Les branches Git, un système contre-intuitif ?
Publié par Clément Bohic le | Mis à jour le
Une développeuse pointe le caractère « contre-intuitif » des branches Git. Mais comment se les représenter au juste ?
Pourquoi tant de gens ont-ils du mal à se faire une représentation mentale de Git ? La question a fini par tomber, dans le cadre d'une discussion consécutive à la prise de position d'une développeuse. Celle-ci venait de pointer le fonctionnement « contre-intuitif » des branches.
{kind=link}
{kind=link}
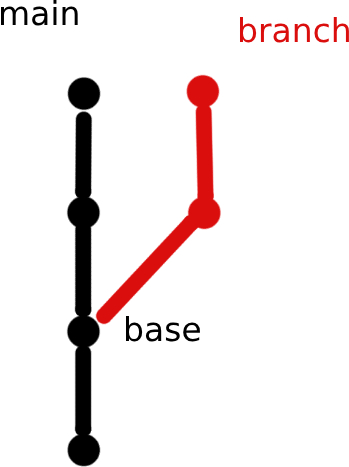
L'intéressée fonde sa démonstration sur l'absence de concept de « parenté » entre branches. Partant, Git ne les définirait pas comme l'humain le ferait. En l'occurrence, de la manière illustrée ci-contre.
Dans Git, une branche est l'historique complet de tous les commits précédents, explique-t-elle. Pas seulement ce ceux de la ramification. Ainsi, main et branch ont ici chacune quatre commits, dont deux en commun.
Suite de la démonstration : dans Git, les branches sont représentées par des fichiers texte contenant l'identifiant de leur dernier commit. Si cela fonctionne, c'est parce que chaque commit contient un pointeur vers son ou ses parents. Le système ne sait pas pour autant que branch est une ramification de main.
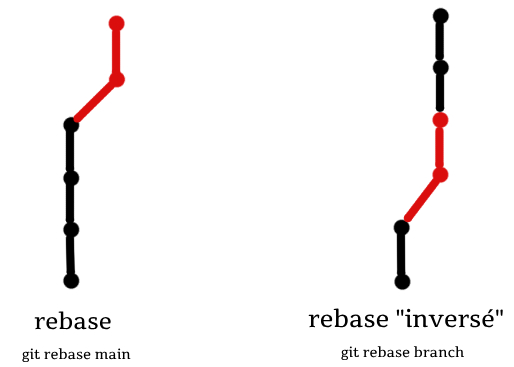
La conception « intuitive » est donc fausse... mais d'une certaine manière, elle est quand même juste, poursuit la développeuse. La preuve : les commandes rebase et merge en font usage, comme les PR GitHub. Plus précisément :
- Le rebasing de branch sur main prend les deux commits de la première et les copie sur la seconde.
- La fusion n'effectue pas de copie, mais elle a besoin d'un commit « de base ». C'est à partir de ce point que se fait l'examen des changements.
- Sur GitHub, si on crée un PR pour fusionner branch dans main, les deux commits de la « branche intuitive » s'affichent.
Dans tous les cas, Git ne sachant pas que branch est une ramification de main, il faut lui préciser où effectuer l'opération. Cette ignorance de la notion de parenté fait qu'il permet, par exemple, d'effectuer le « rebasing inversé », contre-intuitif au premier abord.
{kind=link}
{kind=link}
Les branches Git, une histoire de pointeurs
Cette vision des choses ne fait pas l'unanimité, loin de là. Mais l'opposition n'est pas non plus unanime, en tout cas dans la discussion en question. Les participants s'accordent néanmoins, pour l'essentiel, sur le fait que les branches sont une forme de pointeur.
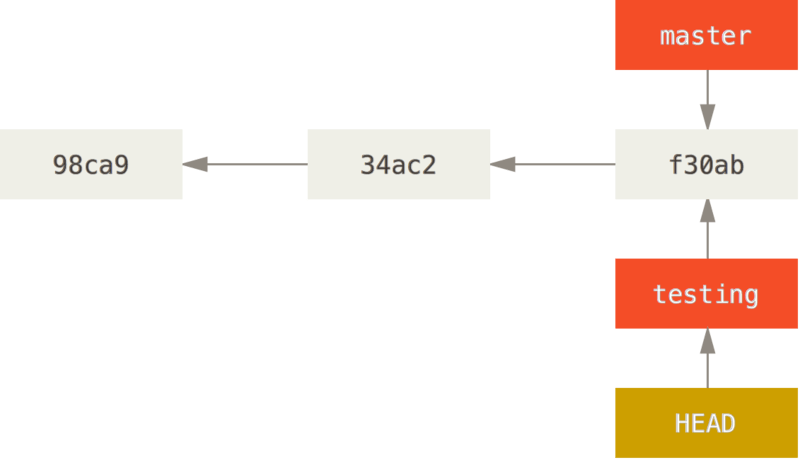
Le livre Pro Git, en son chapitre 3.1 (« Les branches en bref »), le confirme : « Une branche Git est simplement un pointeur léger et déplaçable vers un [commit] ». Il prend la forme d'un simple fichier contenant les 40 caractères de l'empreinte SHA-1 du commit sur lequel il pointe. Au fur et à mesure des validations, une branche « avance » vers le dernier des commits réalisés.
{kind=link}
Une branche et l'historique de ses commits. Extrait du livre Pro Git (licence Creative Commons Attribution-NonCommercial-ShareAlike 3.0).
Créer une nouvelle branche, c'est créer un nouveau pointeur vers le commit courant. Git sait alors alors sur quelle branche on se trouve grâce au pointeur spécial appelé HEAD.
{kind=link}
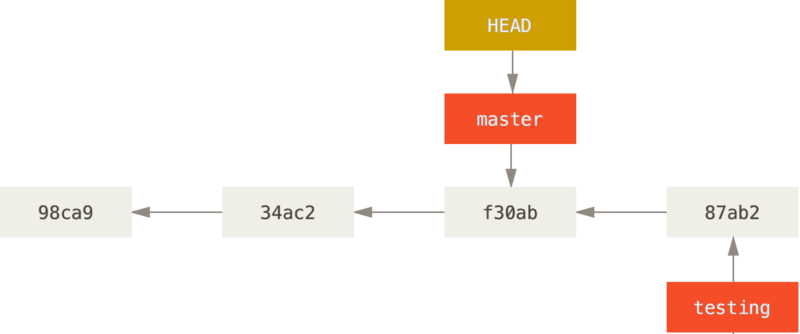
La commande git checkout, utilisée pour pour basculer entre les branches, déplace le pointeur HEAD.
{kind=link}
{kind=link}
À chaque commit, la branche HEAD avance. À partir de là, l'historique du projet diverge.
{kind=link}
{kind=link}
Illustration principale © Araki Illustrations - Adobe Stock