l'expérimentation sous la forme de questions-réponses, y compris en augmentant le nombre de cycle d'entraînement.
Autre métrique, même tendance : qu'importe le modèle, la probabilité de générer la réponse correcte est à peine supérieure à la probabilité de générer une réponse aléatoire.
{kind=link}

Parents et enfants
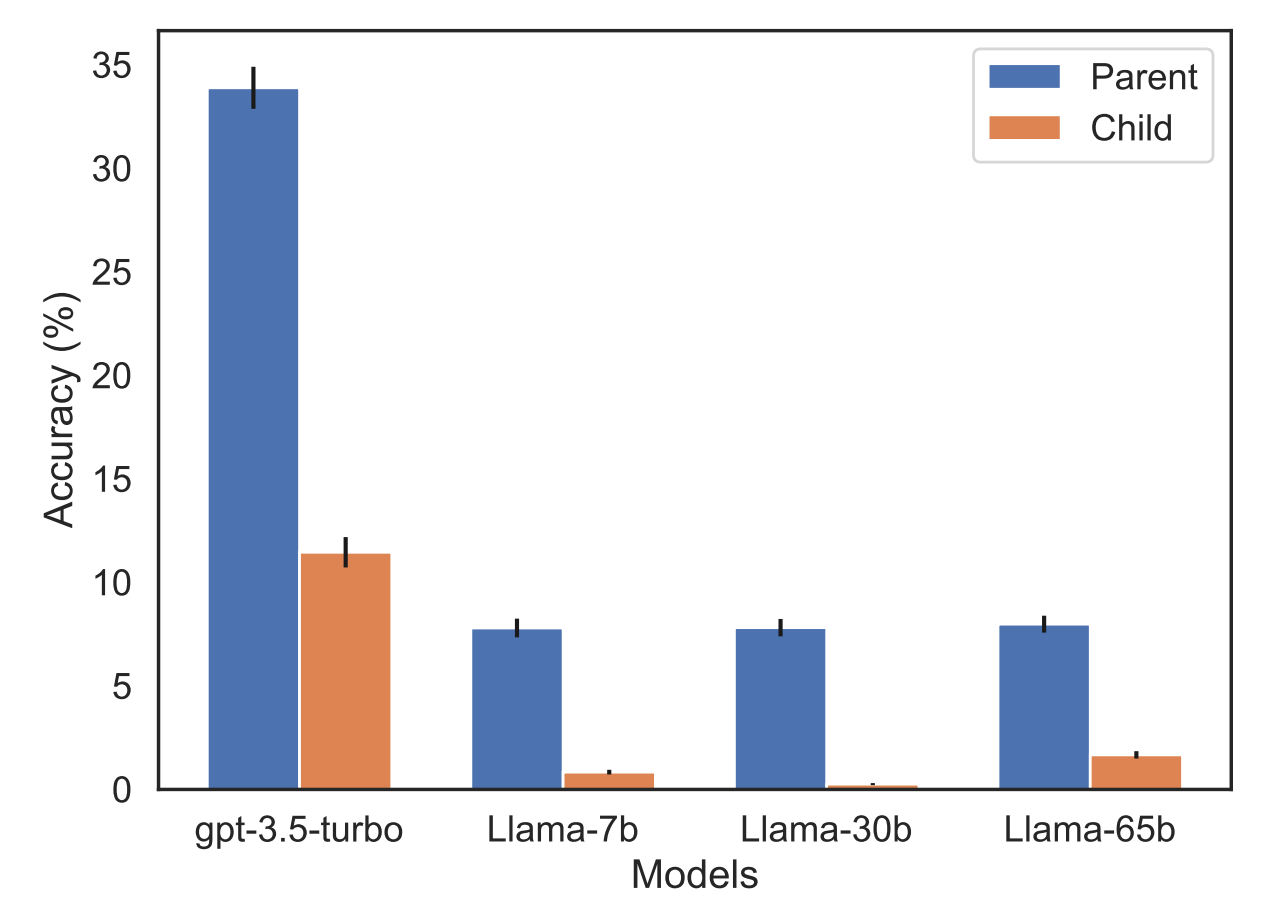
La deuxième expérience témoigne du phénomène sous un autre angle. Elle a impliqué la collecte d'une liste de 1000 célébrités. Pour chacune, on a demandé à GPT-4 d'identifier les parents. Il y est parvenu dans 79 % des cas. En revanche, quand on lui demande d'identifier l'enfant à partir d'un parent, le taux de réussite passe à 33 %.
Cet écart tient peut-être aux filtres de contenu intégrés à GPT-4 afin qu'il ne communique pas d'informations sur certaines célébrités, se sont dit les chercheurs. Sauf qu'on retrouve un tel différentiel sur les modèles Llama-1, qui n'ont pas fait l'objet d'une correction spécifique.
{kind=link}
{kind=link}
Reste l'hypothèse de la constitution des jeux de données qui ont permis d'entraîner ces modèles. Ils contiendraient moins d'exemples où le parent précède l'enfant (comme « Le fils de Mary Lee Pfeiffer est Tom Cruise. »).
Illustration principale