En matière d’IA, où en est Snowflake ? Le schéma suivant résume la situation.
Les trois éléments en haut à gauche sont des fonctions « prêtes à l’emploi », accessibles sur l’interface graphique. Elles sont pour le moment en bêta privée.
Avec Document AI, on est sur de l’extraction de contenu.
Snowflake Copilot est un assistant de codage SQL.
Universal Search se fonde sur la technologie de Neeva (que Snowflake a acquis en mai). La version initiale permettra de trouver tables, vues, bases de données, schémas, éléments de la marketplace et articles de documentation.
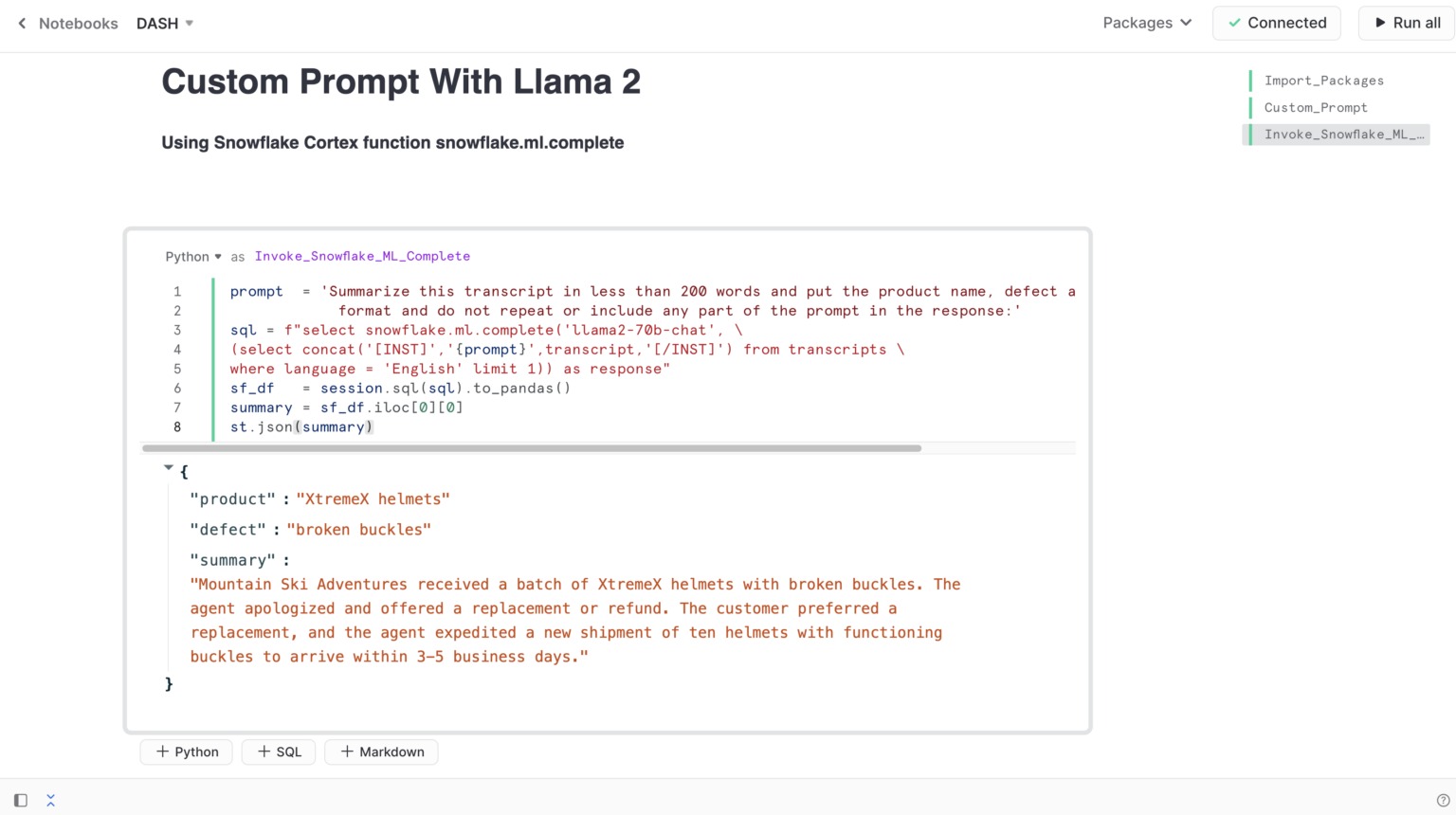
Ces capacités reposent sur un moteur de fonctions sans serveur. Appelé Cortex, il donne également un accès API à :
– Diverses fonctionnalités basées sur des LLM (détection de sentiment, extraction de réponses, résumé de texte et traduction), toutes en bêta privée
– Du machine learning « maison » pour la prédiction et la détection d’anomalies sur séries temporelles (« disponibilité globale bientôt »), la classification (bêta privée à venir) et l’identification de facteurs d’évolution de métriques (bêta publique)
– Des modèles conversationnels pour la complétion (bêta privée ; base : Llama 2 en versions 7, 13 et 70 milliards de paramètres) et le codage SQL (bêta privée ; version « programmatique » de Copilot)
– Vectorisation et recherche vectorielle, avec un type de donnée natif (bêta privée)
La case « Apps in minutes » fait référence à l’intégration du framework Streamlit dans Snowflake. Elle aussi est pour le moment en bêta privée.
Les éléments sur la droite du schéma viennent se placer sous l’ombrelle Snowpark ML.
Lancé en 2019, Snowpark associe bibliothèques et runtimes pour le déploiement et le traitement d’autres langages que SQL. La « boîte à outils » Snowpark ML en est une composante. Elle fournit bibliothèque Python et infrastructure gérée.
Snowflake va y ajouter :
– Une API permettant d’utiliser des frameworks de type Scikit-learn et XGBoost sans créer de procédures stockées (Modeling API ; disponibilité générale « bientôt »)
– Un registre (bêta publique à venir) avec gestion des versions et RBAC
– Un feature store et une interface de notebooks (bêta privée)
Illustration principale © Tada Images – Adobe Stock
Dans un avis consultatif, l'Autorité de la concurrence a identifié les risques concurrentiels liés à…
OpenAI signe un « partenariat de contenu stratégique » avec Time pour accéder au contenu…
Au lendemain du rejet de sa proposition de restructuration, David Layani annonce sa démission du…
Après un an, Hugging Face a revu les fondements de son leaderboard LLM. Quels en…
Mozilla commence à expérimenter divers LLM dans Firefox, en parallèle d'autres initiatives axées sur l'intégration…
VMware met VCF à jour pour y favoriser la migration des déploiements qui, sur le…
{kind=link}