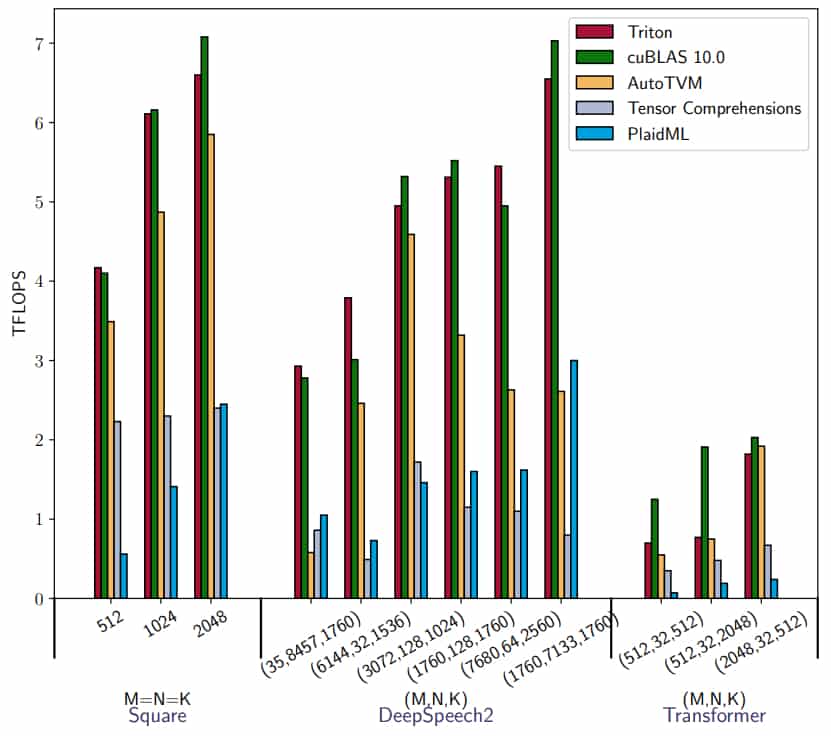
L’heure de la maturité pour Triton ? Le projet, que porte OpenAI, vient de passer en version 1.0. Sa principale brique : un langage dédié ciblant le deep learning. Objectif : faciliter l’implémentation d’opérations non optimisées pour les bibliothèques de référence.
Triton arrive sur un terrain déjà bien occupé. Deux approches majeures s’y sont développées. D’un côté, la compilation polyédrique, adoptée notamment par Tiramisu et Tensor Comprehensions. Elle représente les programmes de sorte que le flux de contrôle est prédictible. Cela favorise les transformations lors de la compilation, en intégrant le parallélisme et la localité des données.
La méthode permet par ailleurs de contrôler la préservation sémantique. Elle présente en revanche une consommation importante de ressources – doublée de procédures coûteuses d’autotuning – et une certaine inertie face au codage parcimonieux.
L’autre approche, adoptée entre autres par Halide et TVM, implique les langages de planification. Ces derniers mettent en œuvre le principe de séparation des préoccupations : ils dissocient l’implémentation de la conception. On n’a donc à écrire qu’une seule fois un algorithme, puis on l’optimise à part. Avec la possibilité de spécifier des éléments qu’un compilateur polyédrique n’aurait pas pu déterminer à partir de l’analyse statique des flux de données.
Les systèmes fondés sur ce paradigme présentent eux aussi des limites face au codage parcimonieux. Il peut en résulter des contraintes importantes dans la planification.
