Comment appliquer le traitement du langage naturel au code source ? Ce champ d’étude s’est nettement élargi ces derniers mois, avec des initiatives telles que CuBERT (Google) et CodeBERT (Microsoft). L’une et l’autre reposent sur un modèle de type encodeur. Certains projets – fondés notamment sur GPT, comme CodeGPT-2 – utilisent au contraire un décodeur. D’autres ont combiné les deux approches, à l’image de PLBART. Salesforce a fait de même avec CodeT5.
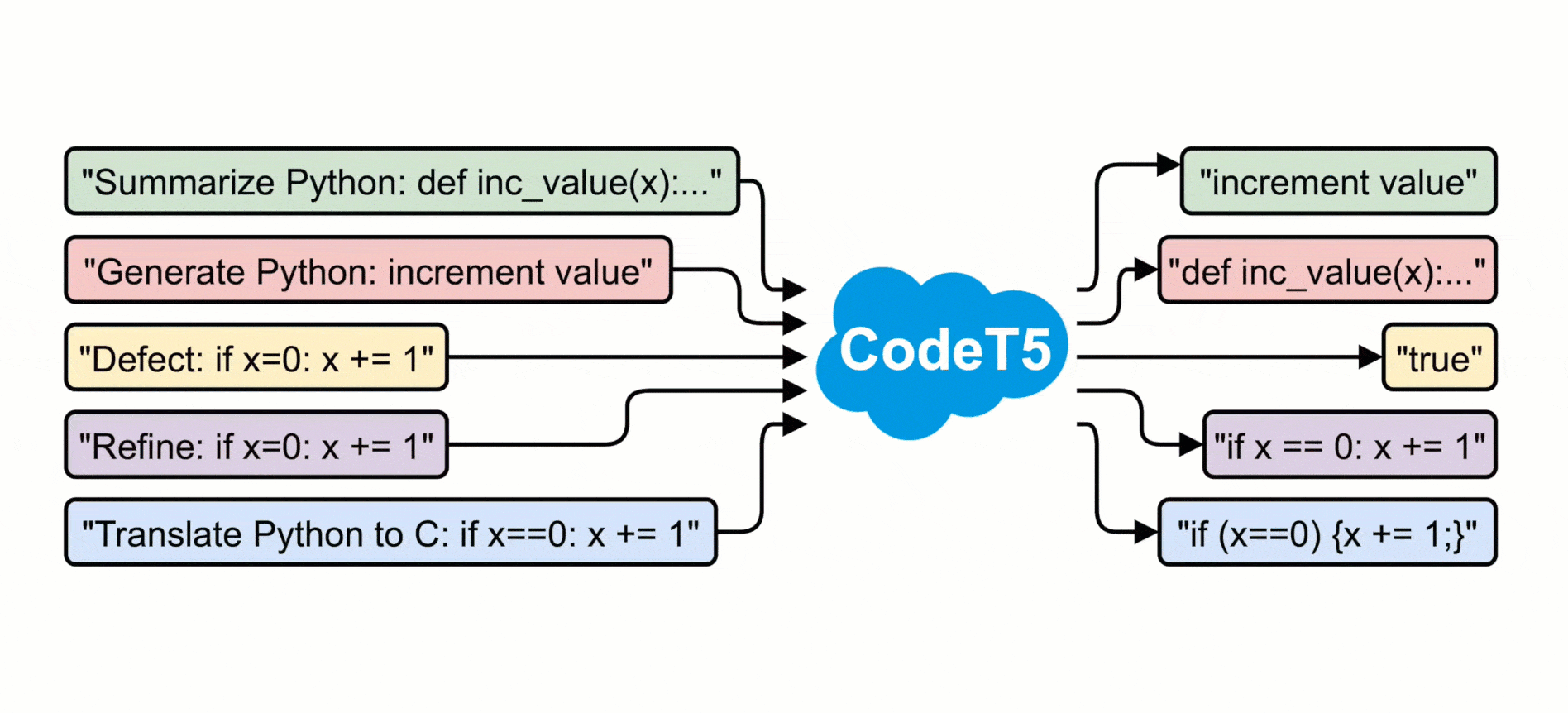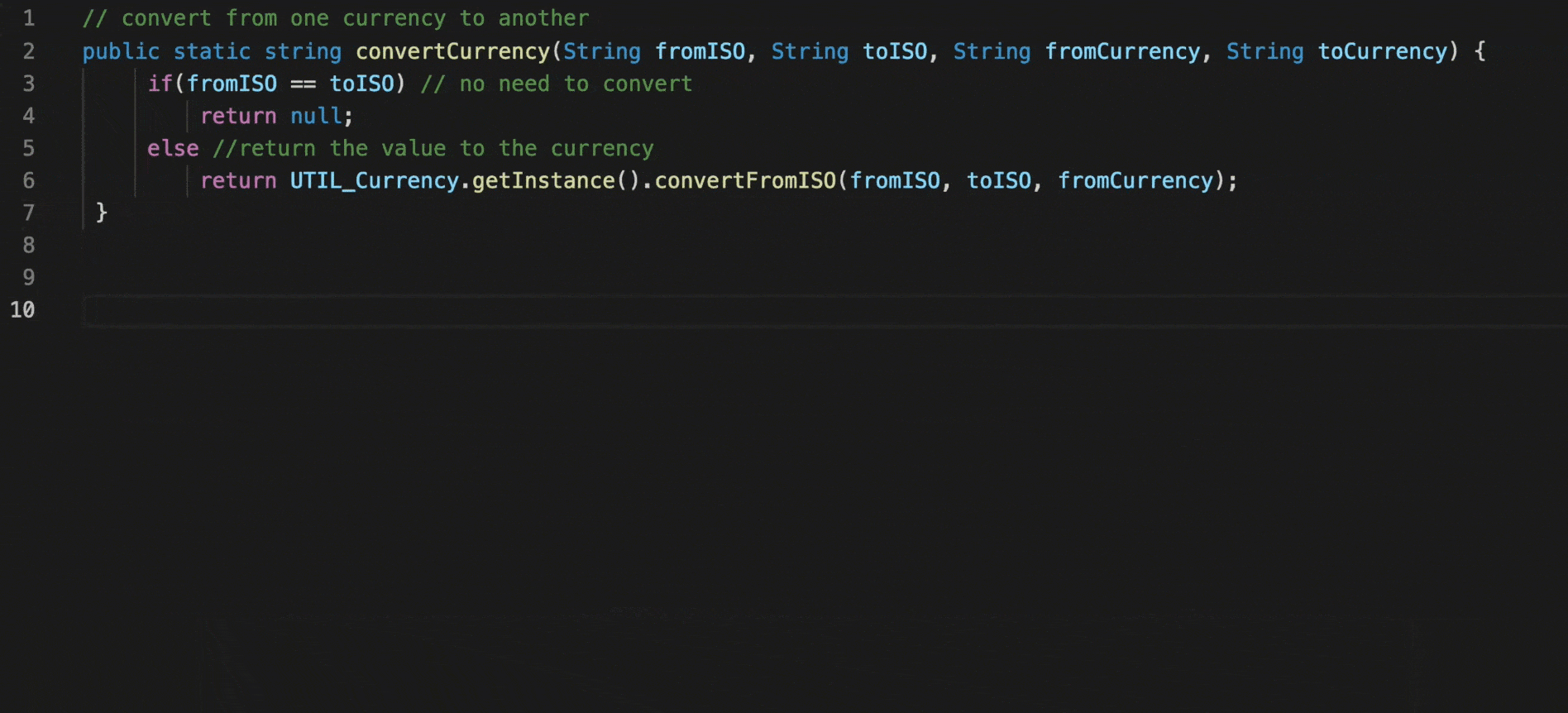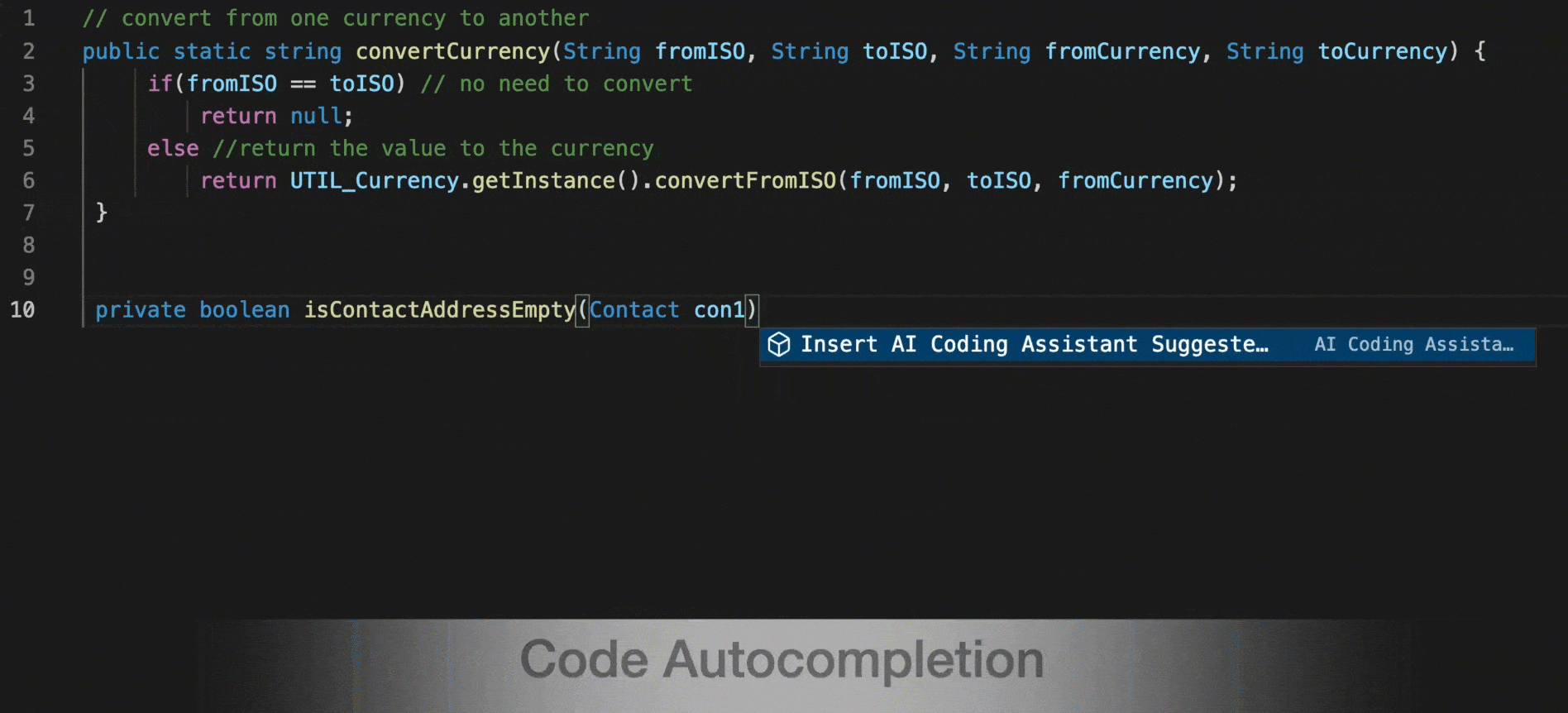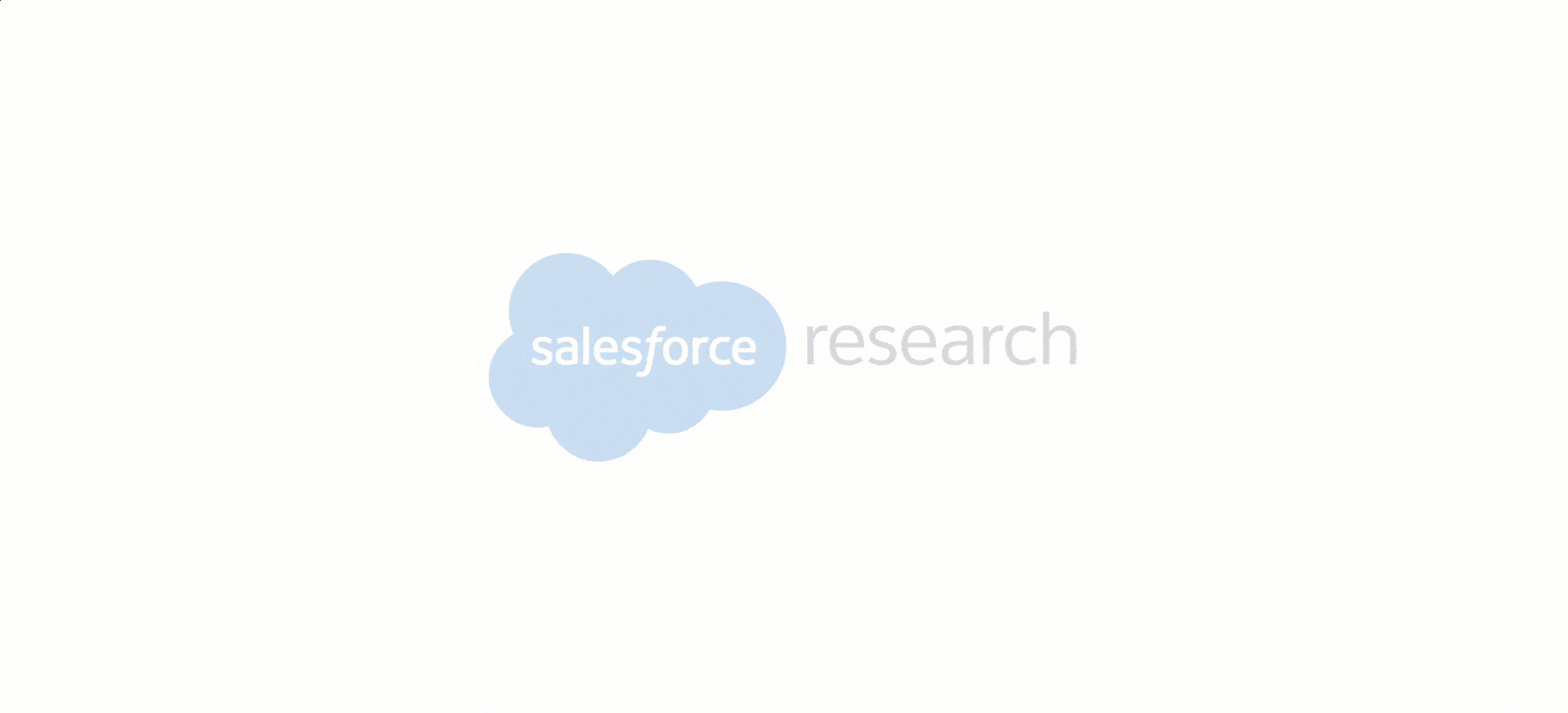
Ce modèle, fraîchement publié, reprend l’architecture du framework T5. Il est néanmoins entraîné, à tour de rôle, sur des tâches supplémentaires :
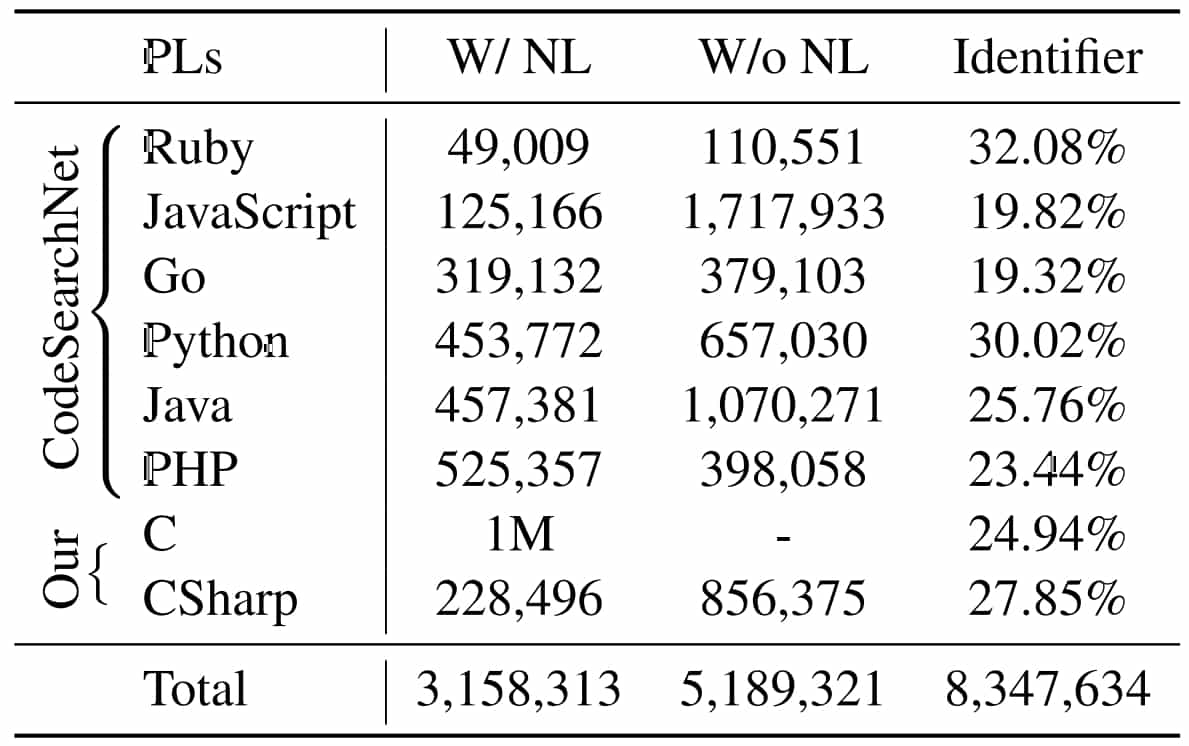
