Comment justifier les résultats que produisent les réseaux de neurones artificiels ? Deux écoles de pensée se distinguent. L’une se fonde sur des méthodes d’explication a posteriori. L’autre, sur des modèles « intrinsèquement interprétables ».
Trois chercheurs ont récemment publié un rapport fruit de travaux relevant de la seconde approche. Ils l’ont appliquée à la vision par ordinateur. Avec, comme levier, une transformation linéaire commune en data science : le blanchissement. Et comme cible, l’espace latent, où les réseaux neuronaux représentent les concepts qu’ils apprennent.
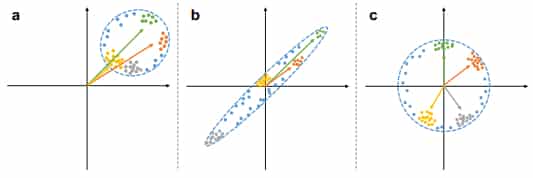
La démarche implique de modifier légèrement l’architecture du modèle qu’on souhaite interpréter. On y intègre pour cela un module qui normalise et décorrèle les axes de l’espace latent afin que les concepts s’y alignent. En contraignant ainsi cet espace, on évite la dissémination des informations relatives aux concepts. Et on peut donc potentiellement mieux comprendre, de couche en couche, comment le modèle les assimile.
Ce n’est pas, et de loin, la première initiative consistant à modifier la structure de modèles de deep learning pour les rendre plus « lisibles ». Mais dans le cas présent, on nous avance, benchmarks à l’appui, un atout : une dégradation quasi nulle des performances. De l’ordre de quelques dixièmes de pourcent en l’occurrence.
Sur les couches les plus basses des réseaux neuronaux, limitées en complexité, les concepts ont tendance à reposer sur des informations « primaires » comme la texture et la couleur. Plus on descend, plus les images qui les représentent sont sémantiquement proches. On le voit ci-dessous pour les concepts d’avion, de lit et de personne.
Illustration principale © psdesign1 – Fotolia
Dans un avis consultatif, l'Autorité de la concurrence a identifié les risques concurrentiels liés à…
OpenAI signe un « partenariat de contenu stratégique » avec Time pour accéder au contenu…
Au lendemain du rejet de sa proposition de restructuration, David Layani annonce sa démission du…
Après un an, Hugging Face a revu les fondements de son leaderboard LLM. Quels en…
Mozilla commence à expérimenter divers LLM dans Firefox, en parallèle d'autres initiatives axées sur l'intégration…
VMware met VCF à jour pour y favoriser la migration des déploiements qui, sur le…
{kind=link}
{kind=link}
{kind=link}