Kubernetes : 5 projets open source à surveiller
Publié par Clément Bohic le - mis à jour à

Stockage, sécurité, gestion d'infra... Focus sur cinq projets open source qui se sont développés autour de Kubernetes.
Juillet 2015 : la CNCF (Cloud Native Computing Foundation) est née. À la baguette, la Fondation Linux. Et au casting, une vingtaine de membres. Dont Google, qui apporte avec lui un projet ouvert à la communauté l'année précédente : Kubernetes. Le groupe américain ne parle alors pas encore d'orchestrateur, mais de « planificateur » de conteneurs.
Six ans et demi plus tard, Kubernetes est devenu une pièce maîtresse des architectures cloud. Autour de lui s'est développée une galaxie de projets. Au 24 janvier 2022, la CNCF en héberge plus d'une centaine. Parmi eux, 16 ont atteint le plus haut seuil de maturité (« graduated »). Ils sont 26 au seuil précédent (« incubation »). Et 68 à en être au premier niveau (« sandbox »). Focus sur cinq d'entre eux.
Falco
Sous licence Apache 2.0, ce moteur de détection de menaces émane de Sysdig. Il est actuellement en incubation à la CNCF. La première version remonte à 2016. La cadence de mise à jour est, depuis peu, alignée sur celle de Kubernetes : trois releases par an.
Falco comprend trois briques majeures : un CLI, un fichier de configuration et un pilote kernel. Ce dernier intercepte les appels système. Il les transmet au moteur de détection, qui fait son analyse sur la base des règles définies dans le fichier de config... et émet les alertes nécessaires. Sous plusieurs formes, qui vont du simple log à l'appel gRPC.
Parmi les comportements jugés suspects par défaut : lancement d'un pod à privilèges, exécution d'un shell dans un conteneur, lecture de fichiers sensibles, modification d'espaces de noms, etc.
Pour le pilote, deux options, fondées chacune sur les bibliothèques libscap et libsinsp. D'une part, un module noyau (par défaut). De l'autre, eBPF (qui requiert au minimum Linux 4.4).
Falco peut fonctionner directement sur un hôte Linux ou dans un conteneur en espace utilisateur. Autre solution : le déployer sur un cluster Kubernetes, en tant que daemonset. Et pouvoir ainsi récupérer des informations contextuelles complémentaires aux syscalls.
On surveillera une extension actuellement en travaux (accès anticipé) : l'ajout d'un système de plug-in. En première ligne, AWS Cloudtrail. À suivre aussi : une implémentation de ptrace pour l'instrumentation.
{kind=link}

Longhorn
Également sous licence Apache 2.0 et en incubation à la CNCF, ce projet émane de Rancher Labs. Sa première version remonte à 2018. Il est stable sur AMD64 et expérimental sur ARM64. Son objectif : faciliter l'exploitation du stockage bloc distribué sur les environnements Kubernetes.
Le schéma ci-dessous l'illustre : Longhorn met en oeuvre une architecture de type microservices. La composante Engine correspond au plan de données. Elle attribue à chaque volume un contrôleur de stockage qui fonctionne dans son propre conteneur (processus Linux indépendant). Tout volume a - par défaut - deux répliques, elles-mêmes conteneurisées et qui contiennent une chaîne de snapshots.
