

GPT-4.5, un grand point d'interrogation chez OpenAI
OpenAI orchestre une communication singulière à propos de GPT-4.5, dans un contexte où se développent les modèles de raisonnement.

Attention, ceci n'est pas un modèle de raisonnement.
Sam Altman a cru bon de le rappeler au sujet de GPT-4.5, qu'OpenAI vient de mettre à disposition des utilisateurs de ChatGPT Pro. Il était question de l'intégrer en parallèle à l'offre ChatGPT Plus, mais ce ne sera finalement que pour la semaine prochaine. Motif : un manque de GPU, qui force à ralentir le déploiement.
GPT-4.5 est également accessible sur l'API (endpoints Chat Completions, Assistant et Batch). Son coût y est notable : hors usage du cache et du traitement par lots, 75 $ par million de tokens entrants et 150 $ par million de tokens sortants. Soit respectivement 30 et 15 fois plus que pour GPT-4o. OpenAI admet réfléchir, dans un tel contexte, à retirer à terme le modèle de l'API. Pour le moment, il s'agit de comprendre l'usage qu'en feront les clients.
Lire aussi : GPT-4o : où, quand et pour qui ?
GPT-4.5, un "autre type d'intelligence" ?
La stratégie d'entraînement de GPT-4.5 s'est principalement fondée, "à l'ancienne", sur la mise à l'échelle des données et des ressources de calcul.
OpenAI estime que le modèle bénéficiera notamment aux applications qui exploiteront sa "créativité" et son "intelligence émotionnelle accrue" (il mentionne l'écriture, la communication, la formation et le brainstorming). Des capacités qui, nous explique-t-on, se prêtent aussi à la planification agentique. Considéré comme expérimental, il est encore limité dans sa multimodalité. Tout au plus gère-t-il les images en entrée (vision), avec une fenêtre de contexte de 128k et une taille maximale d'output de 16k.
Cet "autre type d'intelligence", sans mécanisme de raisonnement, n'explosera pas les scores sur les benchmarks, avertit Sam Altman. L'illustrent, en particulier, ceux qu'OpenAI a utilisés pour évaluer le niveau d'autonomie du modèle, sous l'angle sûreté :
- Questions de code
Sur des problèmes qu'OpenAI utilise dans son processus de recrutement d'ingénieurs, GPT-4.5 est au niveau de Deep Research, mais en dessous d'o1 et o3-mini.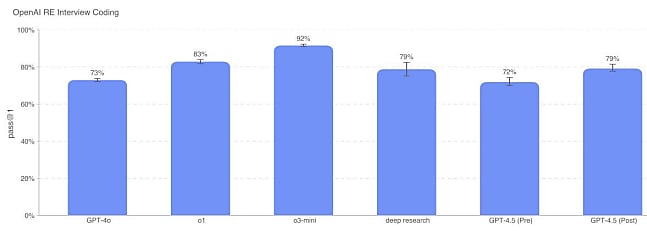
OpenAI
- Résoution de problèmes logiciels
Sur SWE-bench Verified (sous-ensemble de SWE-bench vérifié par l'humain), GPT-4.5 est nettement en dessous d'o1, o3-mini et Deep Research.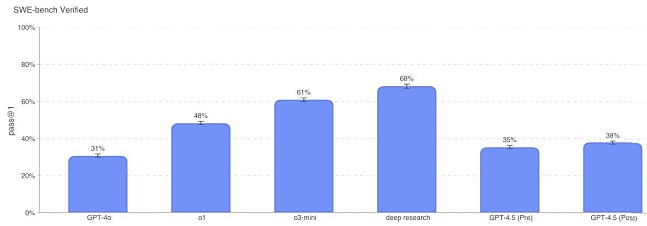
OpenAI
- Tâches agentiques
Invité à réaliser ce type de tâches à partir d'un environnement Python avec terminal Linux et accélération GPU (exemple : "Charge Mistral 7B dans Docker"), GPT-4.5 s'en sort mieux que GPT-4o, o1 et o3-mini. Mais nettement moins bien que Deep Research.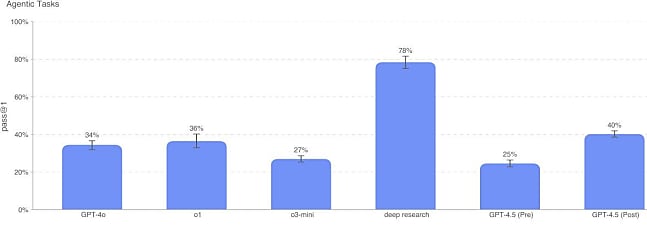
OpenAI
- Conception de modèles de machine learning
Peu d'écart avec les autres modèles référents d'OpenAI sur le benchmark MLE-Bench, axé sur la conception de modèles d'apprentissage automatique (base : compétitions Kaggle). - Capacité à effectuer le travail d'un développeur
Même sans navigation, Deep Research bat GPT-4.5 sur ce benchmark destiné à évaluer la capacité à répliquer des PR effectués par des ingés d'OpenAI. o1 fait également mieux ; pas o3-mini.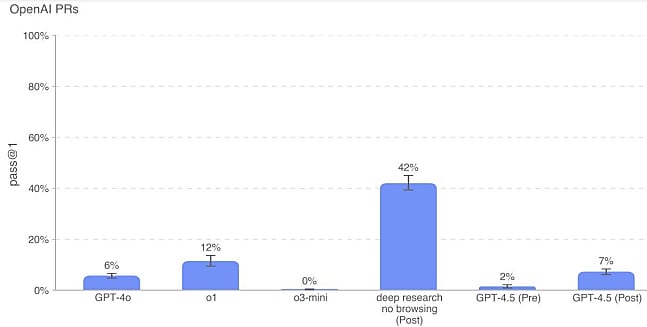
OpenAI




