SageMaker : comment la « machine à IA » d'AWS évolue
Publié par Clément Bohic le - mis à jour à

Gouvernance, données géospatiales, shadow testing... Le point sur quelques-uns des derniers éléments dont AWS a doté son offre SageMaker.
Connecter directement des applications SaaS à SageMaker ? Pas tout à fait, mais on s'en approche. On peut désormais en ajouter une quarantaine comme sources dans l'outil de préparation de données Data Wrangler.
AWS a officialisé, dans le cadre de sa conférence re:Invent, cette jonction qui s'appuie sur le service d'intégration AppFlow et le catalogue de Glue. Elle permet de parcourir tables et schémas en utilisant l'explorateur SQL de Data Wrangler.
{kind=link}

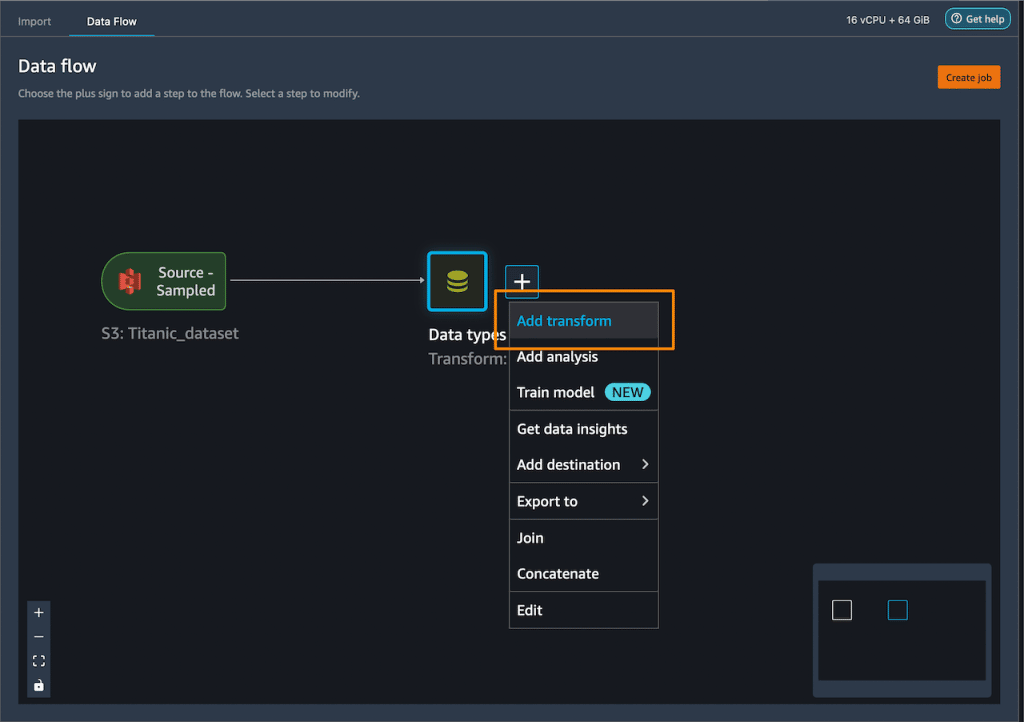
Autre ajout à Data Wrangler : la prise en charge de l'inférence en flux et en lot. Plus précisément, la capacité à réutiliser les workflows de transformation de Data Wrangler au sein des pipelines d'inférence de SageMaker. Une fonctionnalité qui repose sur SageMaker Autopilot et qui s'appuie sur des notebooks personnalisés.
