

Apple Intelligence : ce qu'il y a sous le capot
On en sait plus sur les principaux LLM sous-jacents à Apple Intelligence. Des datasets aux étapes d’entraînement, tour d’horizon.

Pruning et distillation, duo gagnant pour développer un LLM ? Les deux techniques ont en tout cas été mises en œuvre pour l’un des modèles qui sous-tendent Apple Intelligence.
Annoncée en juin, cette marque regroupe un bouquet de services ayant trait à l’IA, notamment générative. Apple y ouvrira l’accès cet automne sur certains iPhone, iPad et Mac. Avec un point d’interrogation en Europe au vu des « incertitudes réglementaires » qu’engendre le DMA.
On a davantage de certitudes sur les fondements techniques d’Apple Intelligence. En particulier depuis que le groupe américain a publié un rapport spécifique, consacré à deux des modèles de fondation impliqués (un qui fonctionnera en local, un autre côté serveur). Ces transformeurs font partie d’une famille qui inclut aussi un modèle de code et un modèle de diffusion.
Lire aussi : Les choix d'OpenAI pour GPT-4o mini
Des données du web à celles acquises sous licence
Apple dit avoir utilisé, pour alimenter ses modèles, trois grandes sources :
– Données d’éditeurs exploitées sous licence
– Datasets ouverts ou accessibles au public
– Informations publiquement accessibles sur le web
Extraites en combinant le mode lecture de Safari et l’algo Boilerpipe, les données issues du web ont fait l’objet de divers filtrages, à renfort d’heuristique et de modèles de classification. Puis d’une décontamination à partir de 811 benchmarks.
Les éléments sous licence sont du contenu long et qualitatif. Pour ce qui est du code, Apple a ciblé des dépôts GitHub de projets open source. Il a retenu 8 langages (Swift, Python, C, Objective-C, C++, JavaScript, Java, Go) englobant les licences MIT, Apache, BSD, CC0, CC-BY, ISC et l’Artistic License.
Pour les mathématiques, l’échantillon a associé des questions-réponses issues de 20 sites référents (3 milliards de tokens) et un ensemble de 14 milliards de tokens provenant de forums, de blogs, de tutos, etc. Un filtrage spécifique a été appliqué, sur 40 chaînes et 350 symboles Unicode/LaTeX.
Pour l’encodage, Apple a suivi l’implémentation SentencePiece. Sans normalisation Unicode et avec décomposition des caractères UTF-8 inconnus en tokens d’un octet. Taille du vocabulaire : 49k pour le modèle local, 100k pour le modèle serveur.
Une recette en trois temps
La formation des modèles s’est faite en trois étapes : préentraînement génératif avec le framework maison AXLearn (basé sur JAX), apprentissage continu, puis ajustement sur contexte long.
La première phase a impliqué, pour l’un et l’autre modèle, 6300 milliards de tokens. Configuration pour le modèle serveur : 8 tranches de 1024 TPU v4 (parallélisme interne pour les modèles ; entre tranches pour les données), des séquences de 4k et des lots de 4096 séquences. Le modèle local a utilisé 2048 TPU v5p. On l’a initialisé à partir d’un modèle formé avec la même recette, mais amputé (pruning) au niveau de la dimension cachée dans les couches de propagation avant. Est ensuite intervenue une étape de distillation sur le même ensemble de tokens.
Le pruning engendre jusqu’à 2 % de gain de performance sur les benchmarks pris en considération, affirme Apple. La distillation a permis de gagner 3 % sur GSM8K (mathématiques) et 5 % sur MMLU (compréhension du langage).
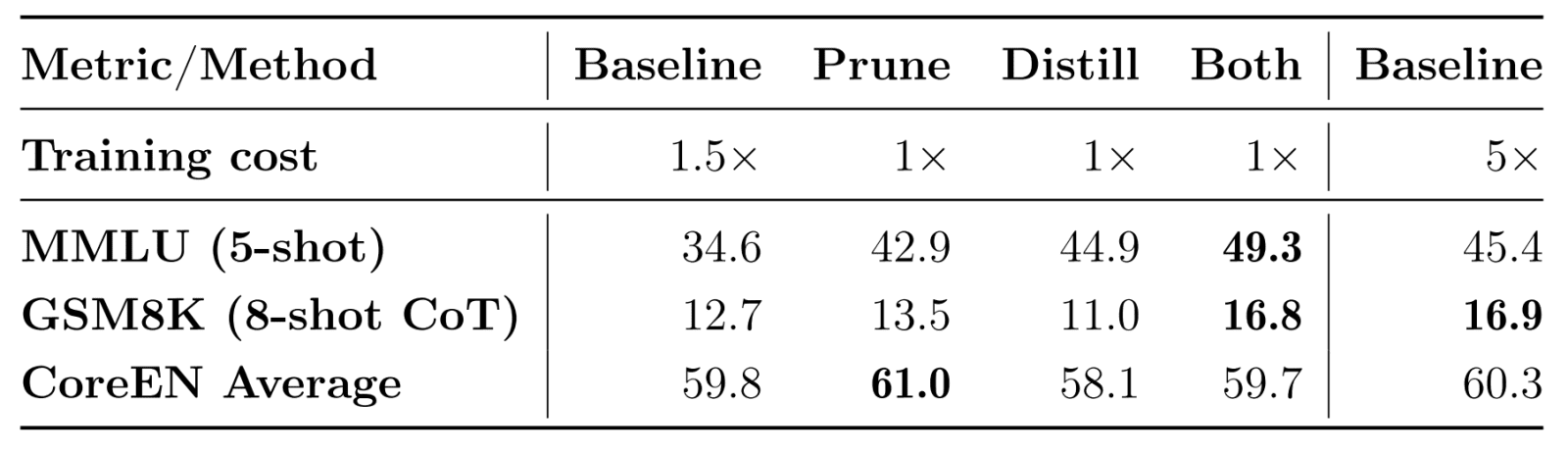
Pour la deuxième phase, on a doublé la taille de séquence et ajouté un ensemble de 1000 milliards de tokens donnant davantage de poids aux maths et au code qu’aux données issues du web. On a aussi ajouté les données « qualitatives » sous licence.
