IA : Google tease la prochaine génération de ses TPU
À quoi s’attendre avec la prochaine génération des TPU de Google ? La dernière vague du benchmark MLPerf donne des indications. De la classification d’images au jeu de go, elle couvre huit tâches d’entraînement de modèles IA.
Sur les 71 configurations listées, trois sont basées sur ces futurs TPU. La génération actuelle (3e) est également représentée. D’un côté, dans le cadre d’offres commerciales rattachées au portefeuille Compute Engine. De l’autre, à travers un supercalculateur équipé de 4 096 TPU.
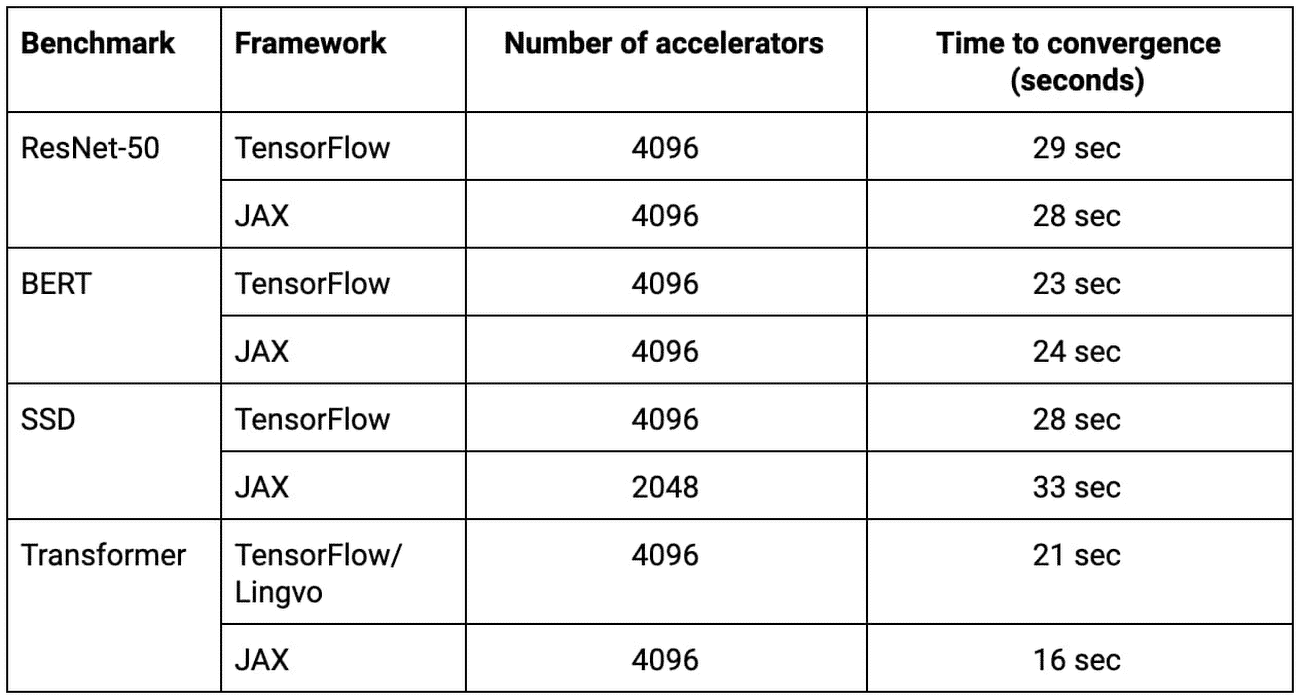
Ce système délivre une puissance de 430 Pflops en crête. Il est capable, avec certains modèles, d’atteindre en moins de 30 secondes les objectifs de performance définis par MLPerf (par exemple, un taux de précision de 75,90 % sur la classification d’images avec ResNet-50).
L’entraînement de ces modèles a impliqué la combinaison des frameworks TensorFlow, Lingvo et JAX. Ainsi que diverses optimisations (parallélisme, normalisation par lots, arbres d’initialisation des poids synaptiques…).
Qu’en est-il des TPU de 4e génération ? Google évoque trois apports principaux : augmentation de la bande passante, avancées sur l’interconnexion et performance plus que doublée en multiplication matricielle.