L’entraînement se fait à la fois sur du code et sur la documentation associée. Essentiellement à partir du jeu de données CodeSearchNet. Il implique aussi la réalisation de tâches en parallèle.
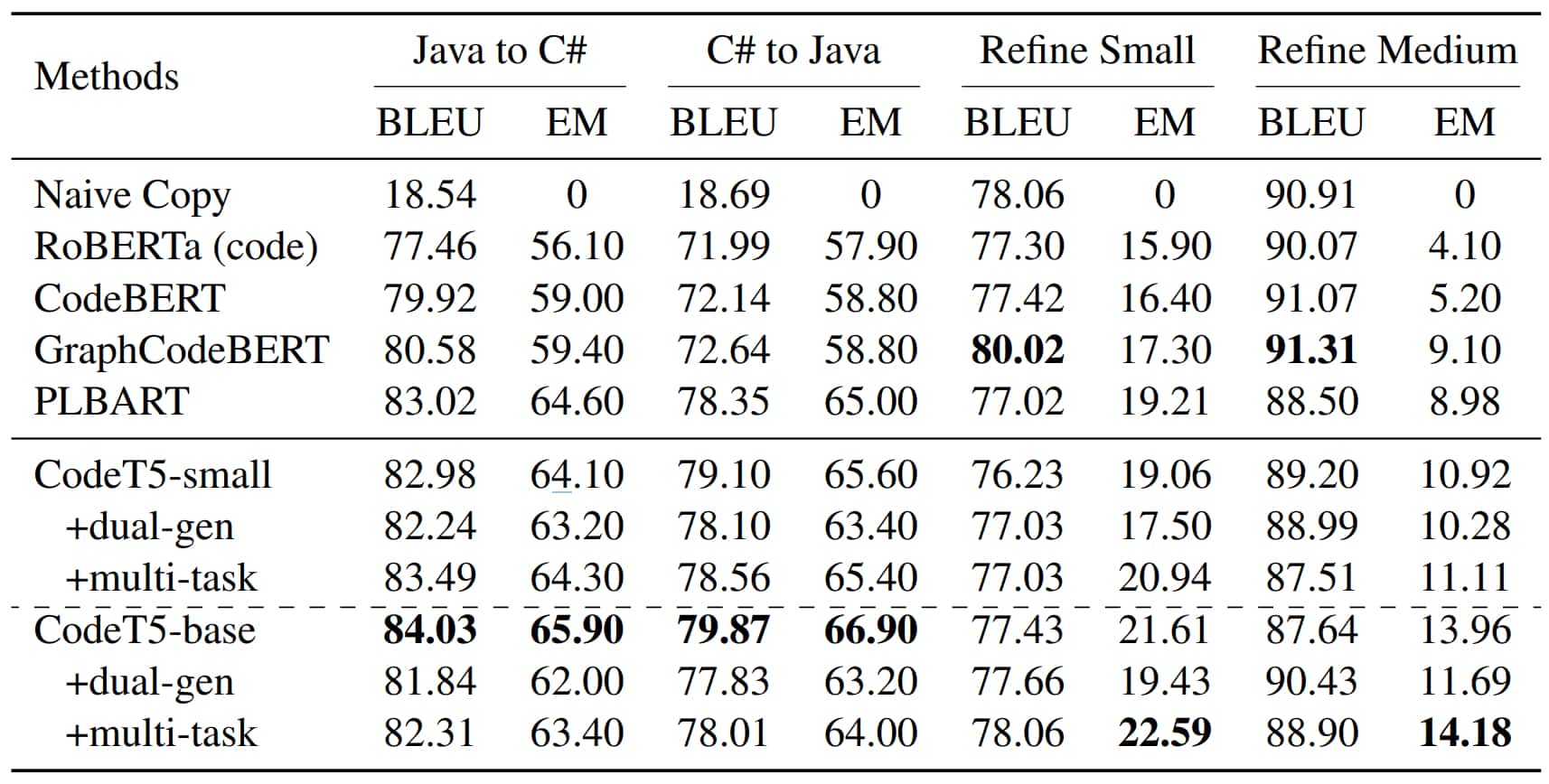
L’évaluation s’est faite sur la base du benchmark CodeXGLUE. Avec, comme principales tâches :
En parallélisant les tâches, on ouvre la voie à la réutilisation des poids ; et donc à l’optimisation des coûts d’exploitation. La taille du modèle est