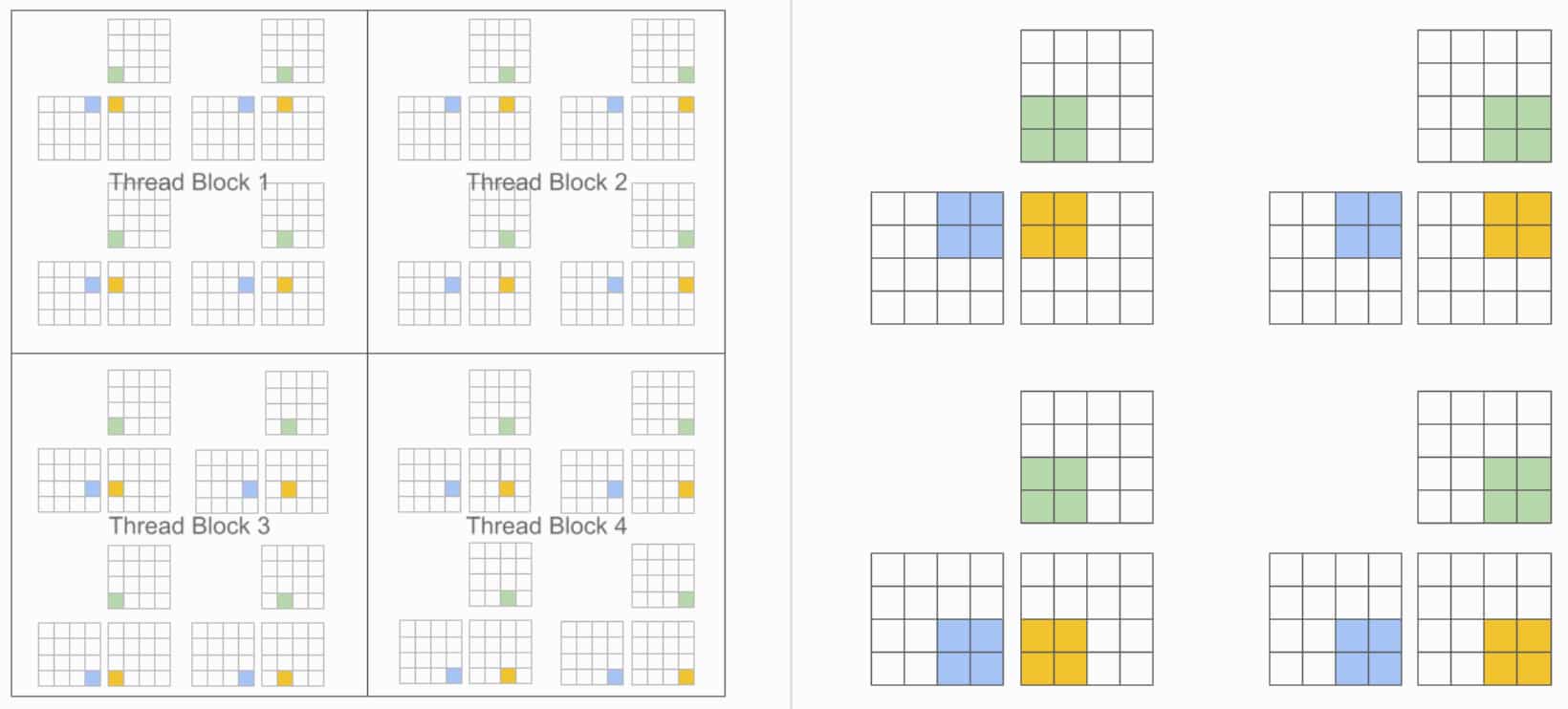
Triton repose sur une variante du modèle d’exécution SMPD (Single Program, Multiple Data). Avec elle, ce sont pas les tâches qui sont architecturées en blocs, mais les programmes. Soit l’inverse de CUDA (à gauche sur l’exemple ci-dessous, une multiplication matricielle).
Cette approche se révèle particulièrement flexible lorsqu’on a à traiter des matrices creuses (qui comportent beaucoup de coefficients nuls). En analysant les flux de données au niveau des blocs, le compilateur Triton est capable d’automatiser un certain nombre d’opérations importantes. Dont la coalescence (agrégation des transferts DRAM), la vectorisation et la planification des cœurs.
Triton fonctionne pour le moment sur des GPU NVIDIA. Des travaux sont en cours pour l’adapter aux GPU AMD et aux CPU. On évitera la confusion avec un autre projet du même nom, made in NVIDIA. Il s’agit d’un moteur d’inférence. La plate-forme de cybersécurité Morpheus, actuellement en accès anticipé, en fait usage.
Illustration principale © kras99 – Adobe Stock
Respectivement DG et CTO de Red Hat France, Rémy Mandon et David Szegedi évoquent le…
Canonical formalise un service de conception de conteneurs minimalistes et y associe des engagements de…
L'Autorité de la concurrence s'apprêterait à inculper NVIDIA pour des pratiques anticoncurrentielles sur le marché…
Le CERT-FR revient sur les failles dans équipements de sécurité présents notamment en bordure de…
Mistral AI formalise ses travaux communs avec l'entreprise finlandaise Silo AI, qui publie elle aussi…
La présidente de Numeum, Véronique Torner, revient sur la genèse de la tribune du collectif…
{kind=link}
{kind=link}
{kind=link}