Les modèles de fondation* peuvent-ils s’exécuter efficacement sur des infrastructures composées de matériel « sur étagère » ? IBM a suivi cette piste… pour en arriver à Vela.
Le groupe américain vient de lever le voile sur ce « superordinateur IA » – pour reprendre ses termes, les mêmes que Microsoft utilise dans le cadre de son partenariat avec OpenAI. Ses équipes de recherche l’utilisent, affirme-t-il, depuis mai 2022.
Vela a la particularité d’être intégré avec le cloud d’IBM. Il peut donc en exploiter les composantes (VPC, stockage objet…) et les ressources pour monter en charge.
Concrétiser cette intégration a impliqué de développer un système capable d’exploiter du réseau standard de type Ethernet (par opposition à des technologies dédiées comme InfiniBand).
Pour éviter le goulet d’étranglement, on a notamment activé le SR-IOV (virtualisation d’entrée-sortie à racine unique), les extensions VMX et les pages mémoire larges. Tout en associant un système de contrôle de débit à l’API FSDP (Fully Shared Data Parallel) de PyTorch. Laquelle permet de distribuer les modèles et leurs données entre les GPU.
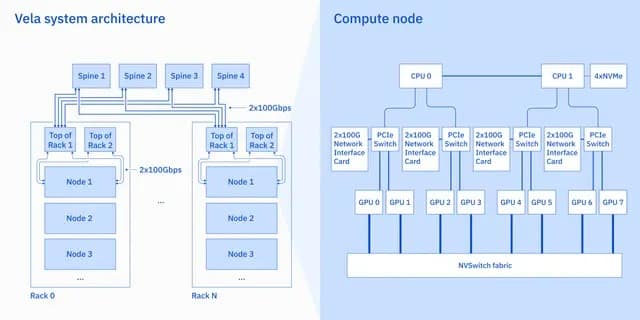
L’expérimentation a reposé pour l’essentiel sur du matériel « standard ». En l’occurrence, des nœuds dotés de processeurs x86, de GPU NVIDIA, du NVLink et de deux liens 100 Gbps chacun.
La base est similaire pour Vela. Chaque nœud embarque deux Xeon Scalable (Cascade Lake), quatre disques NVMe de 3,2 To, 1,5 To de RAM et 8 GPU A100 (80 Go) avec NVLink et NVSwitch.
IBM a fait le choix d’instancier des VM plutôt que d’allouer du matériel nu. Motif : cela facilite la montée en charge dynamique des clusters (Vela utilise OpenShift) et la réattribution de ressources entre workloads. Les technologies susmentionnées viennent réduire la surcharge inhérente à ce choix. Elles permettent de « masquer » la latence réseau derrière la latence GPU. Latence qu’IBM estime pouvoir diviser par deux en déploiement le RoCE (RDMA over Converged Ethernet) et le GDR (GPU Direct RDMA).
* De grande taille, entraînés sur une petite quantité de données non étiquetées, et adaptables à des tâches en aval.
Photo d’illustration © Chetan Creation – Adobe Stock
Dans un avis consultatif, l'Autorité de la concurrence a identifié les risques concurrentiels liés à…
OpenAI signe un « partenariat de contenu stratégique » avec Time pour accéder au contenu…
Au lendemain du rejet de sa proposition de restructuration, David Layani annonce sa démission du…
Après un an, Hugging Face a revu les fondements de son leaderboard LLM. Quels en…
Mozilla commence à expérimenter divers LLM dans Firefox, en parallèle d'autres initiatives axées sur l'intégration…
VMware met VCF à jour pour y favoriser la migration des déploiements qui, sur le…
{kind=link}