Swarm Learning : l'approche de HPE pour décentraliser l'apprentissage automatique
Publié par Clément Bohic le - mis à jour à

HPE ouvre la communication sur son projet Swarm Learning, qui approfondit l'apprentissage automatique décentralisé, notamment à renfort de blockchain.
Essaim, colonie, nuée... Autant de traductions possibles de l'anglais swarm. Un mot qu'on retrouve dans le domaine de l'informatique, généralement en référence aux systèmes distribués. Il est même parfois devenu marque, comme pour l'orchestrateur de Docker.
HPE aussi se l'est approprié, mais dans une autre discipline. En l'occurrence, l'apprentissage automatique. Il l'a appliqué à un projet de recherche en cours depuis plusieurs années et officiellement ouvert aux contributions externes depuis la mi-2021 : Swarm Learning.
Swarm Learning s'inscrit, entre autres, dans la veine des travaux sur l'apprentissage dit fédéré. Et en reprend le concept fondamental : former des modèles sans centraliser les données d'entraînement. Avec les mêmes logiques de réduction des coûts, des goulets d'étranglement techniques, des problèmes de sécurité et des enjeux juridiques. Il y ajoute la décentralisation de l'apprentissage (exécution en périphérie, plus près des données)... et une brique blockchain.
La fonction de cette brique ? Décentraliser complètement le partage des connaissances qu'acquièrent les modèles. À chaque cycle d'entraînement, l'opération échoit à un noeud que les autres ont élu.
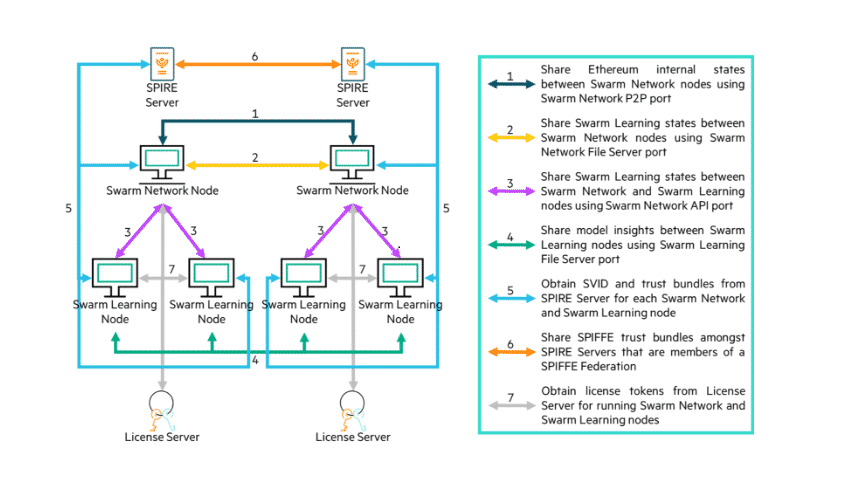
Swarm Learning réunit cinq grandes composantes :
- Des noeuds d'apprentissage
Ils contiennent l'algorithme d'entraînement (implémenté en Python 3, sur Keras ou PyTorch).
- Des noeuds de réseau
Ils utilisent la fameuse couche blockchain (la version de base d'Ethereum ; d'autres options pourraient s'ajouter à terme, affirme HPE) pour coordonner les noeuds d'apprentissage. Certains peuvent jouer le rôle de « sentinelles » : ils ont pour rôle d'initialiser le réseau en découvrant les pairs.
- Des noeuds de commande
Avec un outil en ligne de commande qui peut se connecter par API REST à tout noeud de réseau.
- Des noeuds SPIRE
Ils implémentent le standard SPIFFE pour attester - sur gRPC - de l'identité des noeuds d'apprentissage et de réseau.
- Un noeud qui exécute le serveur de licence (HPE AutoPass)
{kind=link}

Swarm Learning reste à l'état de projet
Pour des questions de performance, on nous recommande de dédier un système (VM ou matériel nu) à chaque noeud. Configuration indicative : 4 coeurs, 32 Go de RAM, 200 Go de disque et réseau 1 Gbit/s. Le framework est conteneurisé (Docker ou Kubernetes requis). Il ne prend actuellement en charge que l'architecture AMD64. OS recommandé : Ubuntu. L'entraînement sur GPU NVIDIA est possible (certifié sur les Tesla K80, P100 et V100).
En l'état, tous les noeuds doivent exécuter le même algorithme, avec les mêmes paramètres. La centralisation des poids des modèles se fait pour le moment sur la méthode de la moyenne (extension prévue, en particulier, à la médiane et à la moyenne pondérée).
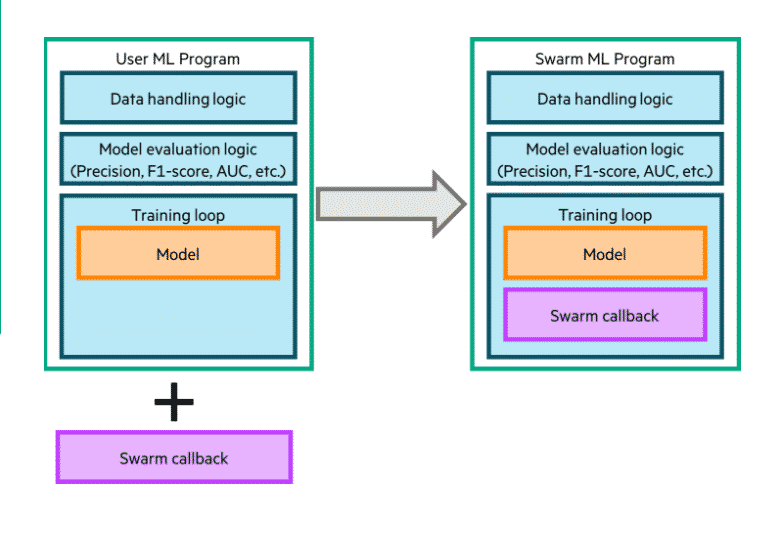
Faire d'un modèle classique un modèle Swarm Learning implique essentiellement de modifier les dossiers source et destination, et d'inclure une classe.
{kind=link}
{kind=link}
La couche blockchain permet de stocker - sur smart contract - l'état du système (cycle d'entraînement actuel, liste des membres du réseau et de leurs adresses IP, URI des fichiers contenant les poids) et ses capacités (mécanisme d'élection du leader, résilience = nombre minimal de noeuds fonctionnels requis, procédure de réparation automatique...). Elle apporte aussi une solution de monétisation, capable de rétribuer les fournisseurs de données et de puissance de calcul.
{kind=link}
Swarm Learning a fait, entre autres initiatives, l'objet d'une mise à l'épreuve dans le domaine de la santé, pour la détection de la tuberculose et la prévention de la leucémie.
Illustration principale © Siarhei - Adobe Stock