

Comment Delivery Hero a optimisé ses coûts Kubernetes
Du l’autoscaling au bin packing, Delivery Hero a optimisé l’infrastructure Kubernetes soutenant ses services de recherche et de recommandation.

Comment optimiser les coûts d’une infrastructure cloud ? Par exemple, en optant pour des instances spot, en sélectionnant la région au meilleur rapport prix/performance, en dimensionnant bien ses applications et en optimisant l’allocation des ressources.
Autant d’ingrédients de base que Delivery Hero a appliqués au déploiement GKE (Google Kubernetes Engine) qui porte ses services de recherche et de recommandation. L’API fournie dans ce cadre gère la répartition de charge et le basculement automatique. Dans chaque zone géographique servie, elle est disponibles sur deux régions cloud à trois zones chacune. L’objectif : pouvoir tuer à tout moment les pods dans lesquelles elles s’exécutent sans perturber le système.
Le déploiement reposait initialement sur des instances N1, à base de processeurs Intel. Pour les remplacer, Delivery Hero a examiné trois types de machines à usage général : les N2, N2D et T2D. Principales différences par rapport aux N1 : les types de processeurs et les ratios vCPU/mémoire. Les tests de charge ont démontré qu’on pouvait, avec cette nouvelle génération de VM, obtenir le même résultat en consommant 35 à 45 % moins de CPU.
Pour ce qui est du choix des régions cloud, Delivery Hero a analysé trois éléments en particulier : la latence, la disponibilité des machines et leur coût. Il a restreint ses tests de charge dans les régions qui lui paraissaient les plus appropriées en fonction de l’emplacement des clients et des dépendances amont/aval.
Le simulateur de coût Google Cloud a quant à lui fait apparaître de nettes différences entre régions pour les VM N2D. La même configuration (n2d-standard-8) revenait à 73,06 $ HT par mois en eu-west3 (Francfort), contre 27,42 $ en eu-west4 (Pays-Bas).
Les VM T2D étaient pour leur part disponibles dans moins de régions que les N2D. Et celles où elles l’étaient affichaient des prix élevés.
Delivery Hero relève son seuil d’autoscaling
Les performances CPU accrues des VM N2D par rapport aux N1 ont permis de faire évoluer plusieurs paramètres de dimensionnement des apps. D’une part, chaque pod peut ne réserver qu’un thread au lieu des deux demandés jusqu’alors. De l’autre, on a pu relever le seuil d’autoscaling à 50 % d’usage processeur, contre 35 % auparavant. En parallèle, la quantité de RAM par pod a été réduite de 6 à 4 Go.
Les VM n2d-standard-8 disposent de 8 vCPU et de 32 Go de RAM. Delivery Hero a ainsi pu loger 7 pods par nœud, en tenant compte des ressources non allouables. Il en a profité pour supprimer le pod de réserve qu’il exploitait sur les N1.

Lire aussi : Kubecost, acquisition couleur FinOps pour IBM
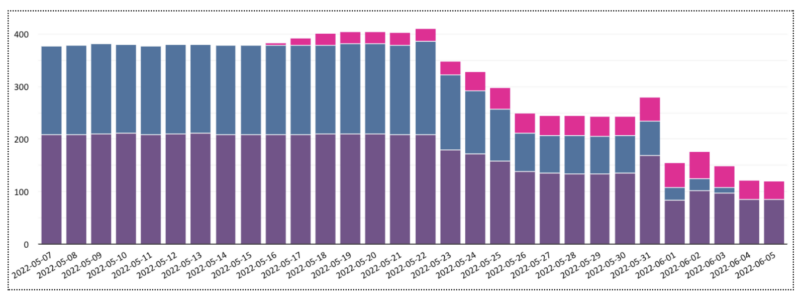
L’infrastructure de départ comportait deux clusters en VM N1, avec trafic réparti à 50/50. On a d’abord ajouté un troisième cluster, en N2D (couleur rose ci-dessous). Puis on y a progressivement transféré le trafic d’un des clusters N1 (celui en violet). On a ensuite remplacé les VM du cluster N1 restant (en bleu) par des N2D. Puis basculé le trafic vers le cluster violet. Les coûts ont évolué comme suit :

Illustration principale © LuckyStep – Adobe Stock
Sur le même thème
Voir tous les articles Cloud
Par La rédaction
2 min.Par Clément Bohic
Par Philippe Leroy
Par Clément Bohic
Par Clément Bohic






{kind=link}