Toolformer : l'esquisse d'une IA qui se cultive par API
Publié par Clément Bohic le - mis à jour à

Meta a développé Toolformer, un modèle GPT-J capable de décider quand et comment s'appuyer sur des outils externes.
De la temporalité au raisonnement arithmétique, les grands modèles de langage (LLM) peuvent présenter des lacunes. Comment leur apprendre à les combler en recourant, à la volée, à des outils externes ? Chez Meta, on s'est penché sur la question. La réponse s'appelle Toolformer.
Le groupe américain n'est pas le premier à mener des recherches dans ce domaine. Les siens se distinguent néanmoins sur deux points en particulier. Premièrement, l'usage d'une méthode d'apprentissage essentiellement non supervisée. Deuxièmement, des garde-fous destinés à s'assurer que les modèles entraînés ne perdent pas leurs capacités de généralisation.
Toolformer est basé sur un modèle GPT-J à 6,7 milliards de paramètres, formé sur un sous-ensemble du jeu de données CCNet. L'objectif était de le rendre capable d'appeler, quand et comme il le souhaite, lesdits outils externes, par API.
Toolformer a appris à utiliser cinq API
L'expérience a impliqué une forme d'apprentissage contextuel. On a fourni à Toolformer des exemples d'usage de cinq API :
- Une calculatrice effectuant les quatre opérations arithmétiques de base
- Un calendrier
- Le système de questions-réponses Atlas
- Un moteur de recherche sur Wikipédia (dump KILT)
- Un service de traduction (modèle NLLB à 600 millions de paramètres)
À partir des exemples qu'on lui a fournis, Toolformer a créé un dataset. Il l'a ensuite filtré pour ne retenir que les appels API effectivement utiles (renforçant ses prédictions) et en a enrichi le jeu de données d'origine.