L’ajustement sur contexte long (32k) a reposé sur 100 milliards de tokens. Parmi eux, des données synthétiques de type questions-réponses.
Entre données synthétiques et feedback humain
Destiné à améliorer les performances en conversation, suivi d’instructions et raisonnement, le surentraînement a impliqué du fine-tuning supervisé (SFT) et de l’apprentissage continu avec feedback humain (RLHF).
Pour l’affinage sur le suivi d’instruction, Apple a collecté des datasets annotés contenant des prompts utilisateur et système, avec des réponses associées. Pour l’apprentissage continu, il a fait appel à des évaluateurs. En leur demandant, d’une part, de choisir, pour un prompt donné, la meilleure réponse entre deux. Et de l’autre, de noter des réponses sur des éléments comme la factualité, la lisibilité et l’acceptabilité.
Pour les maths, Apple a recouru à des données synthétiques. Pour les produire, il a tout simplement sollicité le modèle préentraîné. En lui demandant, d’un côté, de reformuler des problèmes. Et de l’autre, des les complexifier.
Pour l’appel de fonctions, l’interpréteur de code et la navigation web, on utilise d’abord des données synthétiques axées sur un cas d’usage. Pour les scénarios impliquant de multiples outils, on passe sur des données annotées par des humains.
Sur le code, on demande au modèle de générer des questions de type entretien d’embauche. Avec, pour chacune, des solutions potentielles et des tests unitaires. On exécute chaque paire et on retient celle qui fonctionne le mieux.
Un « comité de modèles » pour l’apprentissage continu
Le SFT a surtout permis de former au suivi d’instructions. Le RLHF s’est fait de façon itératif, à l’appui d’un « comité de modèles ». À chaque batch de collecte du feedback, on met en place un nouvel ensemble de modèles, en conservant les meilleurs du tour précédent et en y combinant de nouveaux modèles entraînés sur diverses techniques d’optimisation de préférence (échantillonnage par rejet, optimisation directe, apprentissage incrémental…).
En complément, on pratique une distillation sur le dernier comité, avec le dernier modèle de récompense en tant que classifieur. On reclasse les réponses au niveau des prompts plutôt que de choisir simplement comme enseignant le meilleur modèle du comité.
Cette approche apporte les avantages des différents algorithmes d’optimisation de préférence. Ceux qui utilisent des exemples négatifs – l’apprentissage incrémental en fait partie – se révèlent adaptés à l’amélioration du raisonnement. Tandis que l’échantillonnage par rejet a tendance à mieux enseigner la génération de texte.
Une approche à la QLoRA
Après le surentraînement interviennent une compression et une quantisation. Celle-ci se fait à précision mixte : on tire parti des connexions résiduelles dans chaque couche pour réduire l’usage mémoire. En partant d’une base à 4 bits, il est possible d’arriver à 3,5 bits. Pour la prod, Apple a choisi une valeur de 3,7 bits, qui entre dans son cahier des charges.
