

Comment Uber a déployé Kerberos à l'échelle
En 2016, Uber amorçait le déploiement de Kerberos, initialement pour sa plate-forme Hadoop. Le périmètre s’est bien élargi depuis.

Hadoop, bonne occasion pour déployer Kerberos ? Ce fut en tout cas le point de départ chez Uber, en 2016. Depuis lors, le périmètre s’est étendu à bien d’autres systèmes, dont Kafka, Spark et Zookeeper.
Outre la prise en charge native de Hadoop, l’entreprise américaine a trouvé au protocole d’autres atouts qui lui ont fait mettre le pied à l’étrier. Parmi eux :
– Des authentifiants jamais transmis sous forme non chiffrée
– Des tickets a durée de vie limitée
– Il s’agit d’un protocole SSO (un client s’authentifie une fois sur le KDC et peut ensuite accéder à toute ressource protégée, aussi longtemps que le ticket est valide)
– Authentification mutuelle de tous les clients et les serveurs/services
– Possibilité d’intégrer, dans les tickets, des informations sur les hôtes, de sorte que la compromission de l’un d’entre eux n’affecte pas les autres
– Possibilité de construire une hiérarchie de domaines Kerberos indépendants en établissant des relations de confiance entre eux
Le déploiement de Kerberos au niveau de l’orga data a impliqué de standardiser les types de comptes. Il en a résulté la nomenclature suivante :
> Comptes d’utilisateurs, pour les employés
> Comptes de services
Pour exécuter les pipelines quotidiens. Chacun a un groupe Linux associé. Les membres du projet peuvent y être ajoutés et ainsi accéder aux données écrites par le compte de service.
> Comptes pour les systèmes qui composent l’infrastructure
> Comptes dits « service-hôte »
Ils permettent de circonscrire un principal et son keytab à une combinaison [service, hôte]. En cas de compromission du keytab, il ne faut alors modifier que le keytab de cette paire.
Uber a mis en place un processus de création de comptes en self-service. Les équipes propriétaires de services y sont dirigées lorsqu’elles embarquent de nouveaux datasets ou jobs ETL, et que le service n’a pas encore de compte. Un keytab est généré en parallèle, puis distribué.
Un Kerberos sur socle OpenLDAP
L’orga data a opté pour un setup Kerberos dédié. En l’occurrence, l’implémentation MIT, avec socle OpenLDAP. Elle stocke les principaux pour les comptes d’hôtes, de services et de systèmes. Les comptes des employés peuvent s’y authentifier pour accéder aux ressources, avec Active Directory en renfort. Pour réduire la charge sur ce dernier, un processus de synchronisation et de propagation des utilisateurs et de groupes sur toute la stack data a été mis en place.
L’infrastructure gérant l’authentification de plus de 100 000 principaux, Uber a déployé de multiples instances des serveurs Kerberos dans toutes les régions. Pour la haute disponibilité, il a fait en sorte que tous les nœuds fournisseurs contiennent la même information et soient ainsi « échangeables ».
Chaque provider forme un cluster indépendant avec plusieurs nœuds consommateurs sur lesquels ses données sont répliquées. OpenLDAP assure cette opération. Pour éviter les conflits d’écriture entre providers, on n’en exécute qu’un à la fois en lecture-écriture (les autres restent en lecture seule).

