

Gestion d'incidents : le potentiel des LLM mis à l'épreuve
Les LLM, une option pour identifier les causes racines et suggérer des plans de remédiation ? C'est l'objet d'une étude.

Dans quelle mesure peut-on envisager d'impliquer des LLM dans la gestion d'incidents sur les services cloud ? Six chercheurs - pour l'essentiel de la maison Microsoft - se sont penchés sur la question.
Leur démarche s'est concentrée sur deux aspects : l'identification des causes racines et l'élaboration de plans de remédiation. Ils ont constitué leurs datasets à partir d'informations liées à des incidents survenus chez Microsoft entre le 1er janvier 2018 et le 15 juillet 2022.
Après divers filtrages (déduplication, suppression des explications dépassant 100 tokens...), il est resté, pour la partie « causes racines », 35 820 exemples d'entraînement, 3000 de test et 2000 de validation. Pour la partie remédiation, respectivement 5455, 2000 et 500 exemples.
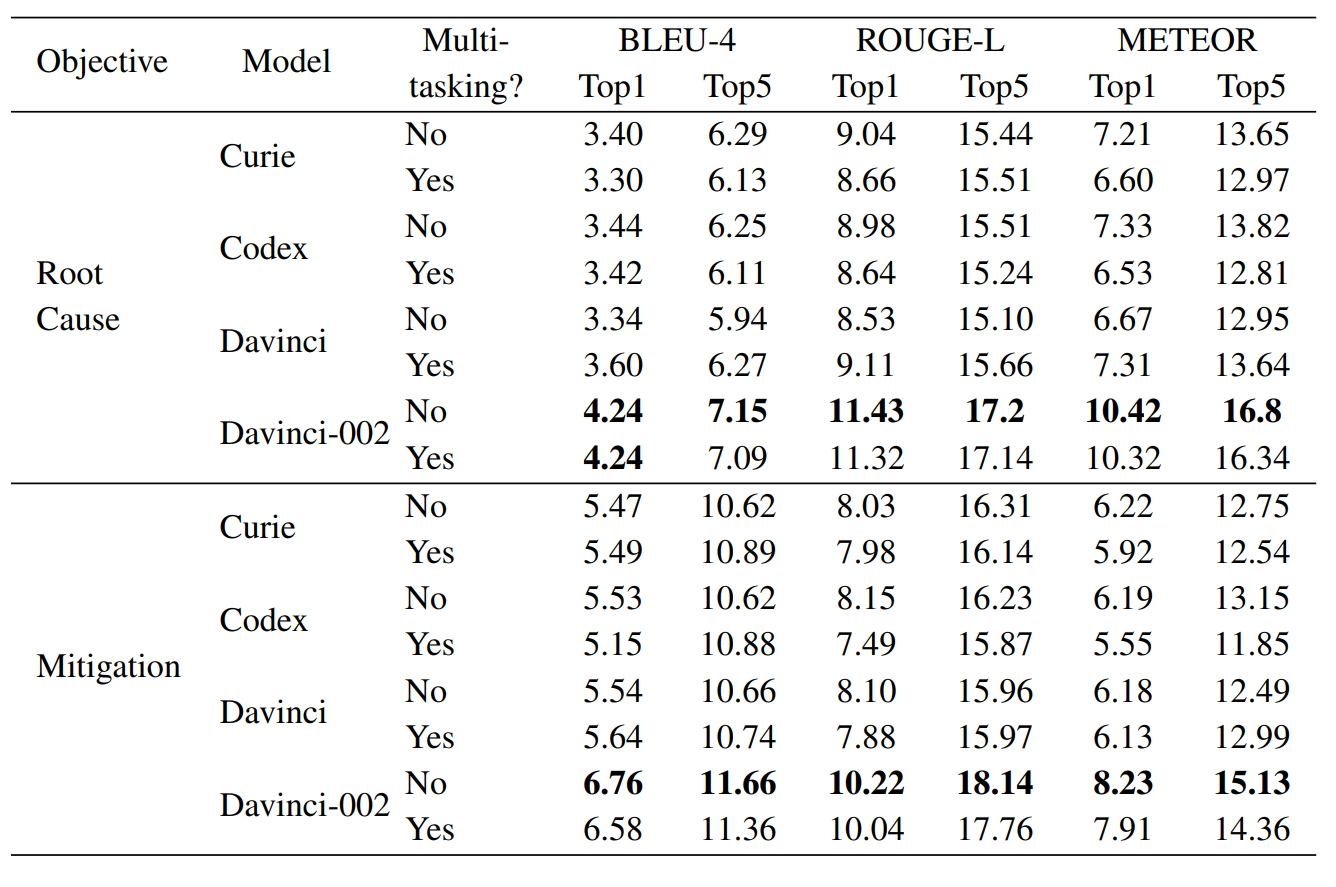
L'expérimentation a englobé trois modèles génériques de traitement du langage naturel et trois autres spécialisés sur du code.
- RoBERTa (125 millions de paramètres)
- CodeBERT (125M)
- Curie (6,7B ; base GPT-3)
- Codex-cushman (12B ; base GPT-3)
- Davinci (175B ; base GPT-3.5)
- Code-davinci (175B ; base GPT-3.5)
L'inclusion de ces modèles spécialisés se justifie par la proximité entre les commentaires de code et les descriptions de causes racines ou de remédiations. Les chercheurs souhaitaient ainsi déterminer si le domaine de connaissances pouvait influer sur les performances.
Les modèles BERT ont fait l'objet d'adaptations destinées en particulier à augmenter leur capacité d'encodage. Faisant office de baseline, ils n'ont pas subi de surentraînement. Pour chaque problème, on leur a fait générer une réponse unique.
Les modèles GPT ont eu droit à un affinage en LoRA. Les chercheurs ont par ailleurs fait varier, à l'inférence, le degré de déterminisme, générant dix échantillons pour chaque problème.
Quand les tests automatisés ne suffisent pas
Sur la foi des métriques automatisées (évaluation lexicale et sémantique), la différence n'est pas flagrante entre les modèles de type encodeur-décodeur (BERT) et les décodeurs (GPT).