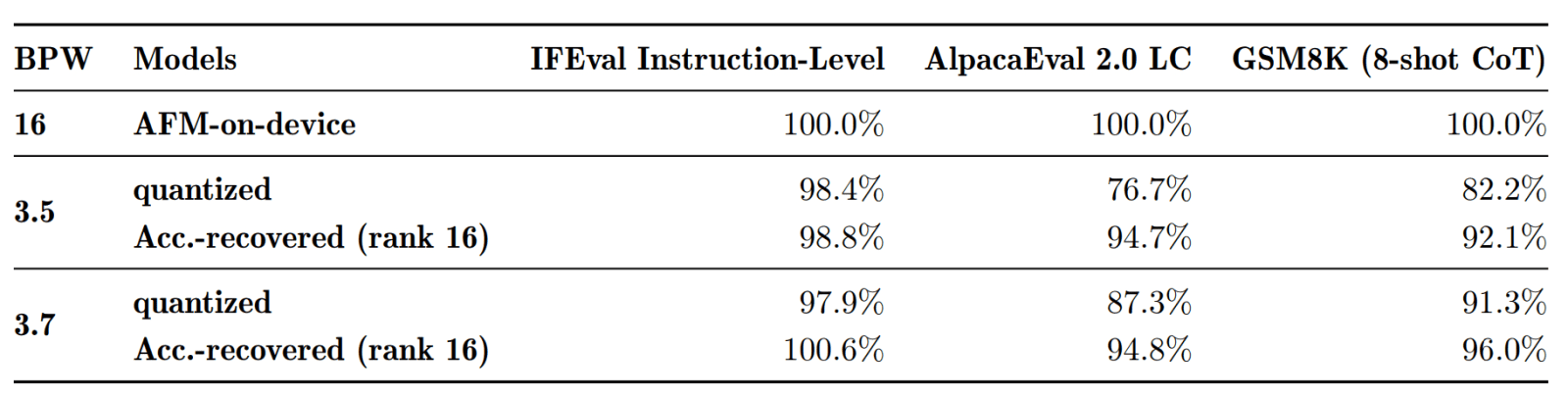
Plutôt que de transmettre à ses développeurs le modèle quantisé tel quel, Apple y adjoint des adaptateurs LoRA. Leur rôle : permettre de récupérer une partie de la qualité perdue avec la diminution de précision. C’est sur cette base que les équipes application travaillent, sans toucher au modèle quantisé. Au final, celui-ci devient capable de s’adapter « à la volée » à des tâches spécifiques, grâce à ces modèles qui pèsent typiquement quelques dizaines de Mo.
Apple met ses LLM à l’épreuve
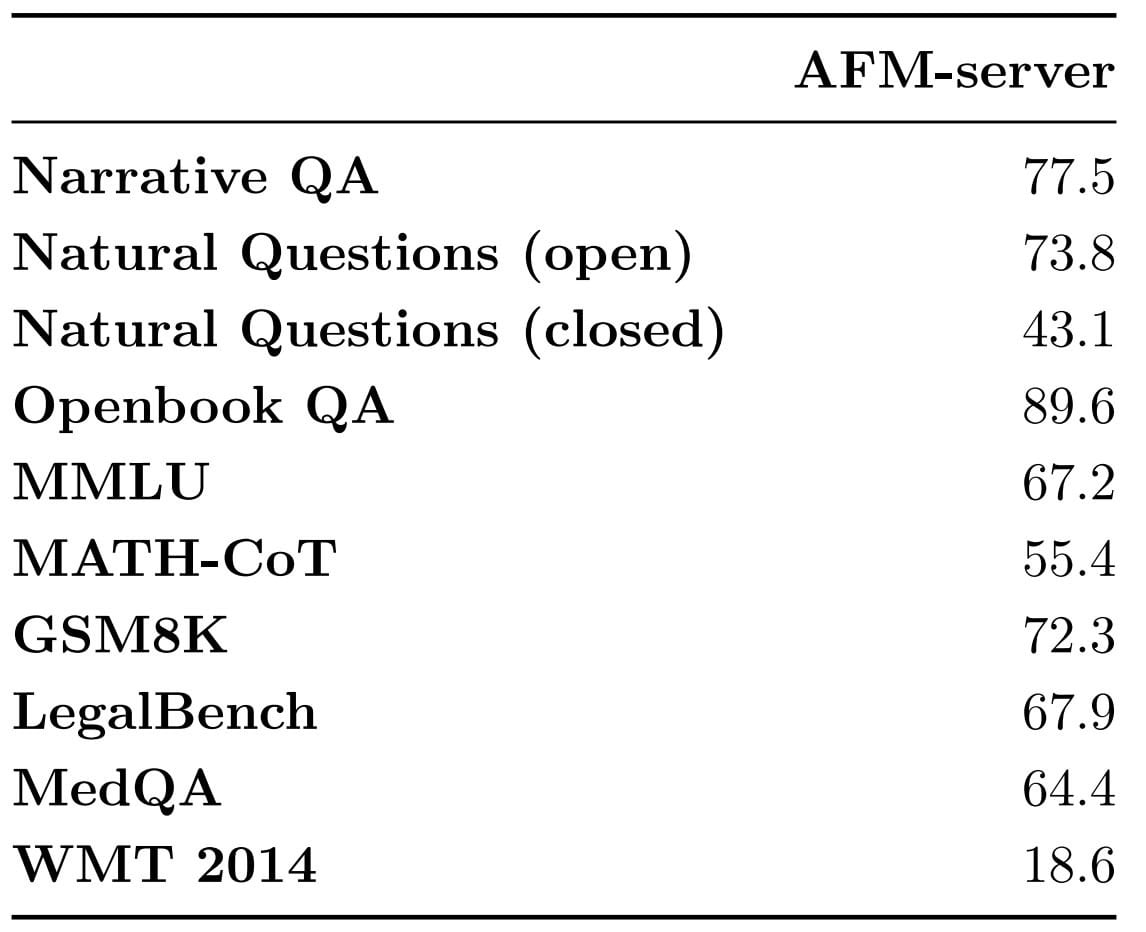
Apple fournit quelques résultats d’évaluations automatisées, par exemple sur un sous-ensemble du leaderboard Hugging Face v1 et la suite HELM-Lite 1.5.0 de Stanford. Il souligne cependant que pour les modèles surentraînés et sur les adaptateurs LoRA, les évaluations humaines sont mieux corrélées à la réalité de l’expérience utilisateur.

