Entre quantité et qualité des données sources, où se trouve le bon compromis pour entraîner un modèle de reconnaissance vocale multilingue ? Cette question a sous-tendu le développement de Whisper. À la baguette, OpenAI, qui vient de publier le projet sous licence MIT.
Whisper est un transformeur Seq2seq. Bien qu’évalué essentiellement sur la reconnaissance vocale, il peut réaliser d’autres tâches. En l’occurrence, la traduction, l’identification de langues et la détection de voix.
OpenAI a décidé non pas de s’appuyer sur les datasets de référence, mais de compiler son propre corpus. Moins qualitatif, avec une phase réduite de préparation des données, mais aussi plus volumineux : 680 000 heures d’audio avec les transcriptions correspondantes. Dans le détail :
– 438 000 heures d’audio en anglais avec transcriptions en anglais
– 126 000 heures dans 98 autres langues avec transcriptions en anglais
– 117 000 heures ces mêmes langues avec transcription correspondante
En toile de fond, des travaux menés, notamment, dans le domaine de la vision par ordinateur (Mahajan et al., 2018 ; Kolesnikov et al., 2020). Et qui ont précisément consisté à prendre ses distances avec les jeux de données référents de type ImageNet, en faveur de datasets moins supervisés. Ils avaient permis de constaté une meilleure capacité de généralisation sur les modèles entraînés.
OpenAI a publié cinq versions de Whisper, à autant de stades d’entraînement. Tous, sauf le plus grand (1,55 milliard d’hyperparamètres), sont déclinés en multilingue ou anglais seulement.
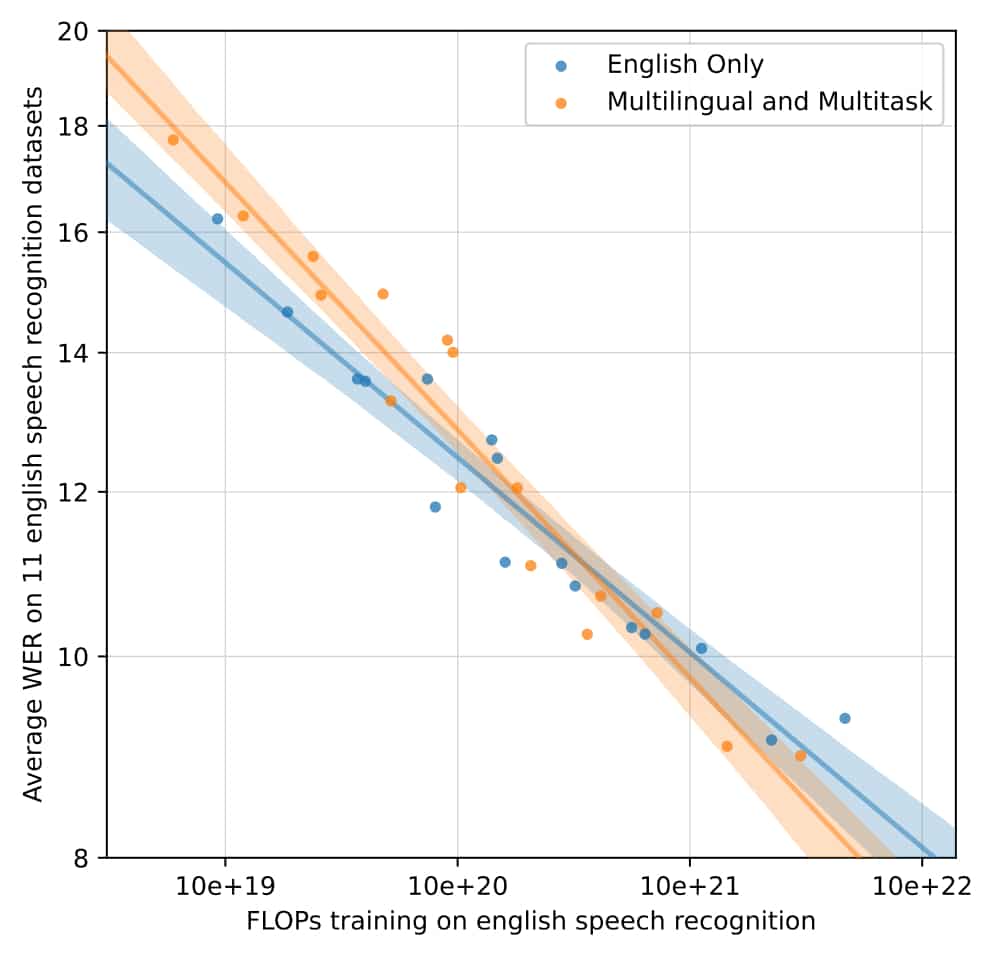
Exception faite de la reconnaissance vocale en anglais, les performances augmentent avec la quantité de données (ASR multilingue, traduction, identification de langues).
À petite échelle, les modèles « anglais uniquement » ont de meilleurs résultats. Puis la tendance s’inverse en faveur de ceux entraînés sur plusieurs tâches.
Sur le même créneau, on a récemment vu émerger BLOOM (BigScience Large Open-science Open-access multilingual Language Model). Avec ses 70 couches de neurones, 112 têtes d’attention et 176 milliards de paramètres, il ne joue pas dans la même cour que Whisper. Il faut dire que les moyens qu’il a monopolisés sont sans comparaison.
Un millier de scientifiques se sont impliqués dans son développement, représentant quelque 70 pays et des sociétés comme Airbus, Meta AI, Mozilla, Orange Labs ou Ubisoft. L’entraînement a eu lieu en France, sur le supercalculateur Jean Zay, localisé à Saclay (Essonne). La dotation en ressources de calcul – subvention CNRS + GENCI – pour la première phase d’entraînement est estimée à environ 3 millions d’euros.
À la base de BLOOM, pas d’architecture maison, mais un fork de Megatron-DeepSpeed. Qui lui-même dérive de Megatron-LM (modèle de langage made in NVIDIA à 345 millions de paramètres, architecturé sur le modèle de GPT-2 et entraîné sur Wikipédia, OpenWebText et CC-Stories).
Illustration principale ©
Pour développer une version 7B de son modèle Codestral, Mistral AI n'a pas utilisé de…
L’Autorité de la concurrence et des marchés (CMA) britannique ouvre une enquête sur les conditions…
Thomas Gourand est nommé Directeur Général pour la France. Il est chargé du développement de…
Pour dissuader le CISPE d'un accord avec Microsoft, Google aurait mis près de 500 M€…
Pour réduire la taille des mises à jour de Windows, Microsoft va mettre en place…
De l'organisation administrative à la construction budgétaire, la Cour des comptes pointe le fonctionnement complexe…
{kind=link}