{kind=link}

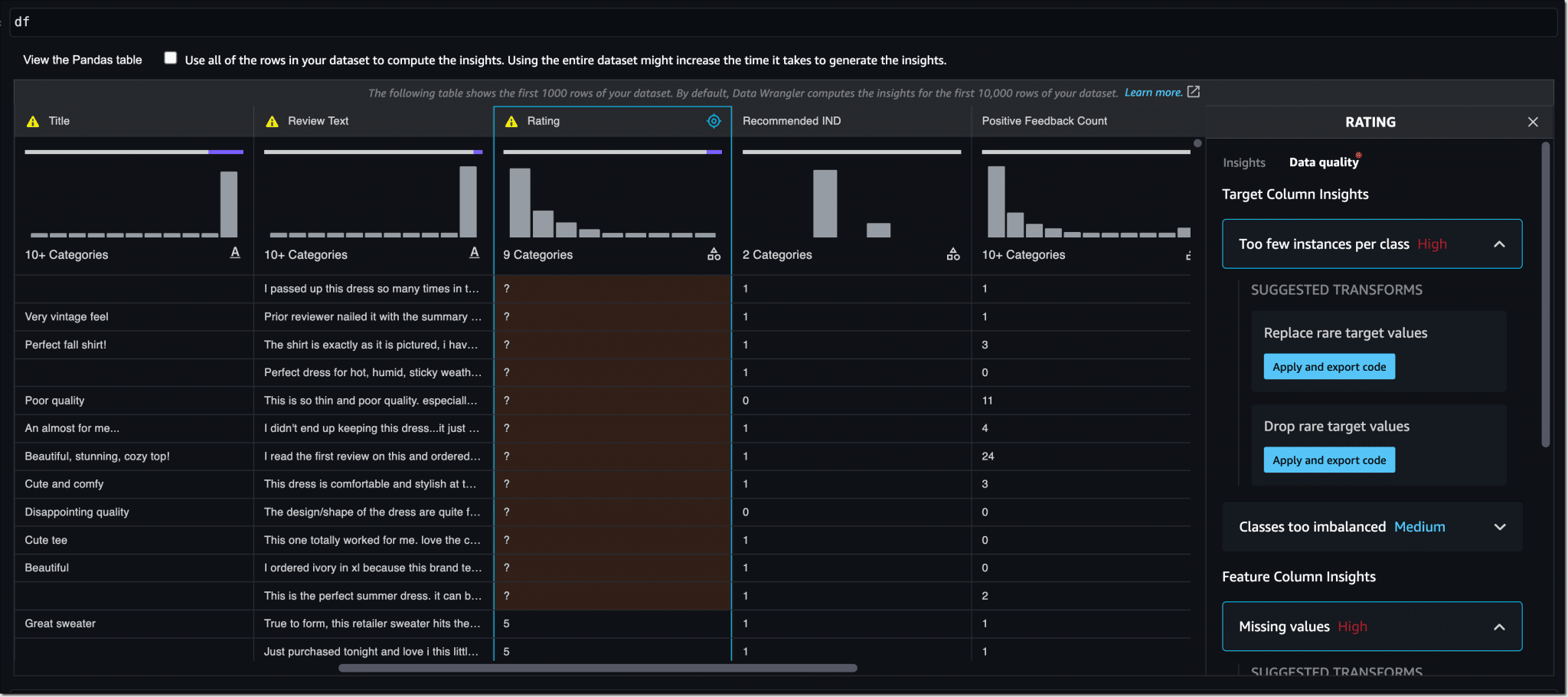
Les notebooks, justement, s'enrichissent sous plusieurs angles. Parmi eux, la préparation de données. Ils peuvent désormais générer automatiquement des visualisations à partir de données tabulaires Pandas. Autre ajout : des espaces partagés dans l'environnement de développement SageMaker Studio, qui reposent sur un répertoire EFS partagé et permettre de collaborer sur des notebooks. À noter aussi la capacité à convertir automatiquement des notebooks en tâches serverless. SageMaker capture un instantané des notebooks, les conteneurise avec leurs dépendances, puis prépare l'infrastructure et la déprovisionne une fois la tâche accomplie.