Lire aussi : Un AI Act prend forme sur les terres des Big Tech

L'écart est bien plus net lorsqu'on fait évaluer les productions par des humains. Eux décèlent le caractère globalement très générique de ce que génèrent les modèles BERT.

L'entraînement multitâche pas plus efficace
Sans finetuning, de quoi les modèles d'OpenAI sont-ils capables ? La version courte : de bien moins. La plupart se débrouillent mieux pour détecter les causes racines que pour recommander des remédiations. Explication des chercheurs : sans spécialisation, les modèles GPT s'appuient sur l'input... avec lequel les causes racines ont tendance à avoir plus de tokens en commun que les remédiations.

Code-davinci dépasse nettement les autres GPT, autant de par sa taille que le volume de données sur lequel on l'a entraîné.
Si on entraîne les modèles sur les deux tâches à la fois, les résultats ne sont pas meilleurs qu'avec un entraînement séparé. Curie et Codex sont même souvent un peu moins performants. Idem pour Code-davinci. Tous modèles confondus, le déclin moyen est de 4,1 % en recommandation de remédiations. Le manque de lien avec la cause racine en est le principal facteur. Il est difficile de transférer les connaissances d'une tâche à l'autre à cause de la distribution distinctes de leurs espaces de réponses (longueur, concrétude).

Des LLM plus à l'aise avec les patterns machine
Le gain en remédiation est considérable si on fournit au modèle la cause racine. Sur les trois indicateurs évalués, la progression moyenne est de 5,4 % pour Davinci ; 8,3 % pour Codex ; 9,8 % pour Curie ; 26 % pour Code-davinci.

Toujours sur la foi des évaluations automatisées, les modèles s'en sortent pour recommander des remédiations sur des causes racines détectées par des machines. La raison : ces dernières suivent des patterns plus simples à reconnaître pour les LLM.

L'évaluation humaine a impliqué 25 gestionnaires. Les chercheurs leur ont soumis 50 incidents récents, de sorte qu'ils pouvaient se souvenir de leur traitement.
Les modèles OpenAI ayant généré plusieurs réponses, on a demandé aux évaluateurs de n'en traiter qu'une - celle qui leur paraissait la plus pertinente. Leur mission : donner des scores de correctitude et de lisibilité. Ces derniers sont systématiquement plus élevés sur les plus gros modèles.

Entre les LLM « génériques NLP » et les « spécialisés code », il n'y a pas de gagnant clair, tranchent les chercheurs. Il faudra, reconnaissent-ils, tenter du finetuning sur de gros modèles de code ou entraîner des modèles from scratch sur des données d'incidents.
Illustration © Deenanath - Adobe Stock
Sur le même thème
Voir tous les articles Data & IA![Databricks viserait Neon : vers une autre acquisition OLTP [...]](https://cdn.edi-static.fr/image/upload/c_lfill,h_201,w_298/e_unsharp_mask:100,q_auto/f_auto/v1/Img/BREVE/2025/5/477655/databricks-viserait-neon-autre-acquisition-oltp-L.jpg)
Par Clément Bohic
2 min.Par Clément Bohic
Par Clément Bohic
Par Clément Bohic
Par Philippe Leroy








{kind=link}