


Le Machine Learning pour piloter le datacenter du futur ?
Une étude montre qu'une intelligence artificielle (IA) peut bâtir la configuration logicielle idéale pour répondre à des conditions de fonctionnement données. Sans intervention humaine.

Une intelligence artificielle peut-elle être plus efficace qu'un humain pour bâtir et reconfigurer des architectures logicielles ? C'est la question très concrète que pose une équipe de l'université de Lancaster, au Royaume-Uni, dans une étude présentée à la conférence Usenix, début novembre. Et les premiers résultats qu'elle fournit montrent que la piste est intéressante. « Les approches conventionnelles pour les architectures logicielles auto-adaptables requièrent des experts humains qui vont spécifier des modèles, des règles et des processus par lesquels le logiciel va s'adapter à son environnement », rappellent les chercheurs. Qui proposent eux une approche en rupture, basée sur la Machine Learning.

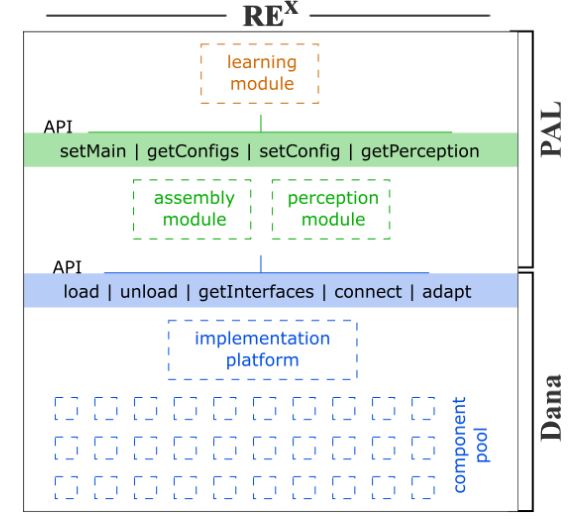
La démarche repose sur REx (pour runtime emergent software systems), une plate-forme au sein de laquelle « toutes les décisions portant sur l'assemblage et l'adaptation du logiciel sont prises par la machine ». Cette plate-forme se décompose en trois éléments. Tout d'abord, un langage dédié, baptisé Dana (et librement disponible), qui permet de créer de petits composants logiciels et de les réarranger au sein de systèmes logiciels. Un framework, appelé PAL et bâti à partir de Dana ensuite ; PAL contrôle la découverte, l'assemblage des composants et assure le monitoring des environnements. Et, enfin, un algorithme de Machine Learning, alimenté en données par PAL. « Ce module découvre des corrélations entre des assemblages particuliers et la façon dont le système perçoit son propre bien-être, sous différent stimuli externes qu'il s'agisse de modèles de sollicitations ou de conditions de déploiements, comme le taux d'occupation des CPU », expliquent les chercheurs. C'est cet attelage, communicant via des API, qui, sur la base de micro-variations des composants logiciels d'une architecture, permet de trouver la configuration idéale, sur la base de mesures comme le temps de réponse ou le taux de compression.
Serveur Web assemblé et optimisé par Machine Learning
Au-delà de la démonstration théorique, les chercheurs ont testé leur approche sur un serveur Web. « Nous montrons comment un système peut être assemblé de façon autonome à partir de composants découverts par la plate-forme et comment ce système peut par la suite être optimisé pour ses tâches via de nouveaux assemblages avec des composants alternatifs », écrivent les chercheurs qui précisent que des designs différents émergent si les conditions changent. Notons que le système démarre sans connaissance ni des tâches qui l'attendent (il ne 'sait' pas qu'il est un serveur Web), ni des conditions dans lesquelles il va être plongé.
Dans cette expérience, menée sur un rack à base de Xeon et animé par Ubuntu Server, le serveur Web est bâti à partir de plus de 30 composants, dont une quinzaine sont soumis à des variations. « A partir de ce jeu de composants, il existe 42 assemblages possibles, chacun d'eux donnant naissance à un serveur Web fonctionnel mais avec un comportement différent de celui découlant des autres possibilités », détaillent Barry Porter, Matthew Grieves, Roberto Rodrigues Filho et David Leslie. Selon ces derniers, la convergence vers le montage logiciel optimal, dans des conditions données, est « rapide ». Et peut être améliorée via l'ajout d'un module permettant de mémoriser les configurations optimales pour tel environnement, afin d'épargner au système la nécessité de réapprendre ce qu'il a déjà découvert.
« Retirer toute implication humaine »
Avec ces travaux, l'équipe de l'université de Lancaster ouvre en tout cas un nouveau champ de recherche pour les grands opérateurs de datacenters, comme ceux du Cloud, avec des architectures ultra-modulaires et surtout capables de découvrir seules leur configuration optimale. « Notre étude revient à quasiment retirer toute implication humaine dans la façon dont des systèmes auto-adaptatifs se comportent [.] et à produire des systèmes qui réagissent à leurs conditions de fonctionnement et à la façon dont ils perçoivent leur comportement dans ces conditions », résument les chercheurs. Ces derniers précisent qu'ils vont poursuivre leurs travaux sur d'autres types d'applications et, également, s'atteler à la génération automatique - par la plate-forme de Machine Learning - des variantes de composants.
A lire aussi :
Lire aussi : 10 tendances Tech à suivre en 2023
Une IA est capable de concevoir son propre chiffrement
Lire aussi : Chronique Instinct Cloud => Clouds Publics : fondations pour l'Intelligence Artificielle
IA : comment IBM Watson aide les conseillers clientèle du Crédit Mutuel
L'IA va devenir une priorité des DSI, dit le Gartner
Crédit photo : VisualHunt
Sur le même thème
Voir tous les articles Cloud
Par Clément Bohic
5 min.Par Philippe Leroy
Par Clément Bohic
Par Clément Bohic
Par Clément Bohic





{kind=link}