{kind=link}
{kind=link}
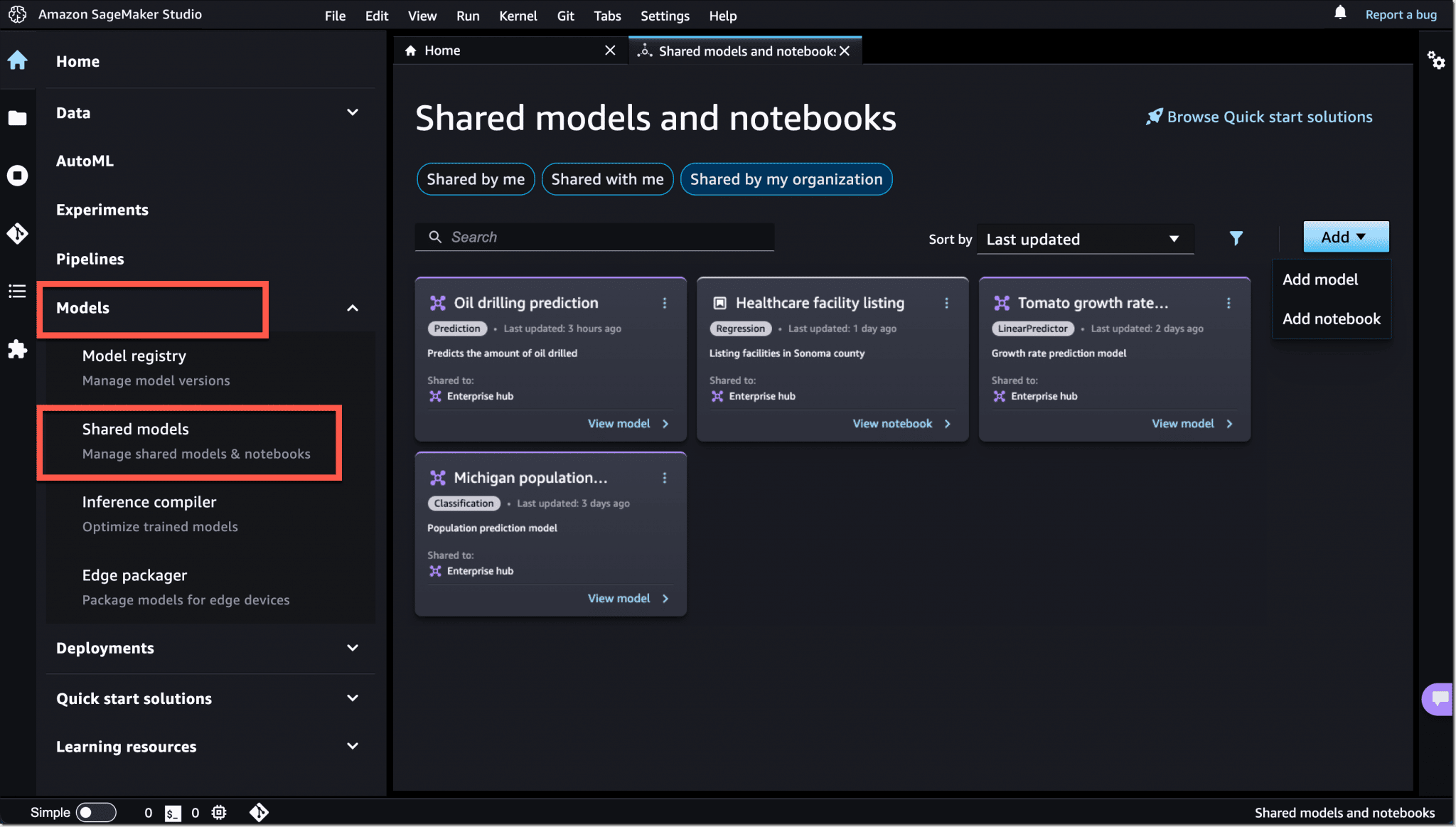
Pour partage des notebooks, mais aussi des modèles, on pourra se tourner vers SageMaker Jumpstart. À l'origine, ce service se limitait à donner accès à des algorithmes intégrés et à des modèles préentraînés. Il peut désormais accueillir des éléments partagés entre des utilisateurs membres d'un même comptes AWS. Y compris des éléments développés hors de SageMaker.
