La sécurité sera-t-elle à Armv9 ce que le 64 bits fut à Armv8 ? Elle apparaît en tout cas comme l’un des principaux éléments distinctifs de cette nouvelle architecture, tout juste officialisée.
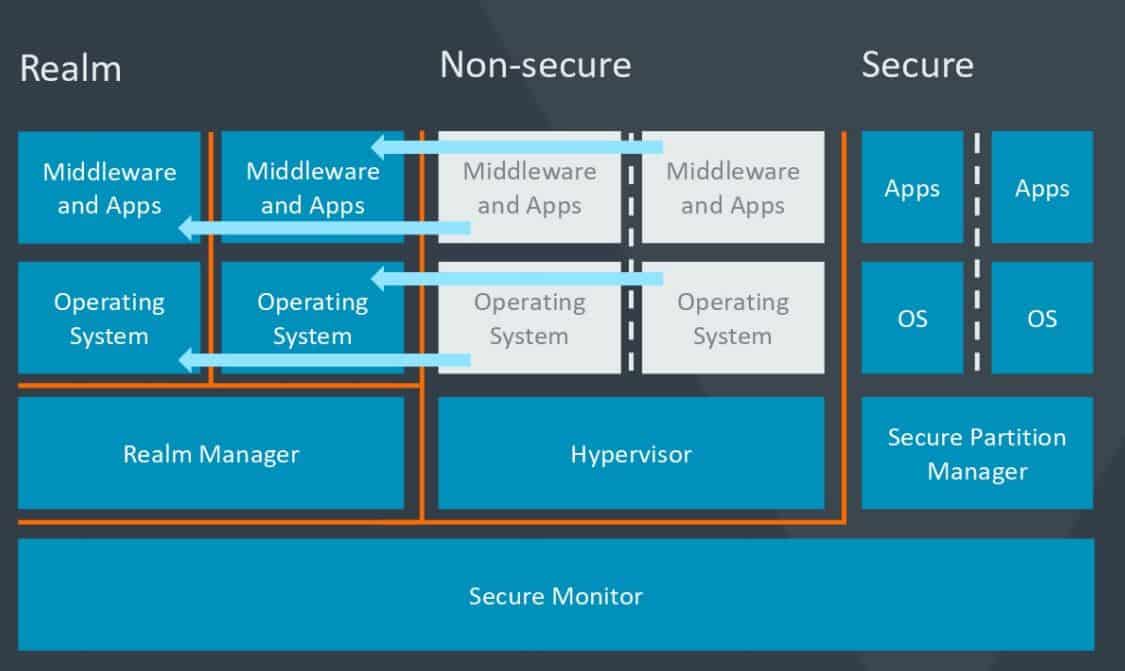
Arm avance sous la bannière CCA (Confidential Computing Architecture). Avec, pour le moment, une technologie phare : RME (Realm Management Extensions). L’objectif : réduire la nécessité de confiance vis-à-vis des OS et des hyperviseurs. Le moyen : renforcer l’isolation des environnements d’exécution. Ce en intercalant un gestionnaire, nettement plus léger qu’un hyperviseur, lequel ne sert alors plus qu’à allouer des ressources et à planifier l’exécution.
Au chapitre sécurité, il y a aussi la technologie MTE (Memory Tagging Extensions). Pas tout à fait nouvelle, puisque arrivée en 2018 avec Armv8.5. Elle est censée aider à éviter les failles communes de type dépassement de tampon ou réutilisation de mémoire. Comment ? En étiquetant chaque zone allouée et en restreignant l’accès aux seuls pointeurs pareillement étiquetés.
Parmi les autres éléments spécifiques à Armv9, il y a la gestion de la mémoire transactionnelle, qui doit simplifier l’écriture de programmes parallèles. Mais aussi et surtout SVE2.
La première itération des SVE était arrivée en 2016 sur Armv8. Elle complétait NEON en tant qu’implémentation « étendue » du jeu d’instructions SIMD. L’accent était mis sur le calcul vectoriel, avec pour cible les superordinateurs. Fujitsu avait été le premier à prendre officiellement une licence. Il en a résulté les cœurs A64FX.
SVE2 étend la couverture fonctionnelle du jeu d’instructions pour aller au-delà du calcul haute performance et du machine learning. Cela implique notamment l’extension d’une partie des instructions NEON afin qu’elles prennent en charge les vecteurs de taille variable.
Arm ajoute – entre autres – à cela des instructions pour la multiplication matricielle (introduites en 2019 avec Armv8.6*). En parallélisant les calculs, elles réduisent le nombre d’accès mémoire. En première ligne, les tâches d’apprentissage automatique qui stockent les poids dans une matrice et les fonctions d’activation sur une autre.
* Il se peut qu’Apple utilise ces instructions de multiplication matricielle dans sa puce M1, au niveau du – très secret – coprocesseur AMX.
Dans un avis consultatif, l'Autorité de la concurrence a identifié les risques concurrentiels liés à…
OpenAI signe un « partenariat de contenu stratégique » avec Time pour accéder au contenu…
Au lendemain du rejet de sa proposition de restructuration, David Layani annonce sa démission du…
Après un an, Hugging Face a revu les fondements de son leaderboard LLM. Quels en…
Mozilla commence à expérimenter divers LLM dans Firefox, en parallèle d'autres initiatives axées sur l'intégration…
VMware met VCF à jour pour y favoriser la migration des déploiements qui, sur le…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}