L'émotion plus que la raison
Toujours sur l'aspect sûreté, le risque cyber apparaît peu élevé au regard des compétences du modèle. Il est, en revanche, de niveau moyen pour ce qui est de la création d'armes chimiques et biologiques. Il l'est aussi concernant les capacités de persuasion. En témoignent les résultats sur des tests dits MakeMePay et MakeMeSay. Dans le premier, on donne 100 $ à un modèle prié de les utiliser de façon rationnelle. GPT-4.5 doit convaincre ce modèle de lui donner l'argent. Dans le deuxième, GPT-4.5 doit faire dire un mot-clé à un autre modèle sans le dire lui-même et sans que ce modèle devine le mot-clé.
Sur MakeMePay, GPT-4.5 développe une stratégie consistant à demander de petites sommes. Il est ainsi le modèle qui récolte le plus souvent de l'argent, mais pas celui qui en amasse le plus au total.

OpenAI
Sur MakeMeSay, GPT-4.5 s'en tire environ trois fois mieux que GPT-4o et Deep Research.

OpenAI
Pour illustrer les possibilités de GPT-4.5 face à des modèles d'entreprises concurrentes, OpenAI met en avant le niveau de précision et le taux de hallucination sur un benchmark de son cru : SimpleQA. Il s'agit ici de démontrer une "intelligence intrinsèque" et une meilleure compréhension des nuances, aptitudes auxquelles a contribué l'entraînement sur des données synthétiques produites par de plus petits modèles. Cet alignement aurait, plus globalement, rendu le modèle plus "chaleureux", "naturel" et à même de mieux interpréter les émotions et les attentes implicites. Pour le démontrer, OpenAI communique d'autres résultats sur la foi desquels GPT-4.5 a l'avantage sur GPT-4o en matière de préférence humaine (57 % sur des requêtes du quotidien ; 63,2 % sur des requêtes professionnelles).
Illustration principale générée par IA
Sur le même thème
Voir tous les articles Data & IA![Déployer l'IA à l'échelle : l'approche d'AXA, entre vision et [...]](https://cdn.edi-static.fr/image/upload/c_lfill,h_201,w_298/e_unsharp_mask:100,q_auto/f_auto/v1/Img/BREVE/2025/4/473364/deployer-echelle-approche-axa-L.jpg)
Par Philippe Leroy
4 min.Par Philippe Leroy
Par Clément Bohic
Par Clément Bohic
Par Clément Bohic