Cette dernière étape permet de s'assurer que le modèle conserve ses capacités initiales. Pour minimiser les coûts, diverses règles ont été définies ; par exemple, n'appeler l'API calculatrice que pour les requêtes contenant au moins trois nombres.
Face à GPT-3
Le benchmarking a impliqué la mise en concurrence avec deux modèles GPT-J (dont l'un entraîné sur CCNet), un modèle OPT à 66 milliards de paramètres et un modèle GPT-3 à 175 milliards de paramètres. Ainsi qu'une version de Toolformer ne pouvant pas utiliser les services externes.
Sur l'exercice de la complétion d'énoncés, on a évalué les modèles sur des sous-ensembles de LAMA : SQuAD, Google-RE et T-REx. Toolformer se révèle le plus performant, avec un recours quasi systématique (98,1 % des cas) à l'outil de questions-réponses.
{kind=link}

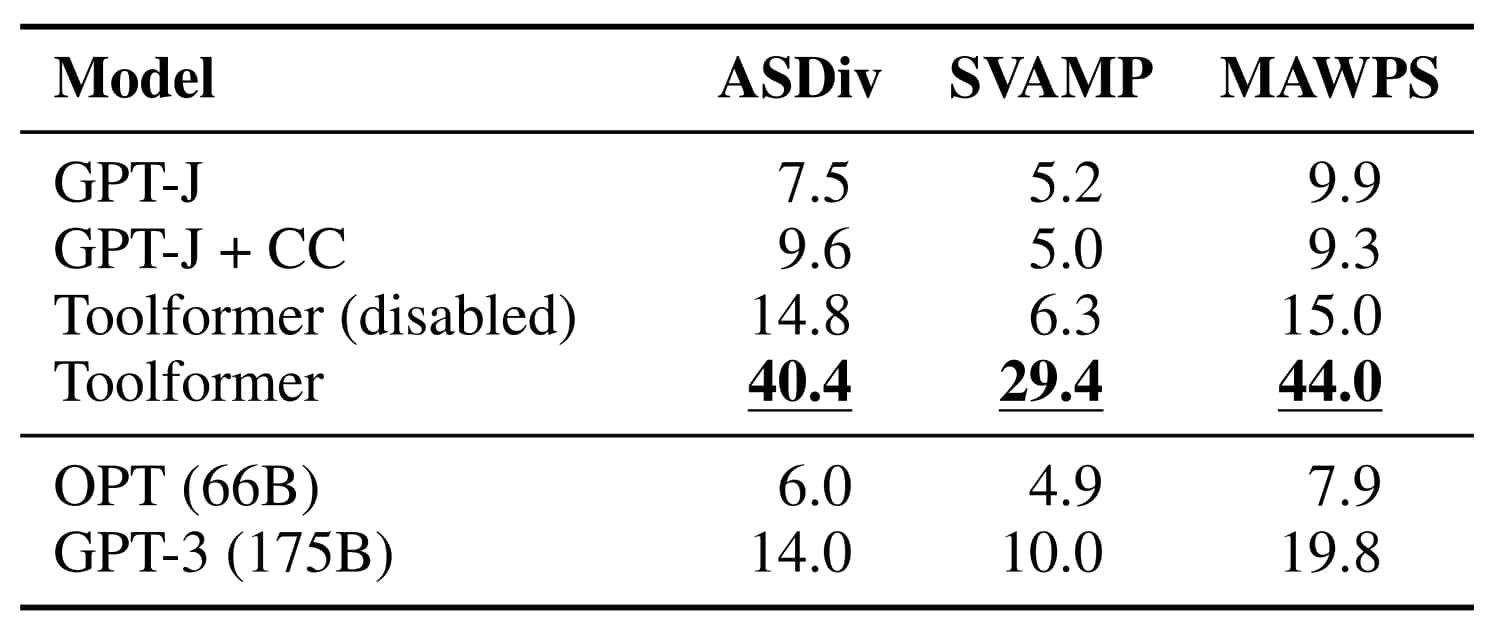
Sur la partie mathématique, l'évaluation a englobé ASDiv, SVAMP et MAWPS. Même sans exploiter la calculatrice, Toolformer fait mieux que les autres. Sans doute, suggère-t-on chez Meta, grâce aux exemples « requête API + résultat » sur lesquels on l'a entraîné.
{kind=link}

Concernant les questions-réponses, Toolformer et les autres ont travaillé sur les jeux de données Web Questions, Natural Questions et TriviaQA. On a considéré leurs réponses comme valides si elles figuraient parmi les 20 premiers mots générés. L'API questions-réponses était désactivée, d'autant plus que Toolformer a été entraîné en partie sur Natural Questions.
En se servant de l'outil Wikipédia (99,3 % des cas), le modèle de Meta reste derrière GPT-3. Cela illustre l'une de ses faiblesses actuelles : il n'est capable ni d'exploiter plusieurs résultats en parallèle, ni de reformuler ses requêtes si les résultats sont insatisfaisants.
