

Mistral AI lance son premier LLM : ouvert, mais jusqu'où ?
Un premier LLM open source made in Mistral AI a fait son entrée. La start-up française ne communique pas tout à son sujet.

Quand on développe un modèle d'IA open source, jusqu'où doit-on être « open » ? Mistral AI a fait ses arbitrages.
La start-up française vient de publier son premier LLM (poids et code d'inférence), sous licence Apache 2.0. Ses équipes promettent une communication « aussi ouverte que possible »... tout en posant des limites. Il n'est, par exemple, pas question d'entrer dans les détails du dataset d'entraînement. Timothée Lacroix et Arthur Mensch, respectivement DG et président, l'ont tour à tour rappelé hier sur le Discord Mistral AI.


Le sujet de la monétisation n'est pas non plus pour tout de suite. La team Mistral AI l'abordera quand elle « aura publié d'autres modèles ».
Le premier, Mistral 7B, a été formé sur un des supercalculateurs de l'initiative EuroHPC. En l'occurrence, Leonardo (voir notre article à son propos). Il est optimisé pour le résumé, la classification et la complétion de texte - ainsi que de code. Il en existe une déclinaison Instruct adaptée à la conversation et à l'exercice des questions-réponses.
Mistral 7B a du sang français, mais sa langue de prédilection est l'anglais. Mistral AI affirme cependant disposer des données adéquates pour aller vers le multilinguisme. Lors de la phase d'entraînement, 8 000 milliards de tokens étaient potentiellement disponibles, nous annonce-t-on.

Des choix d'architecture face à Llama-2
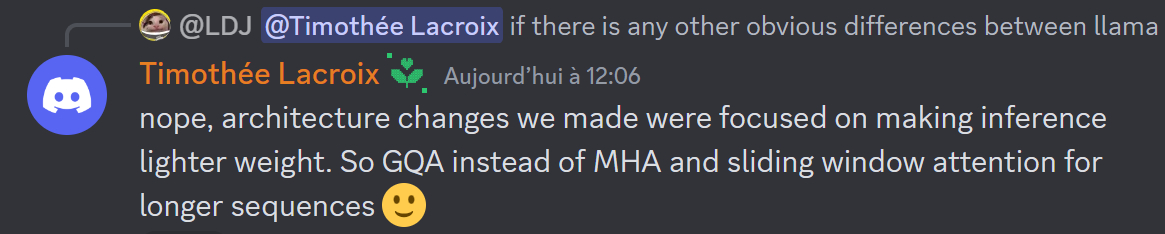
Mistral AI a fait deux grands choix d'architecture : utiliser le mécanisme du GQA (grouped-query attention) et une fenêtre d'attention glissante. Cette dernière permet de traiter des séquences plus longues tout en économisant du cache.


