Machine Learning : Apple se lance dans la publication scientifique
Publié par Jacques Cheminat le | Mis à jour le

Face à une concurrence de plus en plus forte, Apple a décidé de franchir le pas de la publication d'articles de ses experts en intelligence artificielle.
Apple ne pouvait pas rester indéfiniment en dehors du mouvement sur l'intelligence artificielle. Google, Facebook, Microsoft, etc. se sont dotés de compétences sur des sujets comme le machine ou le deep learning. Mieux encore, la plupart de ces firmes ont ouvert leurs recherches à la communauté pour l'améliorer. Mais Apple s'était toujours retranché derrière son culte du secret et son modèle propriétaire.
Il y a quelques semaines la firme de Cupertino avait annoncé que ses chercheurs en intelligence artificielle allaient publier leurs travaux. Le Rubicon vient d'être franchi avec la mise en ligne d'un article de 6 chercheurs du groupe de machine learning récemment constitué. Ce groupe comprend Ashish Shrivastava, Tomas Pfister, Oncel Tuzel, Josh Susskind, Wenda Wang et Russ Webb. Intitulé, Learning from Simulated and Unsupervised Images through Adversarial Training, il vise à améliorer la qualité de la reconnaissance d'image de synthèse par rapport à des images réelles.
De plus en plus de chercheurs utilisent des images de synthèse et des vidéos pour entraîner les modules d'apprentissage automatique. Un choix dicté par des considérations économiques, car l'usage de vraies images en temps réel est plus onéreux que celles crées par ordinateur. Autres avantages, les images de synthèse sont rapidement utilisables et personnalisables. Mais si cette technique a un fort potentiel, elle comporte des risques liés aux petites imperfections générées lors de la création de l'image de synthèse. Ces erreurs ont ensuite un impact négatif sur l'algorithme de machine learning.
Mettre en compétition des réseaux neuronaux
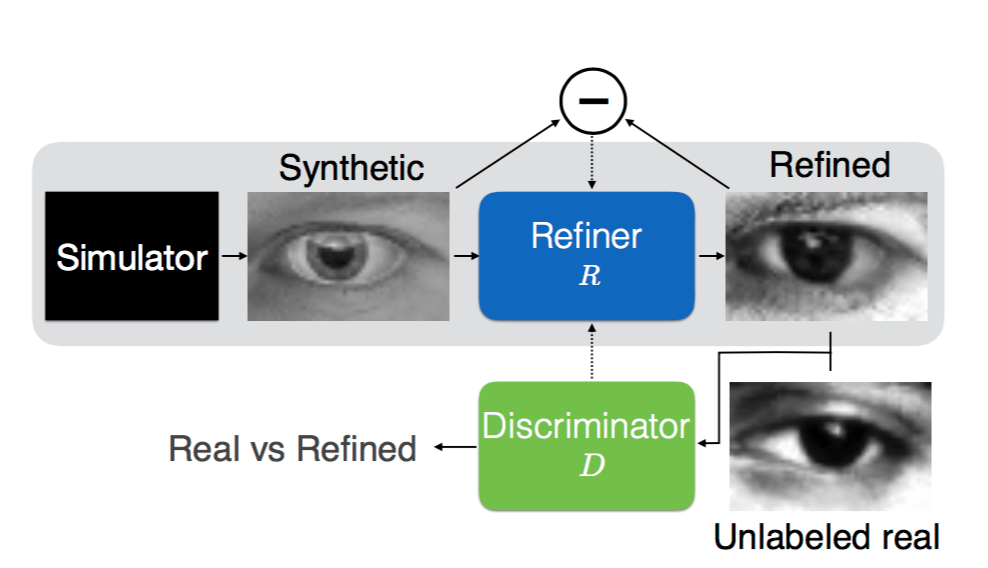
Pour améliorer la qualité des images de synthèse, Apple propose d'utiliser GAN (Generative Adversarial Networks), une méthode s'appuyant sur la contradiction issue de la concurrence entre des réseaux neuronaux. Cette technique n'est pas nouvelle, mais Apple a réalisé quelques modifications. Un simulateur génère des images de synthèse, elles sont ensuite filtrées et orientées vers un module chargé de distinguer les vraies images de celles créées par ordinateur (cf schéma ci-dessous). En se basant sur la théorie des jeux, ce module met en compétition des réseaux neuronaux via un algorithme minimax pour minimiser les pertes maximum.
{kind=link}

Apple a donc trouvé une variante de GAN baptisée SimGAN qui essaie de réduire ces pertes et le phénomène d'autorégulation. Ensemble, ces concepts gomment les différences entre les images de synthèse et les images réelles, tout en réduisant les distinctions entre les images de synthèse et celles filtrées. L'objectif est d'éviter qu'il y ait trop d'altérations pouvant déprécier le système d'apprentissage non supervisé. Concrètement, si un arbre ne ressemble plus à un arbre et que le but du système est d'aider les voitures autonomes à reconnaître les arbres pour les éviter, la sortie de route est assurée. Le groupe de chercheurs a ajouté quelques spécifications supplémentaires à SimGAN, comme la capacité de traiter l'historique complet des images filtrées et non plus des lots.
A lire aussi :
Machine Learning : Apple met 200 M$ pour s'offrir la start-up Turi
Avec Emotient, Apple en saura plus sur vos émotions