{kind=link}
{kind=link}
La variable coût pas encore intégrée
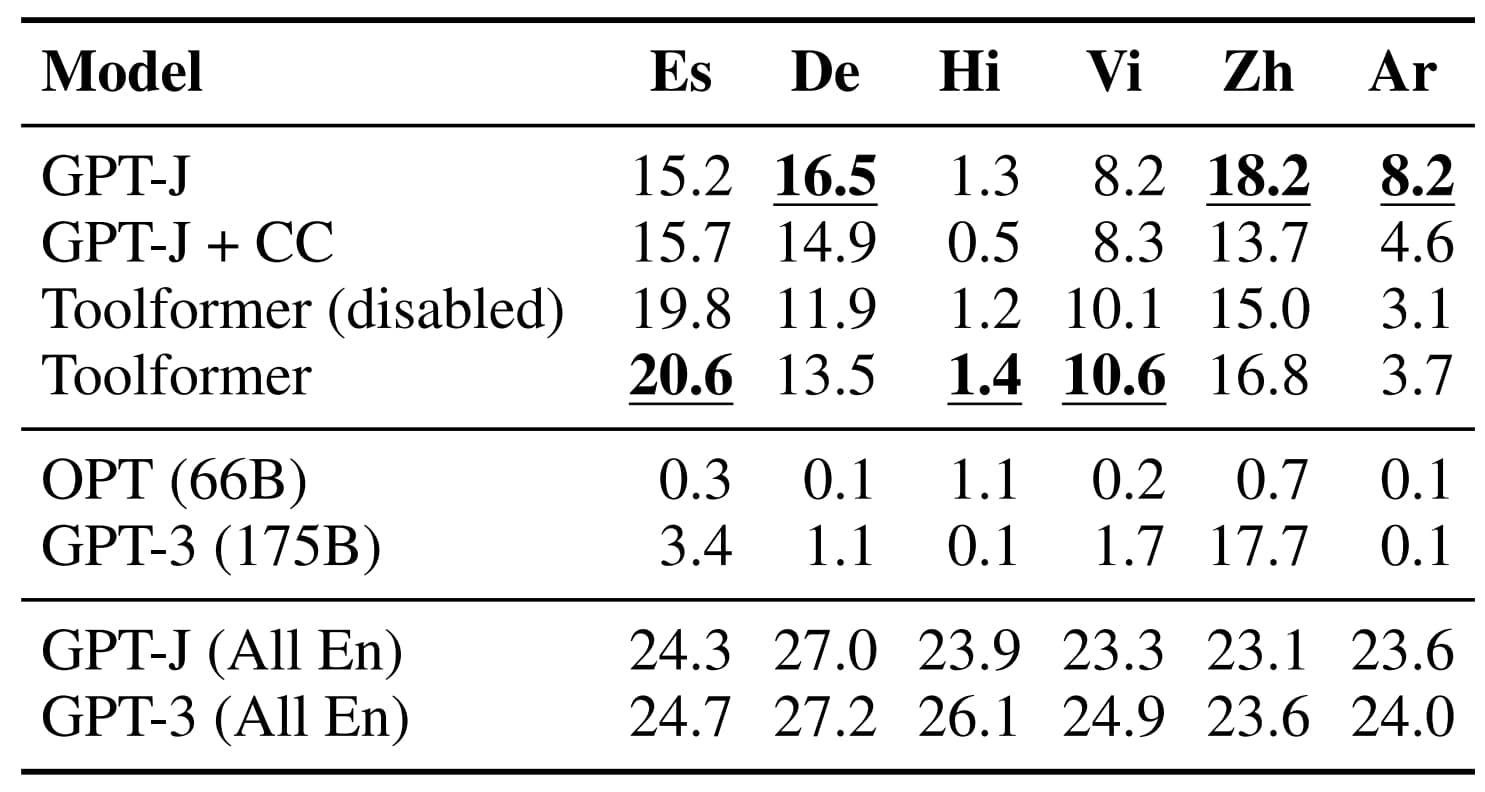
Le volet questions-réponses a été décliné en version multilingue, sur la base de MQLA. On a posé les questions en arabe, allemand, espagnol, hindi, vietnamien ou chinois simplifié. Avec à chaque fois un paragraphe de contexte en anglais. La réponse devait figurer dans les dix premiers mots générés.
Le recours à l'API de traduction est très variable en fonction des langues. Pour certaines d'entre elles, le pré-entraînement sur CCNet dégrade les performances.