© Google Research

© Allen Institute for Artificial Intelligence
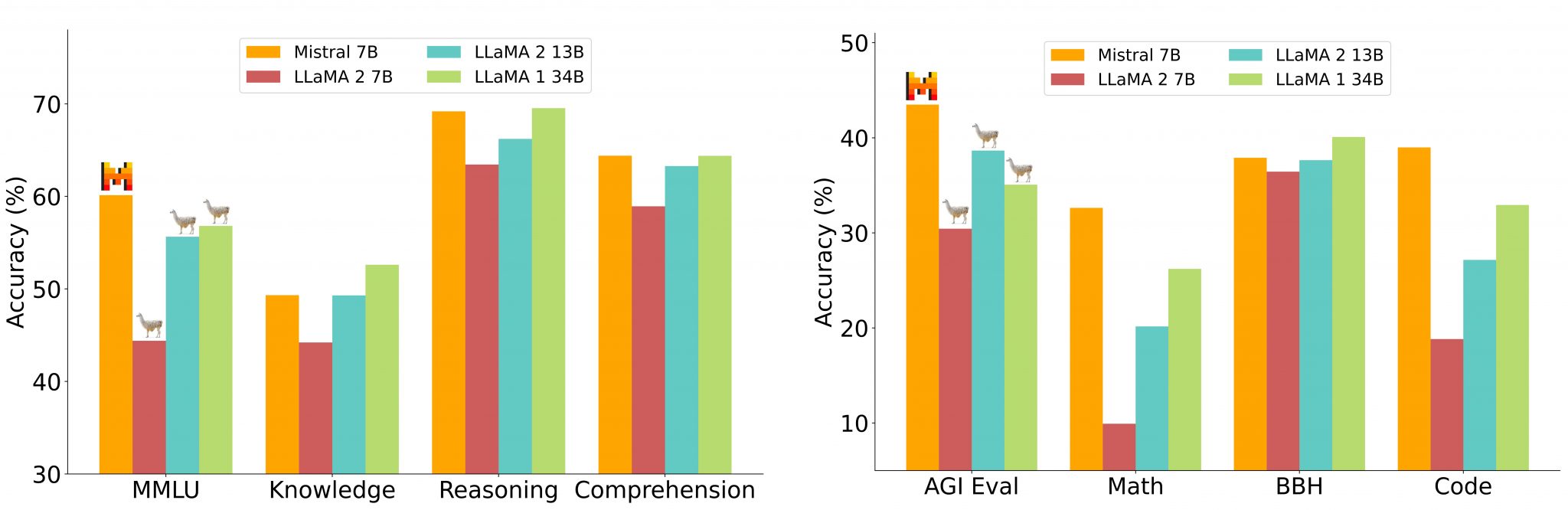
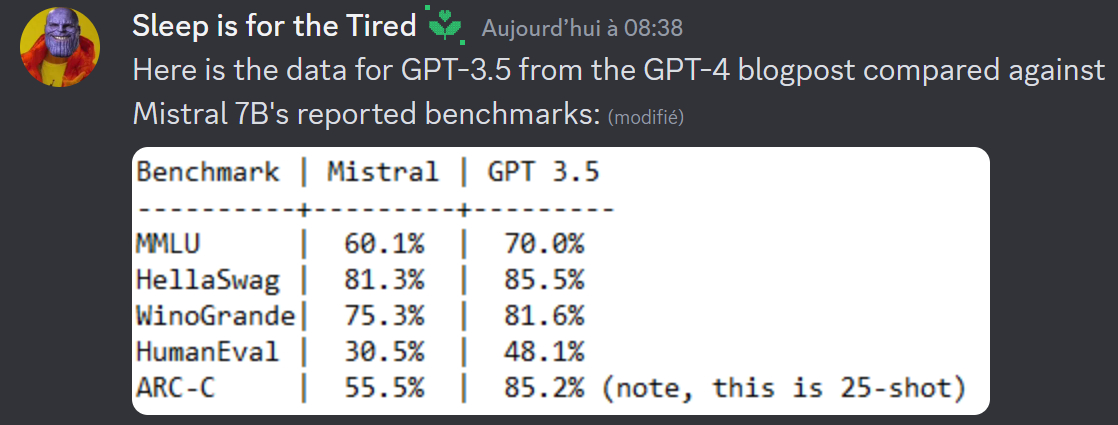
Au bout du compte, le modèle se révèle meilleur que Llama-2 13B sur tous les benchmarks que présente Mistral AI. Il dépasse Llama-1 34 B sur la plupart de ces mêmes tests et s'approche de Code Llama 7B sur la partie code.
Lire aussi : CMA CGM devient un gros client de Mistral AI

L'écart est notable sur le raisonnement mathématique. Même si, en valeur absolue, les scores de Mistral 7B restent bas (13,1 % de précision sur MATH et 52,1 % sur GSM8K).