Dans chaque cluster, les nœuds consommateurs font l’objet d’un enregistrement DNS lié à la région (kdc.region-1.data.uber, kdc.region-2.data.uber, etc.). Une manière plus simple, pour les clients, de s’authentifier, que d’utiliser des noms d’hôtes.
Le défi de l’automatisation
La mise en place de Kerberos entraîna, pour l’équipe data, une nouvelle tâche : enregistrer les principaux et distribuer les keytabs. L’approche initiale impliquait une connexion manuelle aux hôtes kadmin. Avec le surcroît de travail que cela induisait, en plus des problèmes de sécurité (transmission des authentifiants « de main à main » sans processus défini, risques de suppresion ou de corruption de données de prod).
Dans ce contexte, Uber a conçu un pipeline de distribution (KDP). Son rôle, dans les grandes lignes :
– Surveiller les changements de métadonnées sur des sources prédéfinies et les utiliser comme input pour créer/supprimer des principaux
– Créer/supprimer les keytabs correspondants et les mettre à disposition dans un coffre-fort
– Fournir un client capable de récupérer les keytabs
Pour les équipes propriétaires des services, l’enregistrement nécessite de définir une configuration (environ 3 lignes, nous dit-on) et d’ajouter un appel dans la codebase (3 lignes également).
Deux grandes catégories d’usages se distinguent pour les keytabs. D’une part, les services utilisant des comptes service ou système pour exécuter des tâches ou des pipelines automatisés. De l’autre, les services à grande échelle (HDFS, YARN…) qui exploitent des principaux « service-hôte » pour l’authentification pendant l’ajout de nœuds à des clusters de services.
À partir de ces use cases, on a intégré l’automatisation KDP à trois systèmes : AD, Odin (système interne d’orchestration de service à état) et Peloton (idem pour le stateless).

Bridge, Manager, Fetcher : un pipeline à trois composantes
Première composante du pipeline, Kerberos-Bridge est une passerelle avec les fournisseurs externes de métadonnées. Périodiquement, elle récupère ces dernières et, en conséquence, met à jour les « entrées keytab » correspondantes dans un dépôt Git interne. Ces entrées ne sont alors pas encore des keytabs : elles contiennent de quoi les créer (nom du principal et information de propriétaire, notamment).
Utiliser Git permet de tirer parti de fonctionnalités comme l’historique (pour l’audit), la restauration, le contrôle d’accès et la révision par les pairs.

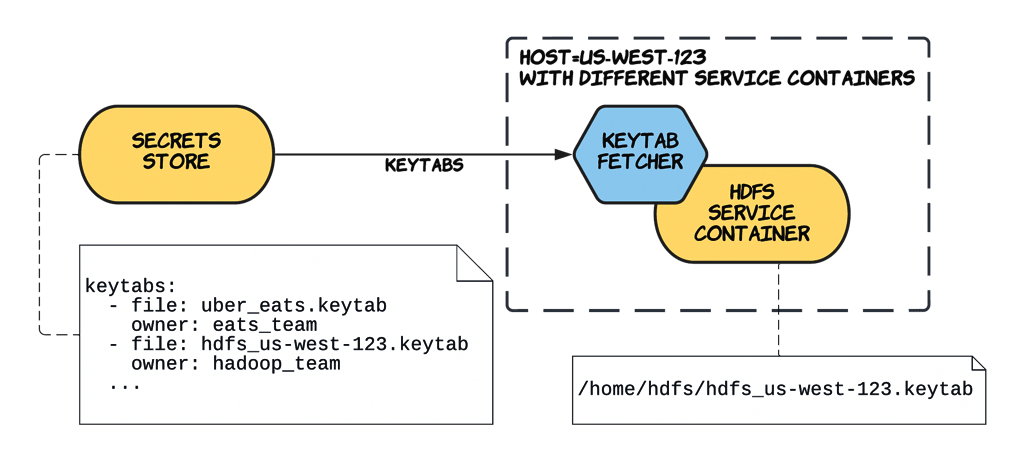
Exécuté dans le cœur du pipeline, aux côtés de KDC, KDC Admin (kadmin, client pour administrer principaux et keytabs) et OpenLDAP, Keytab-Manager fait le liant avec les services internes. Il surveille le dépôt Git et, lorsqu’il détecte un changement, crée un principal du même nom que l’entrée. Puis il génère un keytab correspondant, stocké dans le magasin de secrets.

Les agents d’orchestration – déployés sur toute la flotte Uber – utilisent la bibliothèque Keytab-Fetcher pour récupérer les keytabs et les mettre à disposition des conteneurs de services.

Sécurisé avec SPIRE, le KDP distribue plus d’un millier de keytabs par semaine.
Illustration principale © Tee11 – Adobe Stock
Sur le même thème
Voir tous les articles Cybersécurité
Par Clément Bohic
3 min.Par Clément Bohic
Par Clément Bohic
Par Clément Bohic
Par Alain Clapaud






{kind=link}