{kind=link}
{kind=link}
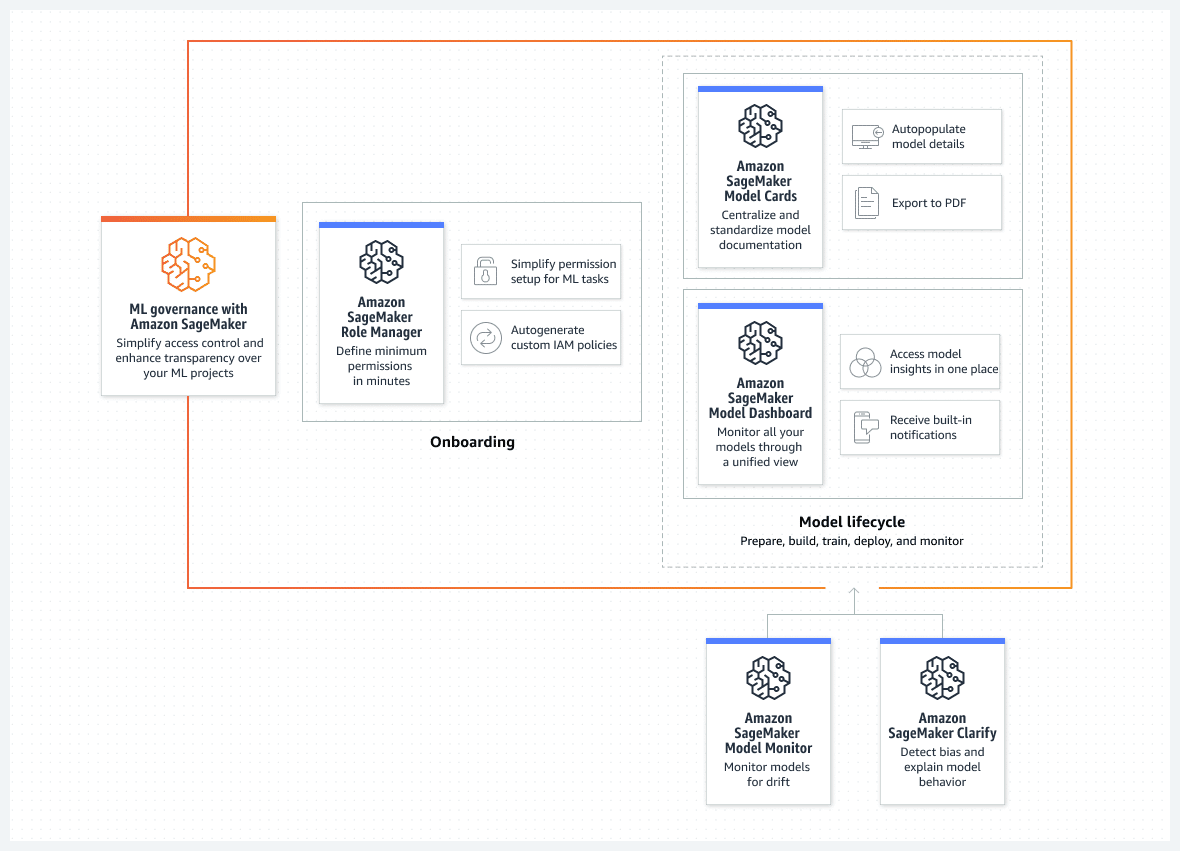
AWS dote aussi SageMaker d'outils supplémentaires de gouvernance. Avec trois briques principales. Premièrement, de quoi définir des permissions personnalisées, avec des templates (catalogue de stratégies IAM) pour deux typologies d'utilisateurs (ingénieurs ML, data scientists) et deux types d'activités (préparation, entraînement). Deuxièmement, des « cartes » permettant de documenter les modèles sur leur cycle de vie. Troisièmement, un tableau de bord, intégré à Model Monitor et Clarify, pour évaluer les modèles sur quatre dimensions. En l'occurrence, qualité des données, qualité des modèles, perte de précision due aux biais et perte de précision due à la distribution des données.
{kind=link}
{kind=link}
SageMaker Studio se pare quant à lui d'une UI refondue. En particulier au niveau du menu latéral de navigation. Le voilà doté de liens suivant les étapes classiques du workflow ML. Et d'un lanceur redesigné mettant l'accent sur des « actions rapides ».
{kind=link}
{kind=link}
Encore au stade de la preview, il y a la prise en charge des données géospatiales dans SageMaker. AWS fournit des modèles préentraînés, des opérateurs et diverses bibliothèques de visualisation (GDAL, GeoPandas, NumPy, Rasterio...).
L'accès est payant. À raison, d'une part, de 150 $/mois/utilisateur pour les outils de visualisation et de collaboration. Et, de l'autre, d'une facturation à l'usage pour le compute, le stockage et les requêtes.
