Acme : un boost made in Google pour l'apprentissage par renforcement
Publié par Clément Bohic le | Mis à jour le

Avec le framework Acme, DeepMind (filiale de Google) entend favoriser la mise à l'échelle des modèles d'apprentissage par renforcement.
Le problème de la mise à l'échelle se pose aussi avec l'apprentissage par renforcement.
DeepMind le rappelle en introduction d'un rapport relatif à Acme.
La filiale de Google a développé cette boîte à outils (framework + bibliothèque logicielle) pour répondre à la complexification des algorithmes dans cette branche de l'IA.
Elle a défini une architecture modulaire censée favoriser l'entraînement distribué.
Dans le cadre de l'apprentissage par renforcement, cette distribution consiste à faire interagir les agents avec de multiples instances des environnements à partir desquels ils génèrent des données.
Une simple réimplémentation n'est pas toujours suffisante pour effectuer ce passage à l'échelle.
L'architecture modulaire qu'Acme met en ouvre face à cette problématique implique une séparation claire entre les fonctions d'acteur (« actor ») et de critique (« learner »). Le premier explore l'environnement et en tire des expériences. Le second apprend de ces expériences et adapte la politique que suit l'acteur.
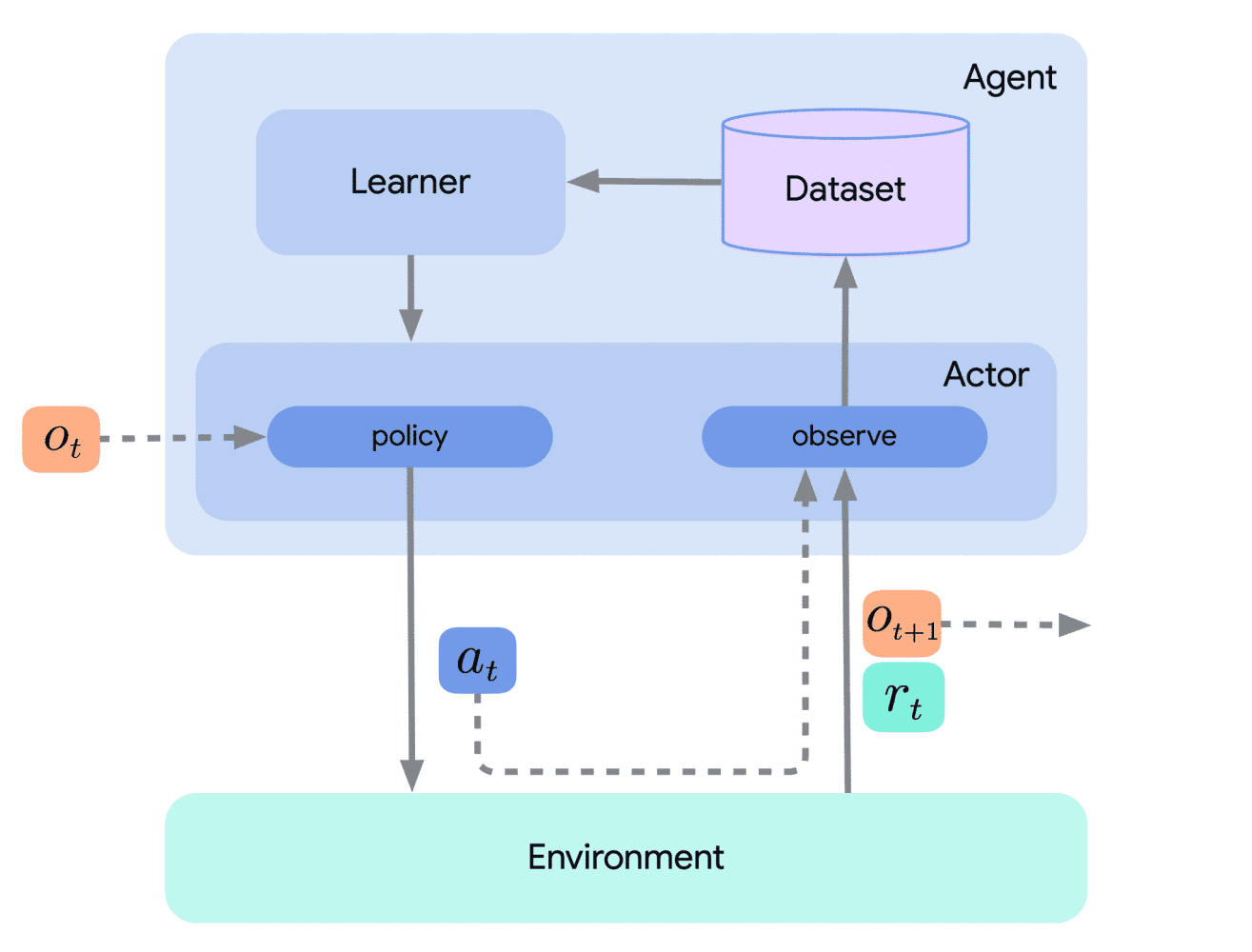
Cette séparation en processus permet de mener l'apprentissage indépendamment de la capacité de collecte de données, les modules communiquant par appels distants. Elle favorise aussi l'exploitation en offline (apprentissage à partir d'un jeu de données fixe).
La boîte à outils contient des agents « prêts à l'emploi ». DeepMind les présente comme des « implémentations de référence » destinées à tirer parti des algorithmes existants. Il s'agit pour le moment de versions monotâches (non parallélisées).
Illustration principale via shutterstock.com