Pour l’évaluation humaine après surentraînement, Apple a retenu 1393 prompts. Ils couvrent une variété de tâches (raisonnement analytique, classification, questions fermées, synthèse, (ré)écriture…). Il en ressort les scores suivants :
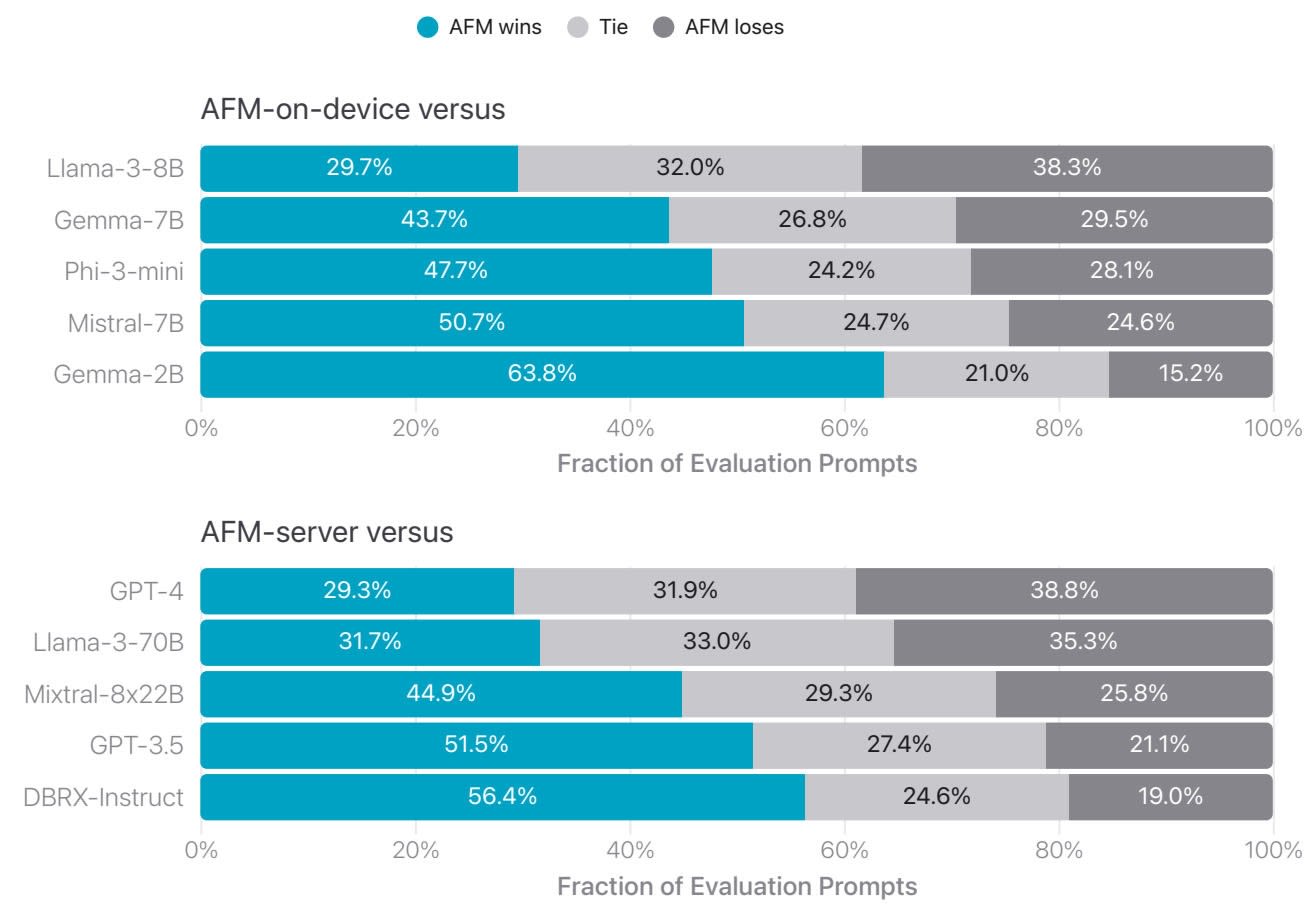
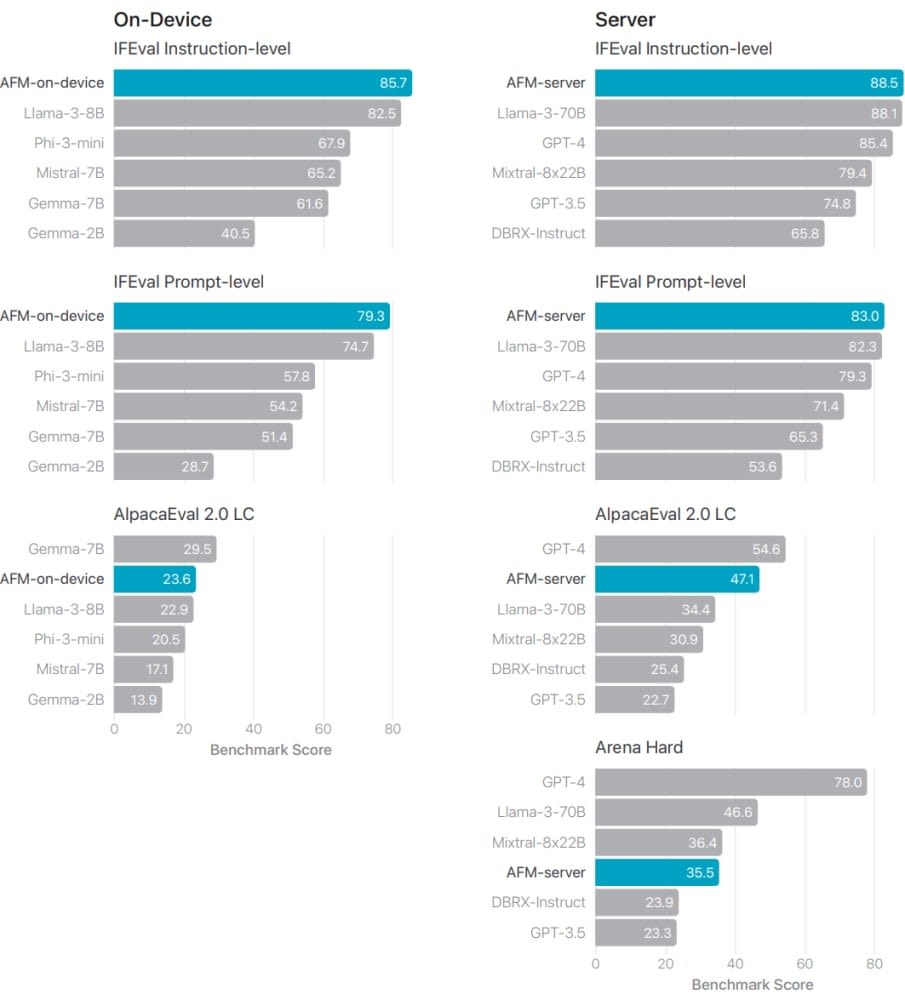
Pour le suivi d’instructions, les résultats sur IFEval et AlpacaEval se présentent ainsi :
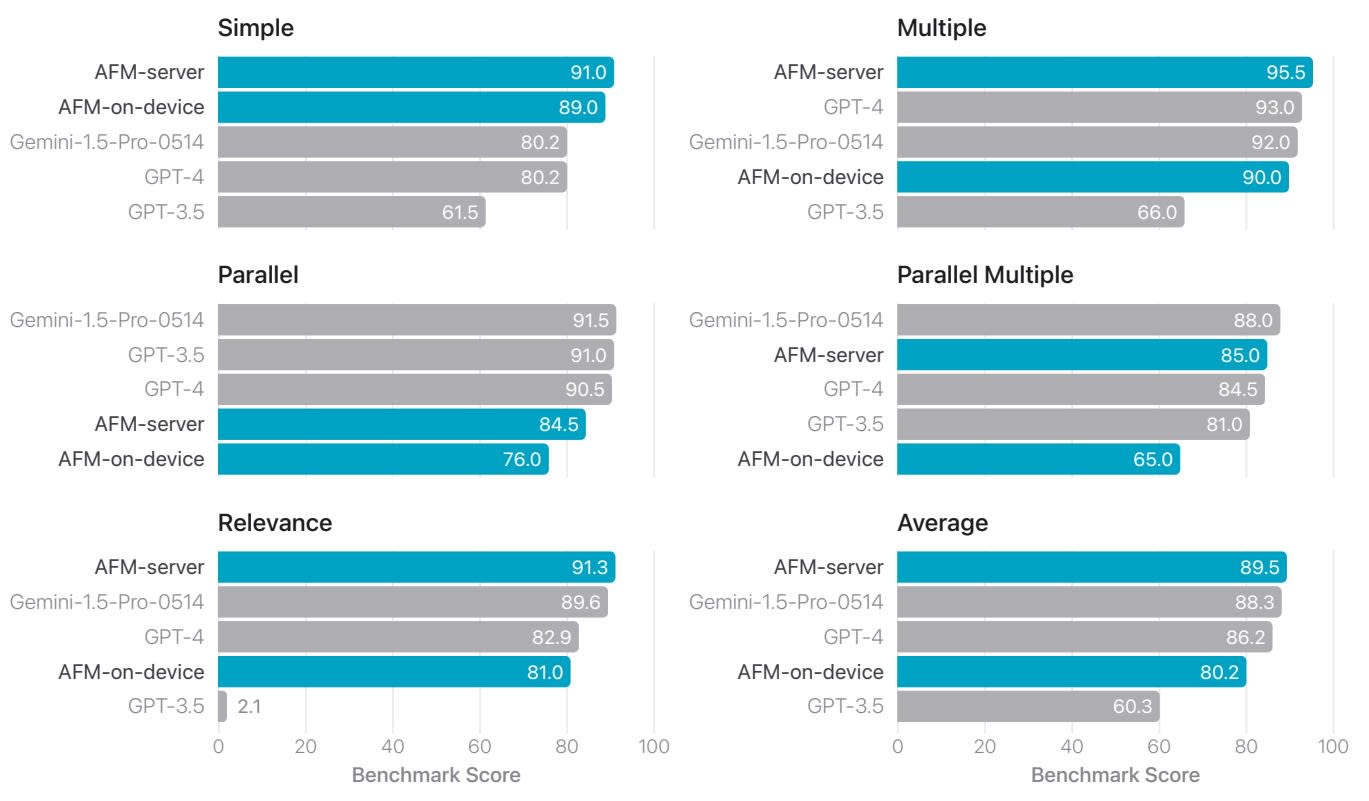
Et sur l’usage d’outils, à partir du leaderboard Berkeley Function Calling :
