


Machine learning : Meta tente une approche « privacy »
Meta travaille sur une approche de l'apprentissage automatique fédéré s'appuyant sur la « vie privée différentielle ».

Intel, HPE, Google... Qui n'a pas son architecture d'apprentissage fédéré ? Tous les trois ont exploré cette approche dont le concept fondamental peut se résumer ainsi : comment entraîner des modèles sans centraliser les données utilisées à ces fins ? En toile de fond, des logiques de réduction des coûts, des goulets d'étranglements techniques, des problèmes de sécurité et des enjeux juridiques.
Le premier y a couplé, sous la bannière du Private AI Collaborative Research Institute, la dimension de l'informatique dite « confidentielle ». Avec le chiffrement homomorphe comme pilier. Le second y a notamment associé une brique blockchain destinée à décentraliser complètement le partage des connaissances qu'acquièrent les modèles. Quant au troisième, il mise, entre autres, sur la notion de « vie privée différentielle ». En l'occurrence, l'exploitation de techniques mathématiques pour rendre le plus anonymes possible les résultats produits en local.
Meta creuse aussi cette piste. Ses recherches en la matière ont fait l'objet d'un rapport récemment publié. Y est décrite une architecture appliquée aux réseaux de neurones et censée éliminer plusieurs problèmes que pose l'apprentissage fédéré. Notamment sur les enjeux suivants :
Lire aussi : De Llama 3 à Llama 4 : ce qui change, ce qui reste
- Assurer une distribution équilibrée des données d'entraînement, normaliser les fonctions des modèles et évaluer leurs performances
