L'approche d'Apple pour des LLM frugaux en mémoire
Publié par Clément Bohic le | Mis à jour le
Des chercheurs d’Apple proposent un modèle d’inférence adapté aux environnements dont les ressources mémoire sont restreintes.
Comment faire tourner, avec le moins de latence possible, un LLM qui excède la capacité mémoire disponible ? Des chercheurs d'Apple ont récemment signé un article à ce sujet.
Au coeur de leurs travaux, un mécanisme d'optimisation des transferts de données de la flash vers la RAM. Il implique, entre autres techniques, la prédiction de matrices creuses, l'usage d'une fenêtre glissante et la concaténation de valeurs. L'idée était à la fois de réduire les volumes de transferts et d'optimiser les performances en lecture.
La présence de matrices creuses (sparsity, traduit par « parcimonie ») est caractéristique des FFN (réseaux de neurones à propagation avant : l'information ne transite que dans un sens, par opposition à la circulation bidirectionnelle entre les couches des RNN). Les chercheurs ont exploité cette propriété pour ne charger que le nécessaire en RAM. En l'occurrence, uniquement les paramètres à input non nul... et ceux dont on peut prédire que l'output sera non nul (un modèle spécifique est utilisé à cet effet).
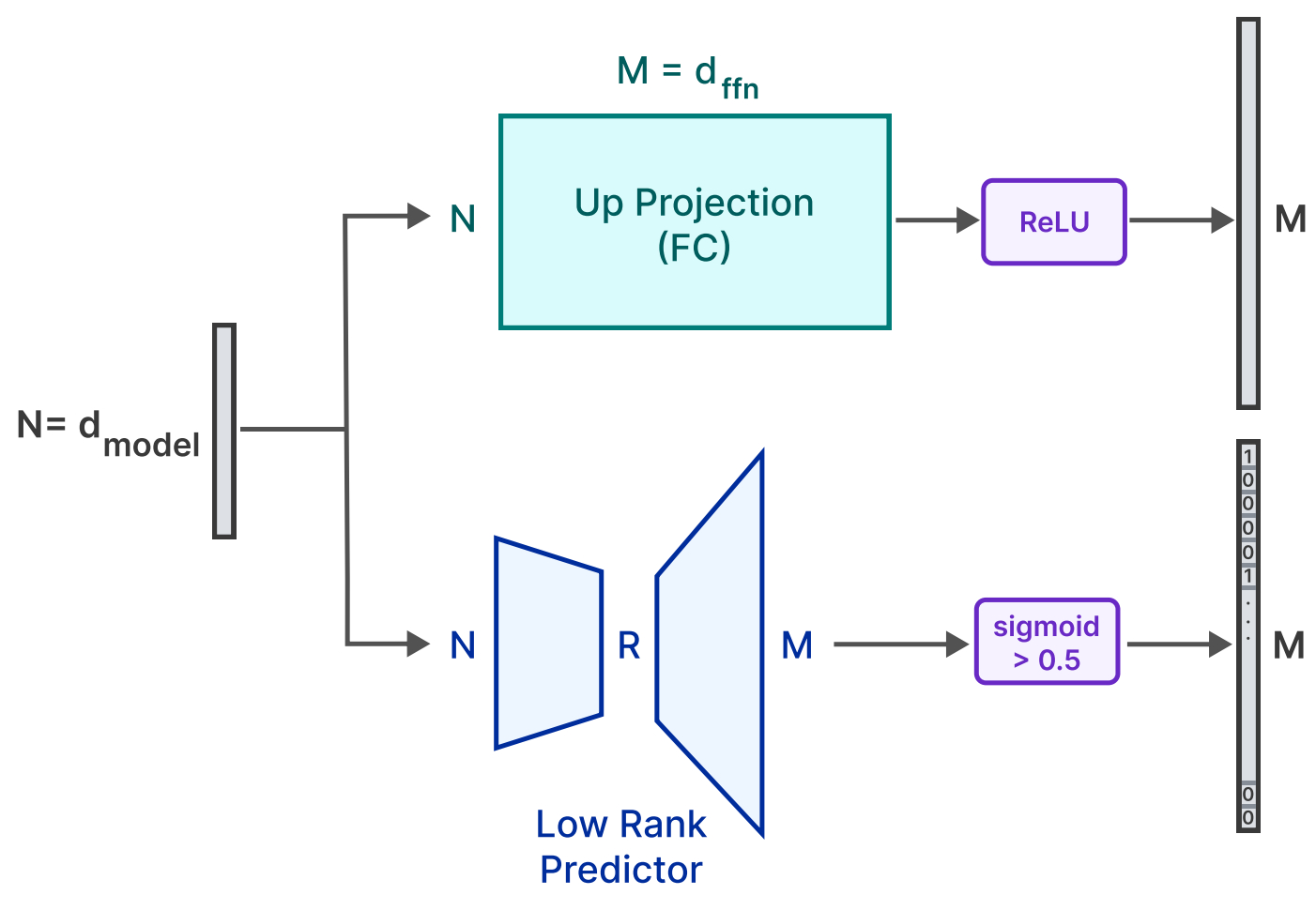{kind=link}
La technique de fenêtrage réduit les requêtes I/O en réutilisant des neurones précédemment activés.
La concaténation de lignes et de colonnes permet de constituer de plus gros fragments de données, favorisant l'augmentation des débits de la flash.
Seul les poids d'attention sont conservés en permanance en RAM. Cela représente environ un tiers de la taille des LLM testés. Ici, en l'occurrence, OPT 6.7B et une version « sparsifiée » de Falcon 7B.
Le tableau ci-dessous montre l'évolution des performances de transfert de données pour un modèle OPT 6.7B en format 16 bits sur un M1 Max avec SSD 1 To.
Le graphique suivant illustre les gains en latence par rapport à la plus efficace des baselines. Celle-ci implique, selon les termes de l'expérience, de charger la moitié du modèle en RAM à chaque prédiction.
Illustration principale © Siqarus - Adobe Stock