À quand la vague GenAI chez Apple ? En l’état, l’entreprise se contente d’affirmer que c’est « pour cette année ».
Quant à savoir où elle en est dans sa R&D, les articles que produisent ses chercheurs donnent des éléments de réponse. Fin 2023, nous nous étions fait l’écho de l’un d’entre eux, axé sur les LLM frugaux. Y était plus précisément proposé un modèle d’inférence adapté aux environnements dont les ressources mémoire sont restreintes.
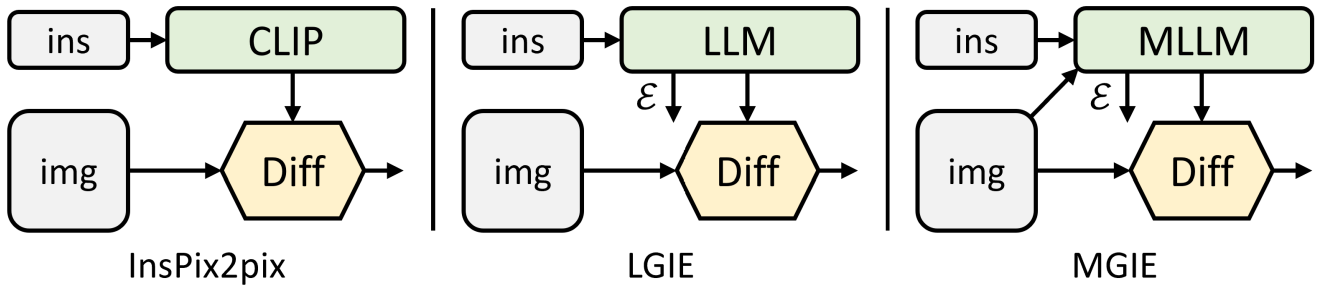
Autre article, autre thème : l’édition d’images. Quatre chercheurs d’Apple en sont coauteurs, ainsi qu’un étudiant et un enseignant de l’université de Californie à Santa Barbara. Il y est question d’une méthode dite MGIE, pour « MLLM-Guided Image Editing ». Son principe, dans les grandes lignes : s’appuyer sur un modèle multimodal intermédiaire capable d’enrichir les instructions que donne l’utilisateur.
D’autres projets ont déjà exploré ce concept de modèle intermédiaire. Parmi eux, InsPix2Pix. Il se fonde toutefois sur un encodeur CLIP… qui n’est donc pas multimodal (il ne travaille que sur le texte). Et qui, parce que non évolutif, capte mal les notions de transformation visuelle.
Le modèle multimodal qui porte MGIE a pour racine LLaVA-7B – et donc son encodeur visuel CLIP-L. Il fait l’objet d’un entraînement sur le dataset IPr2Pr… constitué pour le projet InsPix2Pix. Son contenu : des triplets associant une instruction (générée par GPT-3) à une image d’entrée et une image de sortie (synthétisées avec la méthode Prompt-to-Prompt).
Ainsi entraîné, le MLLM tend à produire des explications longues, voire redondantes. On lui a donc greffé des capacités de synthèse en l’affinant à partir d’un modèle Flan-T5-XXL.
Pour faire le pont entre la modalité langage et la modalité vision, les chercheurs ont introduit, à la suite des instructions, des tokens [IMG]. Un seq2seq à quatre couches (Edit Head sur le schéma ci-dessous) les transforme pour les rendre accessibles au modèle de diffusion sous forme d’« imagnination latente », pour reprendre les termes employés. Une approche similaire à BLIP-2.
Dans le cadre de leurs tests de performances, les chercheurs ont comparé MGIE à InsPix2Pix… et à une configuration LGIE. Celle-ci utilise LLaMA-7B à la place de CLIP, mais elle ne retravaille les instructions (Ɛ) qu’à partir de l’information textuelle.
Les tableaux suivants présentent les résultats sur quatre benchmarks. EVR et GIER impliquent des modifications de type Photoshop. MA5k, de l’optimisation globale d’images (contraste, luminosité, saturation…). MagicBrush, des modifications locales d’objets.
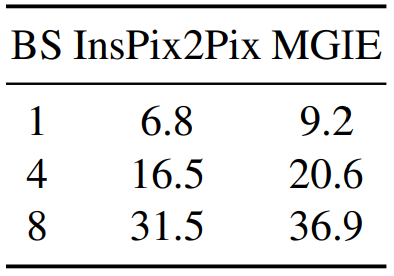
Sur un GPU NVIDIA A100 40 Go, MGIE peut, pour un input unique, exécuter une tâche d’édition en moins de 10 secondes. En parallélisant les données, l’évolution est plus ou moins linéaire (37 secondes pour un lot de 8 inputs).
Illustration principale ©faithie – Adobe Stock
Thomas Gourand est nommé Directeur Général pour la France. Il est chargé du développement de…
Pour dissuader le CISPE d'un accord avec Microsoft, Google aurait mis près de 500 M€…
Pour réduire la taille des mises à jour de Windows, Microsoft va mettre en place…
De l'organisation administrative à la construction budgétaire, la Cour des comptes pointe le fonctionnement complexe…
Sous la bannière SpreadSheetLLM, Microsoft propose un framework destiné à optimiser le traitement des feuilles…
Selon le magazine Wired, AT&T aurait payé près de 400 000 $ à un pirate…
{kind=link}
{kind=link}
{kind=link}
{kind=link}