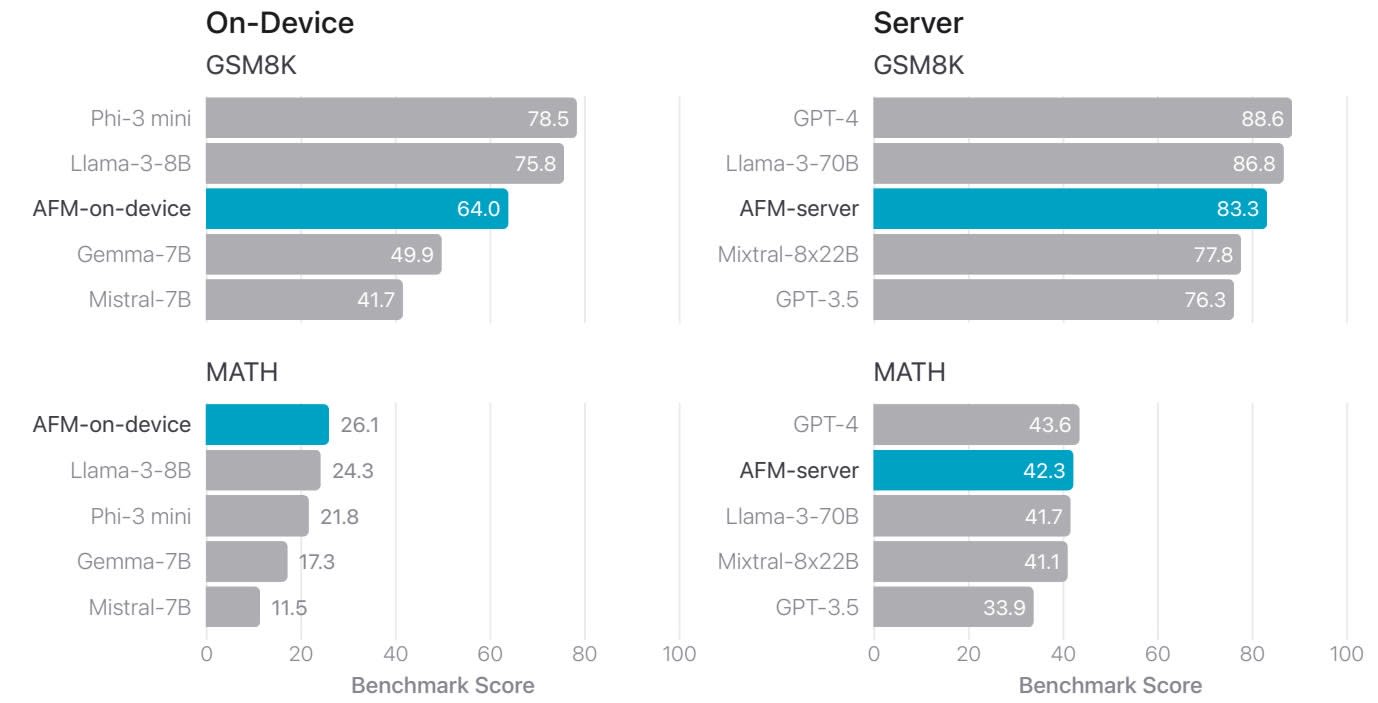
Apple fournit aussi des évaluations sur la génération de texte (benchmarks internes avec GPT-4 comme juge) et les mathématiques (en chain-of-thought 4-shot sur MATH, 8-shot sur GSM8K).
