

AWS croise S3 et Lambda pour la transformation de données
AWS ouvre un service qui permet d'associer aux requêtes S3 des fonctions Lambda destinées à la transformation de données.

AWS propose désormais une option alternative aux proxys pour transformer des objets récupérés sur S3. Elle se fonde sur le FaaS Lambda.
Le principe : associer des fonctions à des points d'accès S3 et les invoquer lors des requêtes GET.
AWS en fournit quelques-unes « prêtes à l'emploi ». Elles permettent de :
- détecter et masquer des données personnelles (sur la base du service Amazon Comprehend) ;
- décompresser des données (bzip2, gzip, snappy, zlib, zstandard, ZIP).
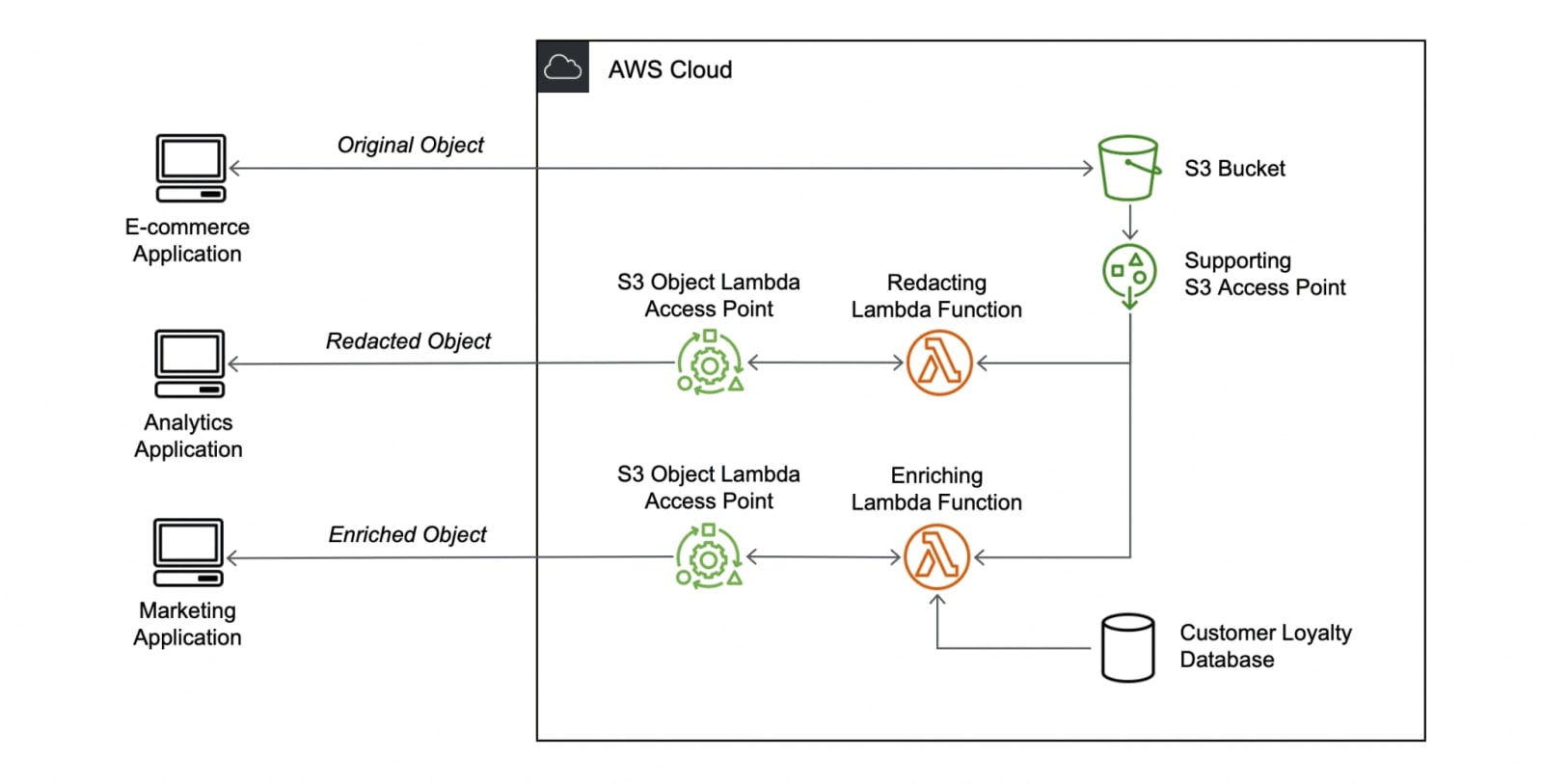
Le service - nommé S3 Object Lambda - est conçu de sorte que les fonctions n'ont pas besoin de permissions pour lire les objets originaux. Principale limite : ces fonctions peuvent s'exécuter pendant 60 secondes au maximum. Elles doivent par ailleurs être rattachées au même compte que le point d'accès associé. Et se trouver dans la même région AWS.
Il est possible, en utilisant les en-têtes HTTP Range et partNumber, de ne récupérer qu'une partie d'un objet. Et éventuellement d'utiliser des connexions parallèles pour télécharger plusieurs parties d'un même objet.
Autre possibilité qu'offre S3 Object Lambda : générer des objets « à la volée ». AWS donne en exemple la création de documents JSON ou CSV à partir du contenu d'une base de données.
Les commandes de haut niveau ne sont pas encore prises en charge dans le CLI AWS. Pour la disponibilité, elle est quasi mondiale, à l'exception de quelques régions AWS en Asie. La facturation dépend des ressources que consomment les fonctions Lambda.
Illustration principale ©
Sur le même thème
Voir tous les articles Data & IA
Par Clément Bohic
6 min.Par Clément Bohic
Par Clément Bohic
Par Clément Bohic
Par Clément Bohic