aussi un avantage : 220 millions d’hyperparamètres, contre 12 milliards pour Codex, socle de GitHub Copilot.
Les exercices réalisés à l’entraînement n’ont pas toujours des effets positifs. Par exemple sur l’écriture de code. L’approche bimodale (code vers documentation et vice versa) améliore en particulier l’aptitude au résumé, mais peut réduire les performances en traduction. Probablement à cause de l’émergence d’un biais, suppose Salesforce.
Dans le même ordre d’idée, retirer un exercice permet parfois de gagner en performance. S’il n’apprend pas à reconstituer des fragments masqués, CodeT5 détecte mieux les vulnérabilités.
Illustration principale © maciek905 – Adobe Stock
Pour développer une version 7B de son modèle Codestral, Mistral AI n'a pas utilisé de…
L’Autorité de la concurrence et des marchés (CMA) britannique ouvre une enquête sur les conditions…
Thomas Gourand est nommé Directeur Général pour la France. Il est chargé du développement de…
Pour dissuader le CISPE d'un accord avec Microsoft, Google aurait mis près de 500 M€…
Pour réduire la taille des mises à jour de Windows, Microsoft va mettre en place…
De l'organisation administrative à la construction budgétaire, la Cour des comptes pointe le fonctionnement complexe…
{kind=link}
{kind=link}
{kind=link}