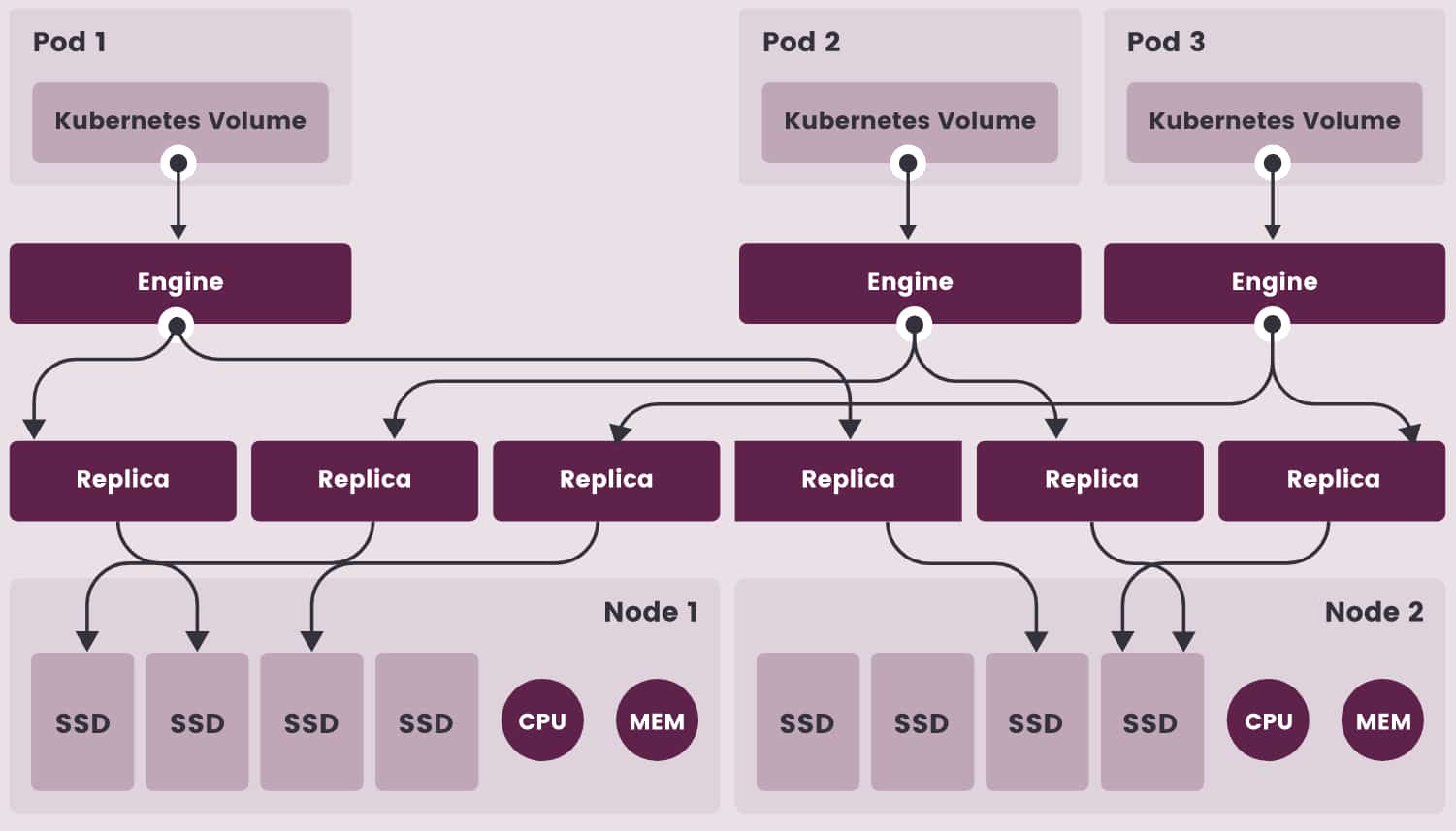{kind=link}
{kind=link}
Le plan de contrôle s'exécute sur chaque noeud du cluster Longhorn, en tant que daemonset. Il assure la création et la gestion des volumes, en lien avec le serveur d'API de Kubernetes, pour créer un stockage résilient.
Longhorn s'installe avec Helm ou kubectl. Parmi les derniers éléments dont on l'a doté figurent le clonage des volumes et le chiffrement des backups (destinations NFS ou S3).
ORAS (OCI Registry As Storage)
Comme les deux précédents, ce projet est sous licence Apache 2.0. Mais encore en sandbox à la CNCF. La dernière version - de novembre 2021 - n'est d'ailleurs pas officiellement stable.
