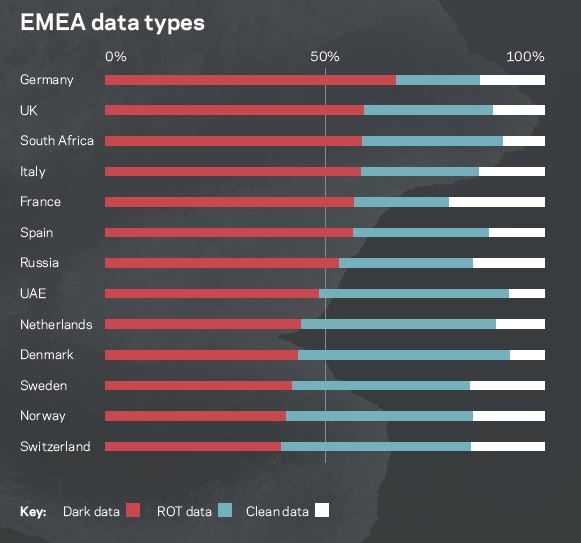
Selon l’étude, les données vitales aux opérations ne représentent que 14 % du volume d’informations stockées par les entreprises. Tandis que les données redondantes, obsolètes (qui ne présentent plus d’intérêt pour l’entreprise) ou triviales constituent une masse plus de deux fois supérieures (32 %). Surtout, plus de la moitié des données stockées par les entreprises ne sont en réalité pas classées : l’organisation est incapable de déterminer si ces informations présentent une quelconque valeur pour leur activité ou pas. Ces données peuvent être soit vitales, soit vouées à rejoindre la masse des informations sans intérêt. « Plus important, ces données sombres peuvent renfermer des données à haut risque violant les règles de conformité auxquelles l’entreprise est soumise. Il s’agit d’un risque critique et ignoré qui se loge au cœur même des systèmes d’information », écrit le fournisseur de logiciels de stockage, qui s’est récemment séparé de Symantec.
Bien entendu, ce manque de classification de l’information et l’absence de politique de destruction régulière des données inutiles se traduisent par des dépenses qui auraient pu être évitées. Vanson Bourne estime que, sur la zone EMEA, ces pratiques se traduiront par 891
Dans cette étude, les entreprises françaises obtiennent toutefois un bon point : 22 % des données qu’elles stockent seraient dûment classées et identifiées comme vitales. Mieux que nos voisins allemands ou anglais. Et ce, même si les DSI de l’Hexagone basent plus souvent leurs budgets sur les volumes de données stockées que sur leur valeur ; une pratique « qui encourage les mauvais comportements », selon l’étude. Vanson Bourne relève également la propension des utilisateurs à ne pas ignore les règles de l’entreprise. Sur le continent, 57 % des employés stockeraient des photos personnelles sur les systèmes de leur employeur.
A lire aussi :
L’Union européenne menace les Big Data des géants américains
Big Data : ne sous-estimez pas le potentiel économique de vos données (tribune)
Big Data : l’Europe traîne son (big) retard
Dans un avis consultatif, l'Autorité de la concurrence a identifié les risques concurrentiels liés à…
OpenAI signe un « partenariat de contenu stratégique » avec Time pour accéder au contenu…
Au lendemain du rejet de sa proposition de restructuration, David Layani annonce sa démission du…
Après un an, Hugging Face a revu les fondements de son leaderboard LLM. Quels en…
Mozilla commence à expérimenter divers LLM dans Firefox, en parallèle d'autres initiatives axées sur l'intégration…
VMware met VCF à jour pour y favoriser la migration des déploiements qui, sur le…
{kind=link}
{kind=link}