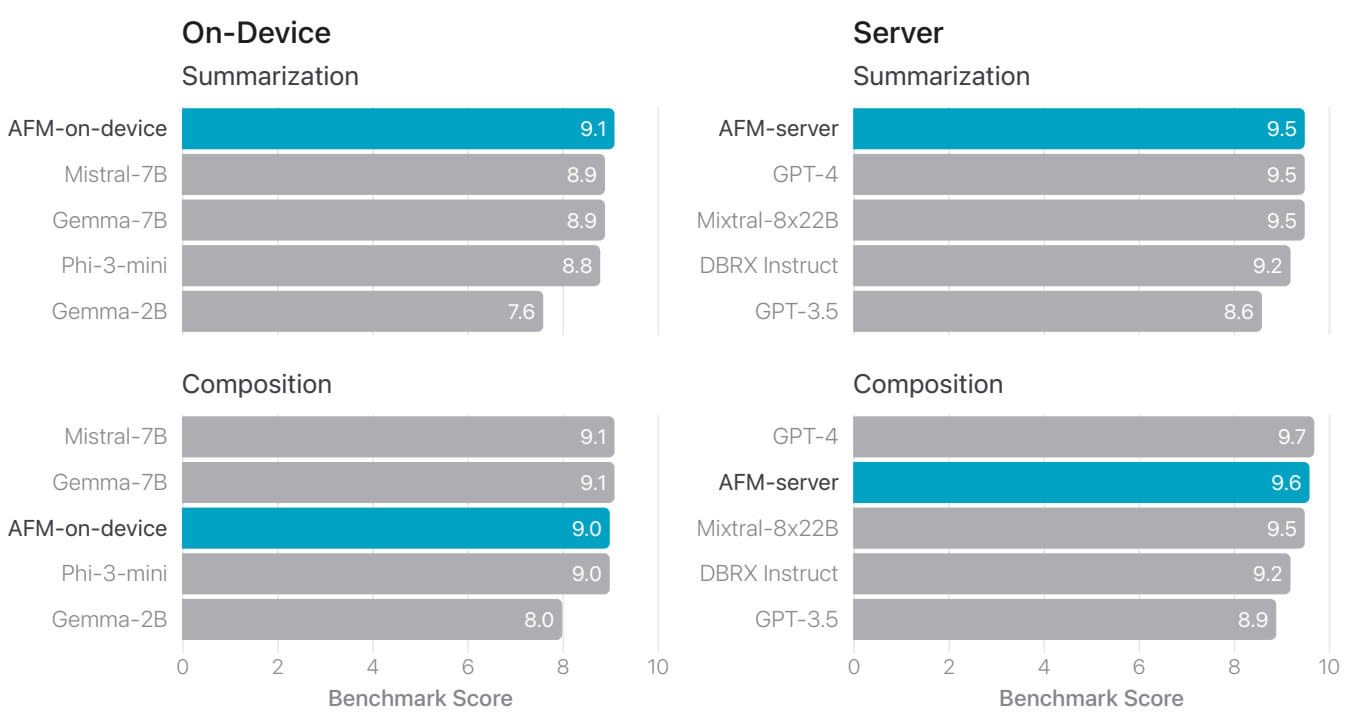
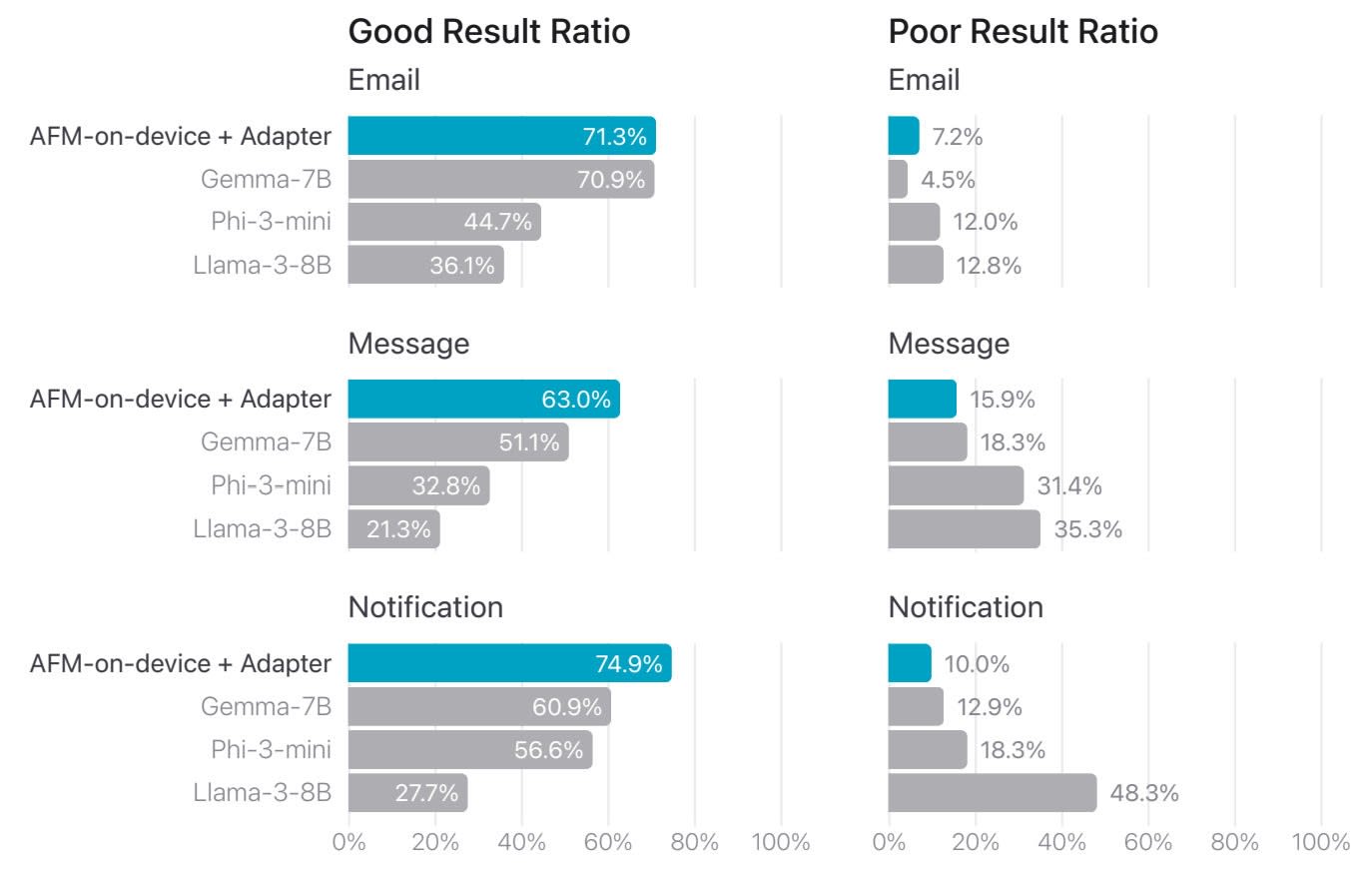
Quant à l’évaluation humaine de la fonctionnalité de résumé de texte :
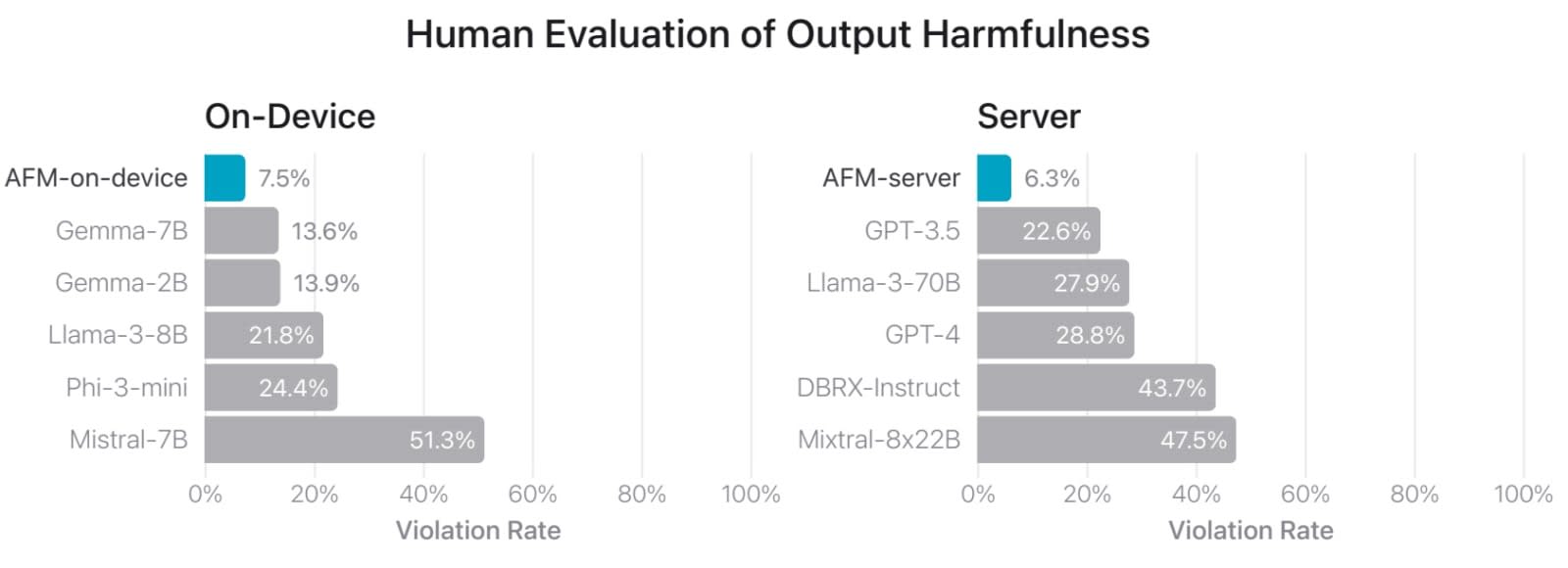
Concernant l’alignement des modèles sur des principes d’« IA responsable », Apple l’a intégré au surentraînement plutôt que de le considérer comme une tâche à part. Environ 10 % des données d’entraînement servent cet objectif, étant soit antagonistes soit liées à des sujets sensibles. L’ajustement des adaptateurs a aussi impliqué des données spécifiques.
Illustrations © Apple
Sur le même thème
Voir tous les articles Data & IA
Par Rémy Mandon *
6 min.Par Clément Bohic
Par Clément Bohic
Par Clément Bohic
Par Clément Bohic







