

Comment Pinterest a monté son PaaS Kubernetes
Pinterest a entrepris de moderniser son infrastructure de calcul avec Kubernetes. Des API à la sémantique, il y a greffé ses outils et processus.

Comment moderniser une plate-forme de calcul ? En adoptant une approche PaaS fondée sur Kubernetes. Pinterest a en tout cas choisi cette voie pour développer PinCompute.
Le projet, échelonné sur plusieurs années, vise à fournir une API de compute managée couvrant 90 % des use cases internes. Il prend la forme d’un PaaS multilocataire régionalisé basé sur Kubernetes. Chaque région a son cluster hôte (plan de contrôle) et ses clusters zonaux (workloads). L’architecture s’aligne sur le domaine de panne défini par le fournisseur cloud – en l’occurrence, AWS.
Lire aussi : Kubescape monte en grade à la CNCF
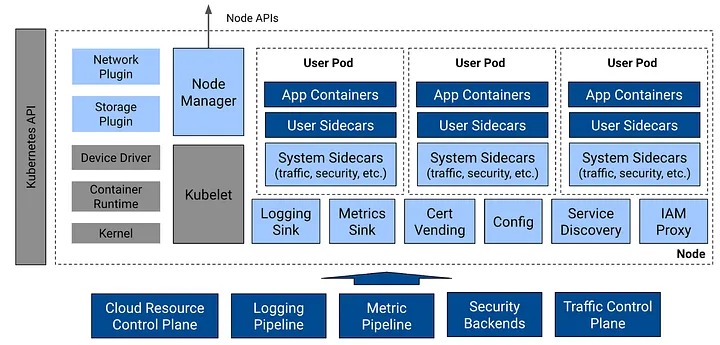
Les ressources personnalisées de Kubernetes permettent de définir les types de workloads supportés. Le plan de contrôle des clusters zonaux associe des opérateurs propriétaires et des opérateurs open source.

Pinterest a réparti ses use cases en trois catégories : calcul et déploiement généraux, planification non préemptive et services d’infrastructure. Pour gérer la première, PinCompute introduit un ensemble de primitives : PinPod, PinApp et PinScaler.
PinPod s’appuie sur la primitive Pod de Kubernetes et y ajoute des capacités spécifiques. Entre autres, la mise à jour par conteneur, la persistance et les sidecars managés.
Reposant sur PinPod, PinApp gère les applications et services toujours en exécution. Il supporte des primitives natives comme Deployments et ReplicaSets, avec des extensions, en particulier sur la sémantique de déploiement. PinScaler gère sa mise à l’échelle.

Pour la planification non préemptive, Pinterest a conçu trois primitives : PinterestJobSet (basé sur Jobs), PinterestTrainingJob (basé sur TFJob et PyTorchJob, pour l’entraînement distribué) et PinterestCronJob (basé sur CronJob).
Pour les services d’infrastructure, il y a PinterestDaemon (basé sur Daemonset) et un sidecar propriétaire pour supporter différents modèles de déploiement. Les composants mutualisables entre locataires sont déployés en tant que démons (une copie par nœud). Les autres, en tant que sidecars.
Lire aussi : Pourquoi OpenStack rejoint la Fondation Linux
Réduire la pression sur Kubernetes… et sur les développeurs
PinCompute donne accès à trois types d’API : workload (pour effectuer des opérations CRUD), débogage et visibilité. Superposées à celles de Kubernetes, elles assurent une UX uniforme entre back-end et incluent un cache pour limiter la charge sur le serveur de l’orchestrateur. Elles présentent par ailleurs le modèle de données de façon simplifiée, adaptée aux problématiques logicielles de Pinterest. Cela réduit la courbe d’apprentissage de l’infrastructure pour les développeurs tout en minimisant les transferts de données.
PinCompute exploite trois niveaux de ressources (réservées, à la demande et préemptibles). La planification des workloads au niveau des zones se fait dans le plan de contrôle régional. Celle au niveau des nœuds se fait dans les clusters zonaux. Elle implique là aussi des extensions, propriétaires et communautaires, en complément au planificateur de Kubernetes.
PinCompute utilise des plug-in propriétaires pour le réseau comme pour la journalisation à partir des volumes de stockage. Les conteneurs sont connectés à de nombreux éléments de l’infrastructure de Pinterest, dont les plans de contrôle sont indépendants.

Au rang des outils made in Pinterest, il y a aussi un système de débogage temps réel. Il utilise des API propriétaires au niveau des nœuds pour découpler les tâches des canaux critiques tels que le Kubelet.
Chaque cluster est censé pouvoir supporter 3000 nœuds, 120 000 pods et 1000 opérations de modification de pod par minute. Le tout avec une latence inférieure à 25 secondes pour 99 % des workloads et une élasticité horizontale.
L’objectif de niveau de service repose sur deux indicateurs : disponibilité des API (99,9 % pour celles liées à l’orchestration de workloads critiques) et temps de réponse de la plate-forme (réconciliation des plans de contrôle entre quelques secondes à quelques dizaines de secondes selon la complexité et les exigences). Pour les workloads de niveau réservé, il existe un SLO sur la vitesse de lancement.
Illustration principale © jakir – Adobe Stock
Sur le même thème
Voir tous les articles Cloud
Par Clément Bohic
3 min.Par Clément Bohic
Par Clément Bohic
Par La rédaction
Par Clément Bohic








{kind=link}