{kind=link}
{kind=link}
Arrive aussi, sur SageMaker, le shadow testing. Dans les grandes lignes, il s'agit de créer un modèle de test vers lequel on achemine une copie des requêtes dirigées vers le modèle de production. SageMaker permet ensuite de comparer les performances sur un tableau de bord - et éventuellement de les journaliser sur le modèle de test pour une comparaison hors ligne.
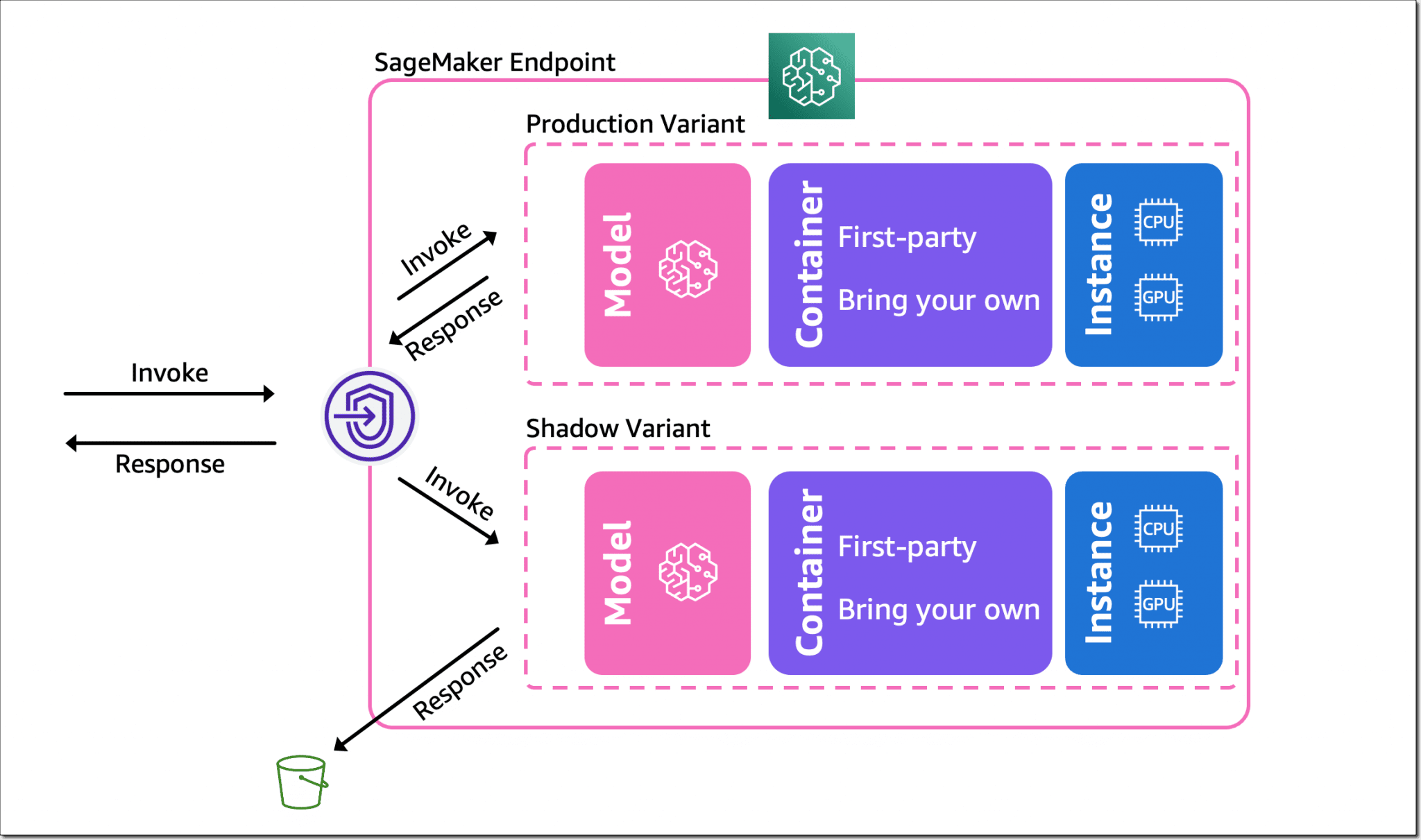{kind=link}
{kind=link}
Illustration principale générée par IA