Des scientifiques de la Nanyang Technological University (NTU) de Singapour, de la RWTH Aachen University et du Forschungszentrum Juelich ont développé un circuit informatique capable de stocker les données, mais aussi de les traiter. Un gain de temps et d’espace ouvrant la voie à des ordinateurs encore plus minces et plus rapides.
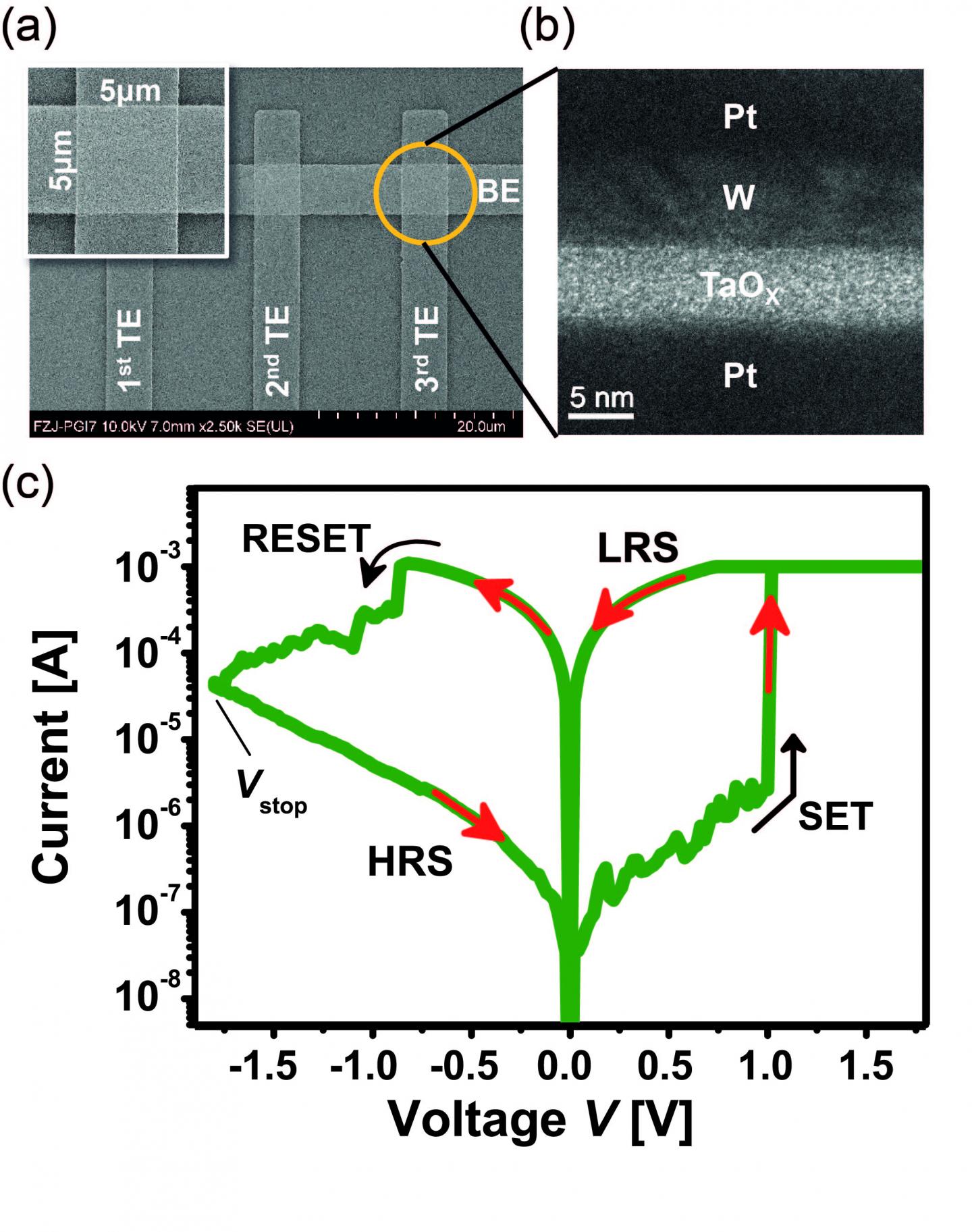
Ce système est construit sur la base de puces mémoire, connues sous le nom ReRAM (resistive Random Access Memory) en utilisant le procédé Redox (réaction d’oxydoréduction). Il s’agit d’un type de mémoire non-volatile développée par différents fabricants mondiaux de mémoire comme Sandisk et Panasonic.
Au lieu de concentrer le ReRam sur le stockage, Anupam Chattopadhyay, professeure au NTU, Rainer Waser, enseignant à Aachen University, et le Dr Vikas Ran du Forschungszentrum Juelich, l’ont également utilisé pour traiter des données. Le fruit de leurs travaux a été publié dans Scientific Reports.
Comment cela fonctionne ? Actuellement, tous les processeurs utilisent le système binaire composé de 2 états, 0 ou 1. La lettre A peut-être traitée et stockée comme étant 01000001, une donnée de 8 octets. Le prototype de ReRam imaginé par l’équipe de chercheurs fonctionne différemment. Il traite les données en 4 états au lieu de 2. Il peut ainsi stocker et traiter des informations sous la forme 0, 1, 2 ou 3, connu étant un système de numérotation quaternaire.
La ReRAM utilise une résistance électrique différente pour stocker les données (cf image ci-dessus), elle est capable de conserver des informations sous forme plus élevée d’états et donc d’accélérer les traitements au-delà de la limitation actuelle. L’objectif est donc de réduire le temps de traitement en le rapprochant de l’endroit où les données sont stockées. Anupam Chattopadhya y va de sa métaphore. « Le processus actuel c’est comme avoir une longue conversation avec quelqu’un grâce à un mini traducteur, poussif et lent. » Et d’ajouter que « nous sommes maintenant en mesure d’augmenter les capacités du traducteur et améliorer son efficacité ».
Les scientifiques cherchent maintenant des partenaires industriels pour développer ce prototype et le commercialiser. Ils espèrent arriver au moment où le marché de la ReRAM va débuter et où les demandes en rapidité de traitement n’ont jamais été aussi fortes (logiciels plus complexes et datacenters au taquet). A voir si la concordance des astres se concrétise.
A lire aussi
La Cour des comptes appelle à formaliser et à professionnaliser certains aspects du RIE, tout…
La Cour des comptes attire l'attention sur le risque d'affaiblissement d'Etalab, privé, ces dernières années,…
Missions historiques de la Dinum, l'ouverture des données publiques et la promotion des logiciels libres…
Pour développer une version 7B de son modèle Codestral, Mistral AI n'a pas utilisé de…
L’Autorité de la concurrence et des marchés (CMA) britannique ouvre une enquête sur les conditions…
Thomas Gourand est nommé Directeur Général pour la France. Il est chargé du développement de…
{kind=link}