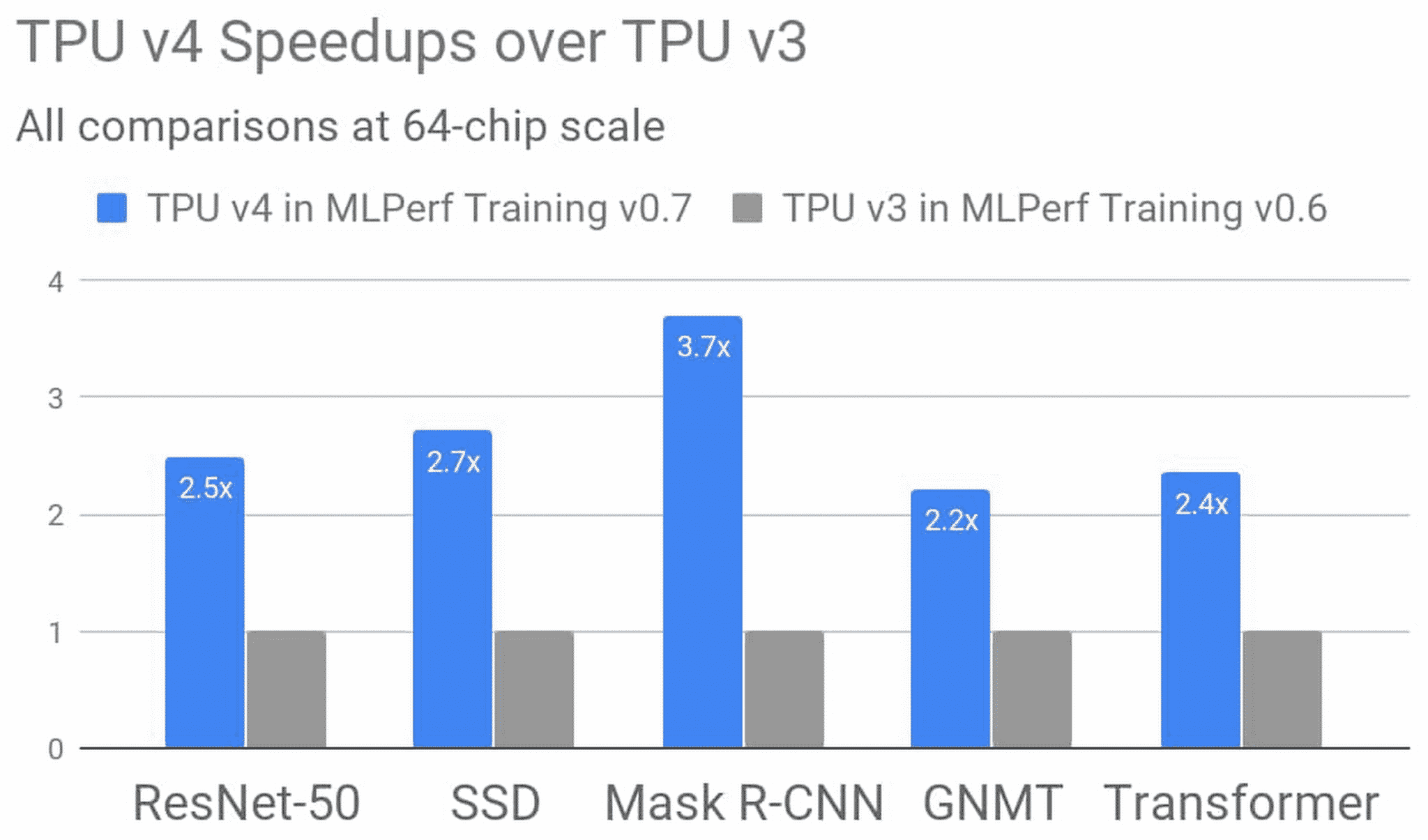
En tenant compte des améliorations logicielles, les performances en entraînement sur 64 TPU sont en moyenne 2,7 plus élevées qu’avec la 3e génération. C’est avec Mask R-CNN que l’écart est le plus grand (x 3,7).
TPU ou GPU ?
Dans le détail, les résultats sont les suivants :
Classification d’images (jeu de données ImageNet, modèle ResNet-50 v1.5) Avec 256 TPU de 4e génération, il a fallu 1,82 minute pour atteindre l’objectif, en entraînement sur TensorFlow. Alibaba fournit la configuration commerciale qui obtient le résultat le plus proche (1,69 minute). Elle associe 320 CPU Intel Xeon Platinum 8163 et 1 280 GPU Nvidia V100-SXM2-32GB, avec le framework PAI MXNet.
Détection d’objets (jeu de données COCO, modèle SSD) Avec 256 TPU, il a fallu 1,06 minute pour atteindre l’objectif. La configuration commerciale qui atteint le résultat le plus proche (1,13 minute) est signée Nvidia. Elle associe 128 Xeon Platinum 8174 et 1 024 GPU V100-SXM3-32GB, avec Nvidia MXNet.
Détection d’objets « avancée » (jeu de données COCO, modèle Mask R-CNN) Avec 256 TPU, il a fallu 9,95 minutes pour atteindre l’objectif. La configuration commerciale qui atteint le résultat le plus proche (10,46 minutes) associe 64 CPU AMD EPUC 7742 et 256 GPU A100-SXM4-40GB, avec Nvidia PyTorch.
Traduction « récurrente » (jeu de données WMT anglais-allemand, modèle NMT) Avec 256 TPU, il a fallu 1,29 minute pour atteindre l’objectif. La configuration commerciale qui atteint le résultat le plus proche (1,11 minute) associe 128 Xeon Platinum 8174 et 1 024 GPU V100-SXM3-32GB, avec Nvidia PyTorch.
Traduction « non récurrente » (jeu de données WMT anglais-allemand, modèle Transformer) Avec 256 TPU, il a fallu 0,78 minute pour atteindre l’objectif. La configuration commerciale qui atteint le résultat le plus proche (0,82 minute) associe 120 Xeon Platinum 8174 et 960 GPU V100-SXM3-32GB.
Traitement du langage naturel (jeu de données Wikipédia au 1er janvier 202, modèle BERT) Avec 256 TPU, il a fallu 1,82 minute pour atteindre l’objectif. La configuration commerciale qui atteint le résultat le plus proche (1,48 minute) associe 256 CPU AMD EPYC 7742 et 1 024 GPU A100-SXM4-40GB, avec PyTorch.
Recommandation (jeu de données de 1 To, modèle DLRM) Avec 64 TPU, il a fallu 1,21 minute pour atteindre l’objectif. La configuration commerciale qui atteint le résultat le plus proche (3,33 minutes) associe 2 CPU EPYC 7742 et 8 GPU A100-SXM4-40GB, avec Merlin HugeCTR + Nvidia DL.
Apprentissage par renforcement (jeu de go, modèle Mini Go) Avec 64 TPU, il a fallu 150,95 minutes pour atteindre le taux de victoires attendu (50 %). La configuration commerciale qui atteint le résultat le plus proche (165,72 minutes) associe 4 CPU EPYC 7742 et 16 GPU A100-SXM4-40GB, avec la Nvidia TensorFlow.
{kind=link}
{kind=link}