- Garder les différentes copies du modèle à jour, maintenir suffisamment d'appareils dans la boucle et limiter la durée des cycles d'entraînement
- Anonymiser les logs sans réduire leur qualité
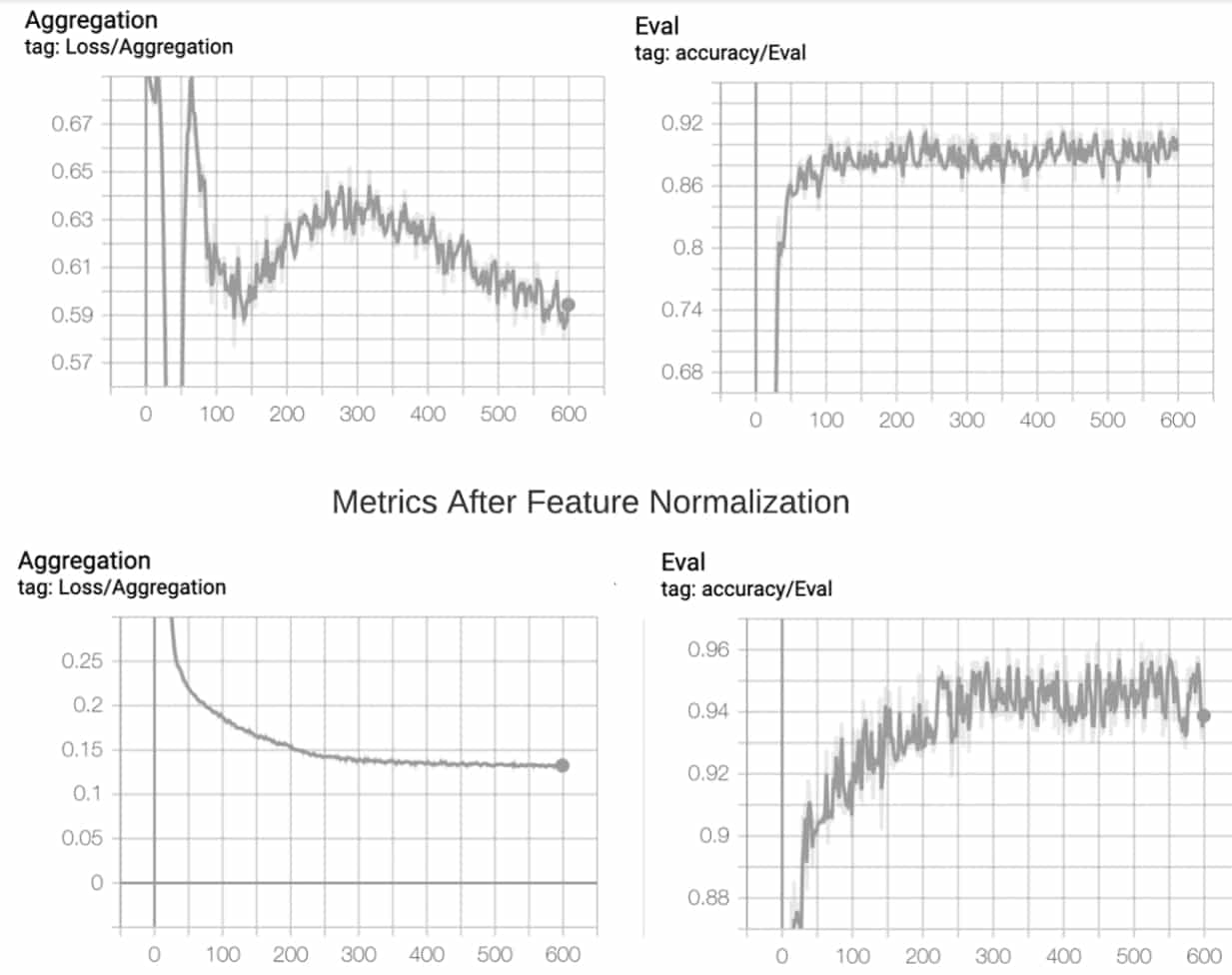
Se rapprocher des performances de l'apprentissage centralisé
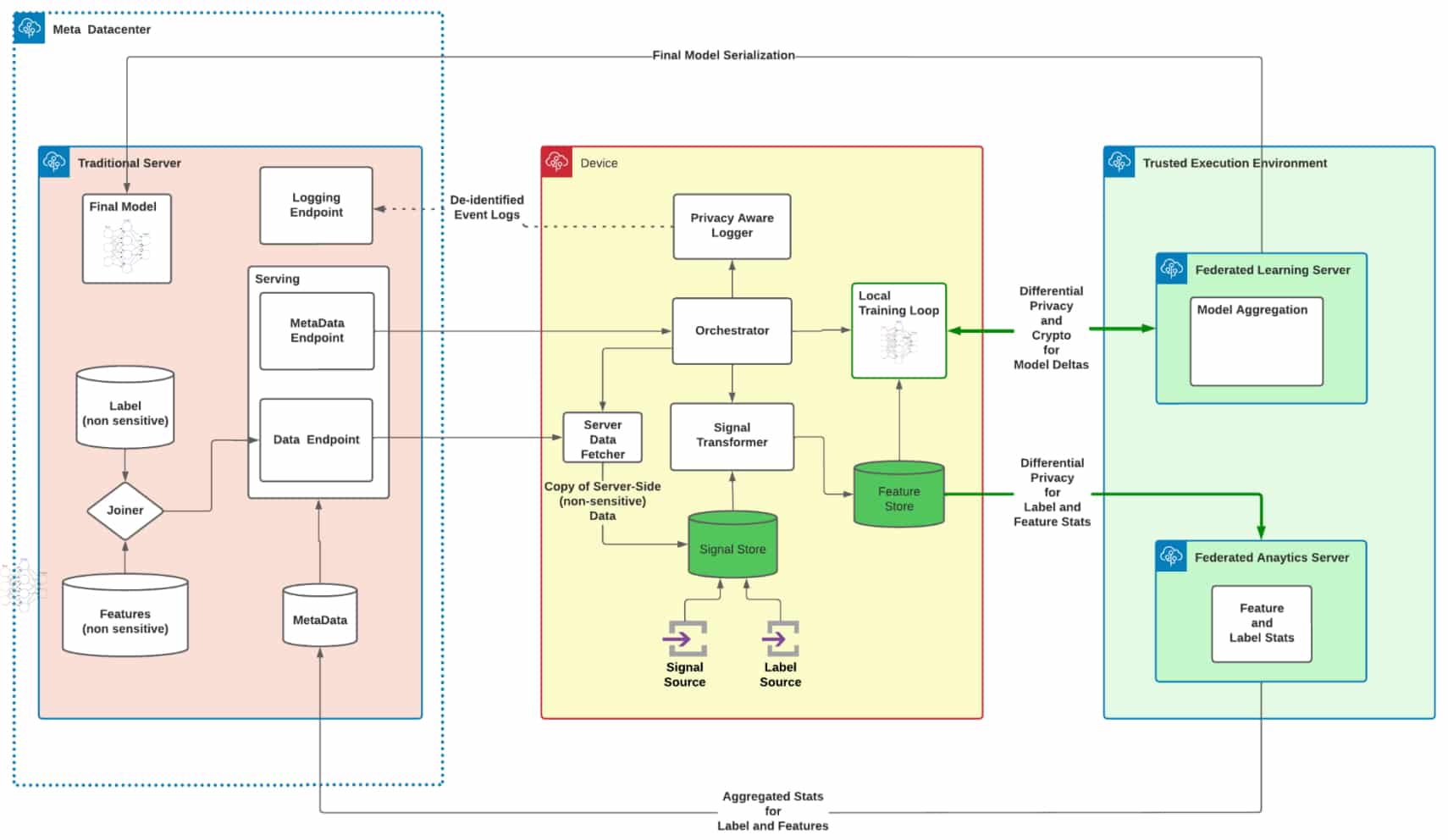
L'architecture - schématisée ci-dessous - implique un environnement d'exécution sécurisé comportant deux serveurs. L'un gère, en boucle, la distribution des copies du modèle, l'agrégation de leurs poids et la mise à jour du modèle central. L'autre aide à normaliser les fonctions et à équilibrer les données d'entraînement. Sur ce dernier point, il doit pallier le fait qu'aucune information n'est partagée entre appareils et que le calcul de la rétropropagation se fait en local.

L'environnement d'exécution sécurisé se présente comme une extension des devices. Il travaille ainsi en tandem avec eux pour l'évaluation des fonctions et des étiquettes. Les statistiques qui en résultent sont stockées dans un même magasin de données. Au bout de la chaîne, elles atterrissent dans les datacenters de Meta, sous une forme agrégée censée ne pas permettre la réidentification d'utilisateurs.

Pour ce qui est de garder les copies du modèle à jour, Meta a fait en sorte qu'un maximum de fonctions ne dépendent pas d'un update d'application. Il a, par exemple, implémenté certaines fonctions dans un script torch plutôt qu'en code natif.
Illustration principale © Siarhei - Adobe Stock
Sur le même thème
Voir tous les articles Data & IA
Par Clément Bohic
8 min.Par Clément Bohic
Par Clément Bohic
Par Clément Bohic
Par Rémy Mandon *








{kind=link}
{kind=link}