

IBM ouvre ses LLM codeurs Granite : la recette et ses ingrédients
IBM publie, sous licence libre, quatre modèles de fondation Granite pour le code. Voici quelques éléments à leur sujet.

Prenez un LLM. Créez-en une copie. Éliminez les dernières couches de cette copie et fusionnez-la avec l’original, amputé quant à lui de ses premières couches.
Cette recette origine Corée a émergé fin 2023. IBM s’en est servi pour entraîner le plus gros des quatre modèles de fondation qu’il vient de publier sous licence ouverte (Apache 2.0 ; poids et code d’inférence).
Il s’agit de modèles de code. Ils entrent dans la famille Granite, inaugurée l’an dernier avec un premier FM 13B également formé sur du code, mais aussi sur du langage (données académiques, juridiques et financières) et rendu disponible sur watsonx.
Lire aussi : Les LLM Granite 3.0 d'IBM, signes des temps
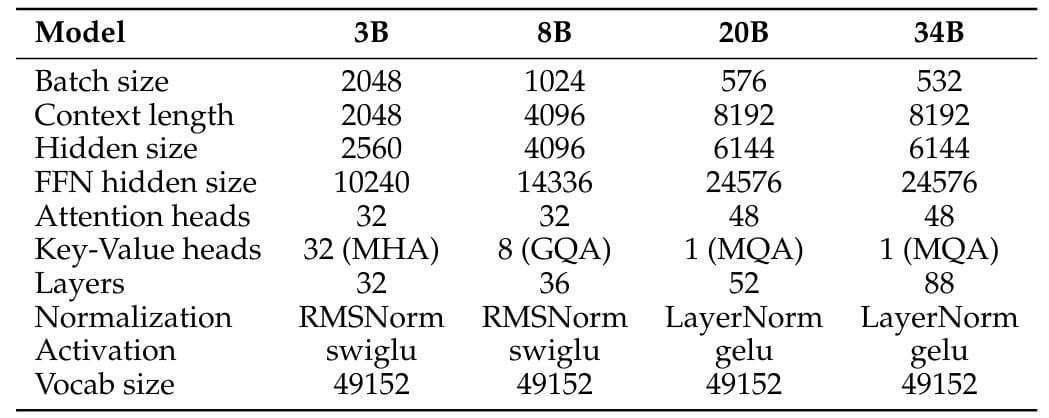
Les modèles mis en open source contiennent respectivement 3, 8, 20 et 34 milliards de paramètres. Chacun est proposé en versions de base et instruct. On peut les trouver sur GitHub, Hugging Face, watsonx.ai et RHEL AI.
Entraînement des modèles Granite : quelles données…
GitHub Code Clean et StarCoderData font partie des datasets utilisés pour le préentraînement. IBM s’en est tenu à 116 langages et a appliqué, entre autres règles de filtrage :
– Suppression des fichiers contenant moins de 25 % de caractères alphabétiques
– Sauf pour XSLT, éliminer les fichiers où la chaîne « <?xml version= » apparaît dans les 100 premiers caractères
– Pour les fichiers HTML, ne garder que ceux pour lesquels le texte visible mesure au moins 100 caractères et représente au moins 20 % du code
– Pour JSON et YAML, ne garder que les fichiers entre 50 et 5000 caractères
Les données d’entraînement comprennent aussi des tickets GitHub, également filtrés (anglais uniquement, pas de commentaires de bots ni de texte généré automatiquement). Pour la partie langage naturel, il y a des datasets d’instructions (FLAN, HelpSteer) ainsi que des ressources académiques (Arxiv, Wikipédia), mathématiques (OpenWeb-Math, StackMathQA) et plus générales (Stackexchange, CommonCrawl).
… et quelles méthodes ?
L’entraînement des modèles de base s’est fait en deux phases :
– Code uniquement
4 000 milliards de tokens pour les modèles 3B et 8B ; 3000 milliards pour le 20B ; 1,4 milliard pour le 34B (pris sur le checkpoint à 1,6 milliard du 20B)
– Code + langage naturel (80 / 20 %)
500 milliards de tokens supplémentaires (données techniques, mathématiques et générales)
L’affinage des modèles Granite instruct a reposé sur les sources suivantes :
– Commits issus de CommitPackFT (version filtrée de CommitPack ; 92 langages sélectionnés)
– MathInstruct et MetaMathQA
– Glaive-Code-Assistant-v3, Self-OSS-Instruct-SC2, Glaive-Function-Calling-v2, NL2SQL11 et des datasets synthétiques d’appels API
– HelpSteer et Open-Platypus
IBM a utilisé deux clusters, respectivement en A100 et H100. Ils estime que ses travaux émis, au global, 455 tonnes d’équivalent CO2. Un calcul basé sur le facteur moyen d’intensité carbone aux USA, sans prendre en compte l’emplacement des datacenters.
IBM exhaustif sur les benchmarks
En génération de code, IBM présente des résultats sur HumanEvalSynthetize (6 langages), MultiPL-E (18 langages), MBPP et MBPP+ (Python), DS1000 (data science en Python), RepoBench et CrossCodeEval (génération niveau repo) et SantaCoder-FIM (infilling).
Autres benchmarks effectués :
– Explication de code (HumanEvalExplain)
– Édition et traduction de code (CanItEdit, HumanEvalFix)
– Compréhension et exécution de code (CRUXEval)
– Raisonnement mathématique (MATH, GSM8K, SAT, OCW)
– Appel de fonctions et d’outils (BFCL)
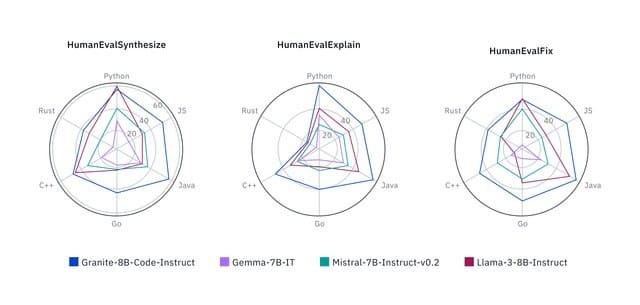
Performances sur la série HumanEval
Illustration principale © bestforbest – Adobe Stock
Sur le même thème
Voir tous les articles Data & IA
Par Clément Bohic
6 min.Par Clément Bohic
Par Clément Bohic
Par Clément Bohic
Par Clément Bohic