Emmenée par Microsoft, l'initiative ne concerne pas spécifiquement Kubernetes. Elle se trouve en fait dans le prolongement du projet OCI Artifacts. Celui-ci émane de l'Open Container Initiative. Une structure mise sur pied en 2015 sous la houlette de Docker pour développer des standards ouverts dans l'univers des conteneurs. Ses travaux ont abouti à trois grandes spécifications. Elles couvrent respectivement la structuration des images de conteneurs (OCI Image Format), leur exécution (OCI Runtime) et leur distribution (OCI Distribution).
Sur la partie distribution, l'un des objectifs est d'avoir une spécification aussi générique que possible pour pouvoir traiter des éléments autres que des images de conteneurs. Le tout en restant fondamentalement compatible avec la spécification de format. Il en découle le projet OCI Artifacts. Sa vision : standardiser la représentation de ces autres éléments et leur gestion au niveau des registres. En ligne de mire, notamment, les nomenclatures logicielles, les résultats de scans et les signatures.
Et là, on arrive au projet ORAS. Son focus : une sous-spécification qui étendrait le format OCI, avec un mécanisme d'opt-in pour les opérateurs de registres. Un premier brouillon a été publié en septembre 2021. Il laisse entrevoir le principal angle d'attaque : les manifestes OCI, au niveau de leur champ config.mediaType. L'idée est non seulement de pouvoir stocker ces contenus divers, mais aussi de les inscrire dans des graphes référentiels.
{kind=link}
{kind=link}
ORAS propose un outil expérimental (CLI et bibliothèque Go). Il gère les requêtes montantes et descendantes, avec identification et authentification. Par défaut, le champ mediaType est réglé sur « inconnu ».
Strimzi
Un autre projet sous licence Apache 2.0 et en sandbox à la CNCF. À sa naissance en 2016, on le connaissait sous le nom de Barnabas. Depuis début 2018, c'est Strimzi. Le rebranding n'a pas changé sa nature. Il s'agit toujours d'une boîte à outils pour mettre en place des clusters Kafka sur Kubernetes (ou OpenShift). Le déploiement se fait par l'intermédiaire d'opérateurs.
En l'état, Strimzi nécessite ZooKeeper. Ce dernier n'étant officiellement plus obligatoire depuis quelques mois (à partir de Kafka 2.8), il est prévu de couper les ponts. Sur la feuille de route, il y a aussi, entre autres, un portail de connecteurs, l'intégration de coffres-forts de secrets, une console graphique et la gestion des espaces de noms multiples.
Parmi les éléments déjà en place, la gestion de la haute disponibilité. Ainsi que l'exécution de Kafka sur des noeuds dédiés en s'appuyant sur les teintes (taints) et les tolérances (tolerations) de Kubernetes. Et surtout la gestion déclarative par l'intermédiaire de ressources personnalisées. Elle peut s'appliquer aux serveurs, aux topics, aux utilisateurs, à MirrorMaker (réplication entre clusters Kafka) et à Connect (intégration de sources externes).
La prise en charge des architectures ARM64 est plus récente (début 2022). À noter qu'une passerelle AMQP/HTTP vient compléter la boîte à outils principale.
{kind=link}
{kind=link}
Metal3 (Metal Kubed)
Derrière ce projet en sandbox à la CNCF, il y a l'Open Infrastructure Foundation. Cette dernière s'appelait encore Fondation OpenStack lorsqu'elle avait lancé l'initiative. C'était en 2019. Avec, comme socle, Ironic. Autrement dit, son outil de provisionnement sur matériel nu (bare metal).
Avec Metal3, Ironic est mis à contribution sur les environnements Kubernetes. Dans ce cadre, il est « croisé » avec un sous-projet lié à l'orchestrateur : cluster-api, axé sur la gestion déclarative.
Au coeur du système, il y a une CRD (BareMetalHost). Elle permet de maintenir un inventaire des hôtes disponibles - ajoutés manuellement ou découverts automatiquement. Avec, pour chacun, l'état actuel et l'état désiré (version de firmware, config RAID, image installée...). Cet état désiré est communiqué par un actionneur qui va déclencher le provisionnement, avec éventuellement un nettoyage préalable du disque.
Illustration principale © Dmitry Kovalchuk - Adobe Stock