En direct de Copenhague : Teradata a redéfini sa stratégie et intégré la brique Hadoop dans son offre.
Cette évolution est considérée comme majeure, car elle permet au fabricant d’apporter sa réponse à la vague du Big Data (lire « Teradata Universe 2013 : l’opportunité Big Data »). Même si de l’avis même des managers de Teradata que nous avons rencontrés, « nous faisons du Big Data depuis toujours ! ».
La concrétisation de cette stratégie se nomme Unified Data Architecture. Teradata y construit une architecture composée tout d’abord de ses solutions. Teradata pour l’entrepôt de données (datawarehouse) et les outils de BI (Business Intelligence) qui lui sont associés. Aster, acquis en 2011, pour l’analytique Big Data.
Il lui manque la brique Hadoop : elle est apportée par Hortonworks. Comme le souligne Jean-Marc Bonnet, responsable en France du Lab Teradata, « nous faisons le choix de la transparence en retenant la solution open source Apache ». Exit donc les Hadoop ‘transformés’ en produits propriétaires Cloudera et MapR, même si le constructeur disposera des connecteurs pour communiquer avec ces derniers.
« Nous supportons tous les catalogues d’intégration de Hortonworks afin de standardiser les objets Big Data, tandis que toutes les analytiques s’exécutent en parallèle », nous a indiqué Scott Gnau, président de Teradata Labs.
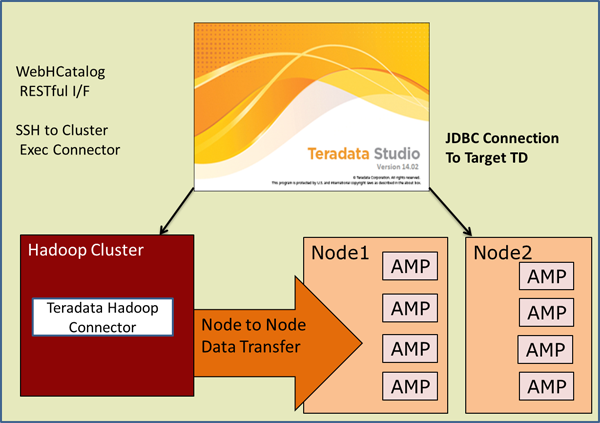
Pour rapprocher ses utilisateurs des fonctionnalités d’interrogation de la base Hadoop, Teradata a développé une application spécifique qui permet d’accéder à la demande et en temps réel aux données.
Comme son nom l’indique, SQL-H offre à Hadoop un système de requêtage proche du langage SQL. Les données migrent ensuite dans Taradata pour passer à la moulinette analytique. SQL-H sert également de gateway sécurisée pour accéder aux données Big Data.
« Avec SQL-H, nous offrons l’accès à la volée aux données contenues dans des clusters Hadoop plus détaillés et plus opérationnels, accessibles plus facilement et avec plus de sécurité, commente Scott Gnau. L’accès au Big Data est en mode self-service et les mouvements de données sont bidirectionnels. »
Second produit annoncé pour l’Unified Data Architecture, Smart Loader for Hadoop est un outil d’accès à la donnée Big Data en self-service, pour feuilleter et déplacer les données entre l’entrepôt Teradata et Hadoop, selon un mode ‘point-and-click’.
Voir aussi
Silicon.fr étend son site dédié à l’emploi IT
Silicon.fr en direct sur les smartphones et tablettes
Dans un avis consultatif, l'Autorité de la concurrence a identifié les risques concurrentiels liés à…
OpenAI signe un « partenariat de contenu stratégique » avec Time pour accéder au contenu…
Au lendemain du rejet de sa proposition de restructuration, David Layani annonce sa démission du…
Après un an, Hugging Face a revu les fondements de son leaderboard LLM. Quels en…
Mozilla commence à expérimenter divers LLM dans Firefox, en parallèle d'autres initiatives axées sur l'intégration…
VMware met VCF à jour pour y favoriser la migration des déploiements qui, sur le…
{kind=link}
{kind=link}