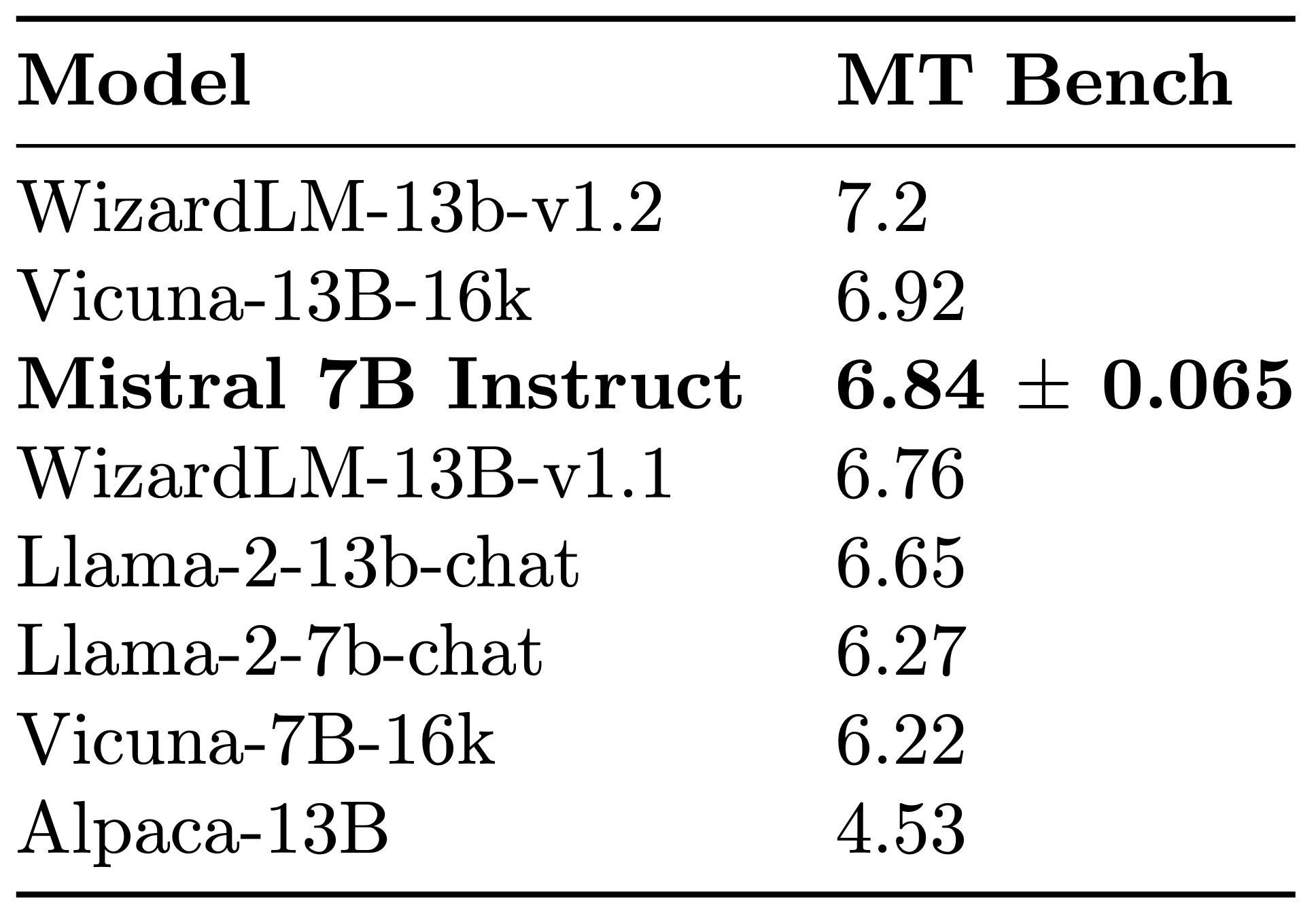
Sur MT Bench, la version Instruct est presque au niveau de Vicuna-13B, avec une fenêtre de contexte deux fois plus petite (8k).


Une image Docker est disponible pour déployer un serveur vLLM. L'API est calquée sur celle d'OpenAI, à quelques fonctions près (vLLM doit encore implémenter, entre autres, logit_bias).
Dans l'idéal, on réservera 24 Go de vRAM à Mistral 7B pour l'inférence en semi-précision (FP16).
| Détail des benchmarks |
| MMLU (multiples tâches de traitement du langage) : 5-shot Connaissances : 5-shot sur NaturalQuestions et TriviaQA Raisonnement : 0-shot sur Hellaswag, Winogrande, PIQA, SIQA, OpenbookQA, ARC-Easy, ARC-Challenge et CommonSenseQA Compréhension écrite : 0-shot sur BooIQ et QuAC AGI : 3-5 shot sur AGI Eval (QCM en anglais uniquement) Mathématiques : 8-shot sur GSM8K maj@8 et 4-shot sur MATH maj@4 BBH (multiples exercices de compréhension) : 3-shot Code : 0-shot sur HumanEval et 3-shot sur MBPP |
À consulter en complément :
A=B donc B=A ? Pour les LLM, ça ne coule pas de source
Sécurité des IA génératives : l'OWASP esquisse un top 10
IA : le plan de Xavier Niel pour devenir un « grand en Europe »
DALL-E 3 ouvre la voie à un ChatGPT multimodal
Sur le même thème
Voir tous les articles Business![Déployer l'IA à l'échelle : l'approche d'AXA, entre vision et [...]](https://cdn.edi-static.fr/image/upload/c_lfill,h_201,w_298/e_unsharp_mask:100,q_auto/f_auto/v1/Img/BREVE/2025/4/473364/deployer-echelle-approche-axa-L.jpg)
Par Philippe Leroy
4 min.Par Philippe Leroy
Par Clément Bohic
Par Clément Bohic
Par Clément Bohic






{kind=link}
{kind=link}
{kind=link}
{kind=link}