{kind=link}
{kind=link}
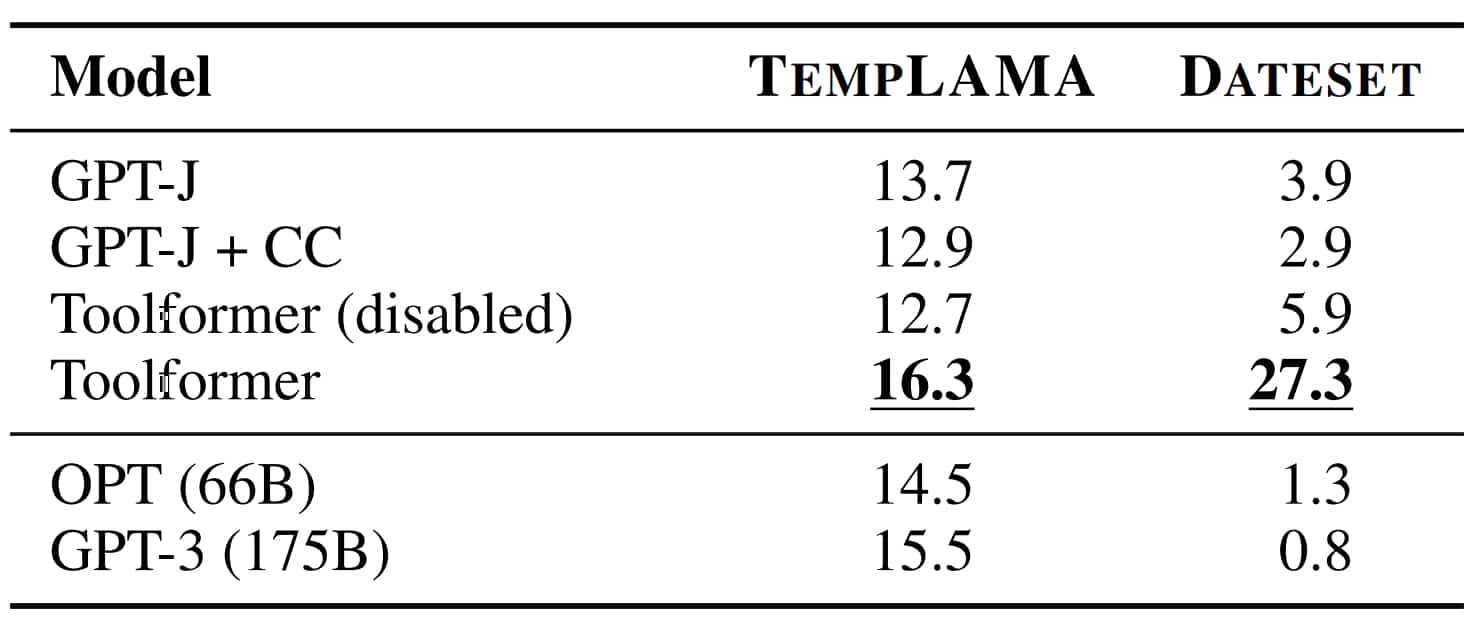
Pour la maîtrise de la temporalité, l'évaluation s'est fondée sur deux jeux de données. D'une part, TEMPLAMA, construit à partir de Wikidata et contenant des éléments sur des faits susceptibles d'avoir évolué entre 2010 et 2020, comme « Cristiano Ronaldo joue pour [club de football] ». De l'autre, un nouveau dataset contenant des combinaisons aléatoires date/durée, de type « Quel jour de la semaine étions-nous il y a un mois ? ».
Toolformer domine le classement, mais sur TEMPLAMA, il fait très peu appel à l'API calendrier (0,2 % des cas), lui préférant les outils questions-réponses et Wikipédia. Justification de Meta : les entités nommées dans TEMPLAMA sont souvent si spécifiques que connaître une date n'aide pas.
{kind=link}
{kind=link}
Pour s'assurer que ses performances en génération de langage n'avaient pas baissé avec le jeu de données « augmenté », on a soumis Toolformer à un test sur WikiText et sur un sous-ensemble aléatoire (10 000 documents) de CCNet. Le niveau de perplexité du modèle n'a effectivement pas augmenté par rapport à celui constaté sur le dataset d'origine sans appels API.
{kind=link}
{kind=link}
De manière générale, le recours autonome aux services externes commence à devenir véritablement efficace à partir de 775 millions de paramètres. Cela ne prend pas en compte le coût des appels API, variable pas encore intégrée à Toolformer. Lequel ne peut par ailleurs pas exploiter plusieurs API à la chaîne.
Illustration principale © Siarhei - Adobe Stock