

PyTorch 2.0 : pourquoi ce grand saut de version ?
Le framework PyTorch embraye sur une nouvelle version majeure. À quoi doit-on cette décision ?

Après PyTorch 1.13, PyTorch 1.14 ? Eh bien non : on passe à la version 2.0. La conséquence d'une modification jugée « fondamentale ». En l'occurrence, l'ajout d'un mode optionnel de compilation (torch.compile).
Cette fonctionnalité s'appuie sur des briques toutes écrites en Python. À contre-courant, donc, de la tendance à porter des composantes du framework en C++ pour maintenir les performances* du mode eager (exécution immédiate, sans génération de graphes).

Lire aussi : Du RAG aux agents, les choix GenAI de Doctolib
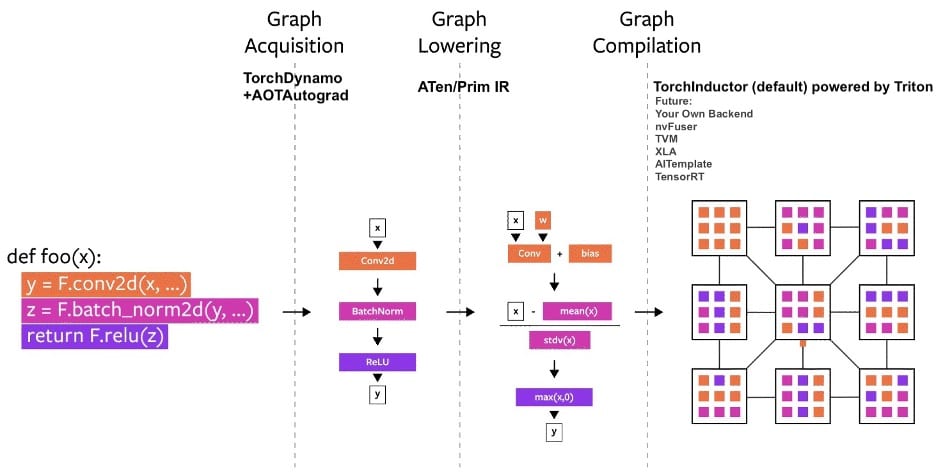
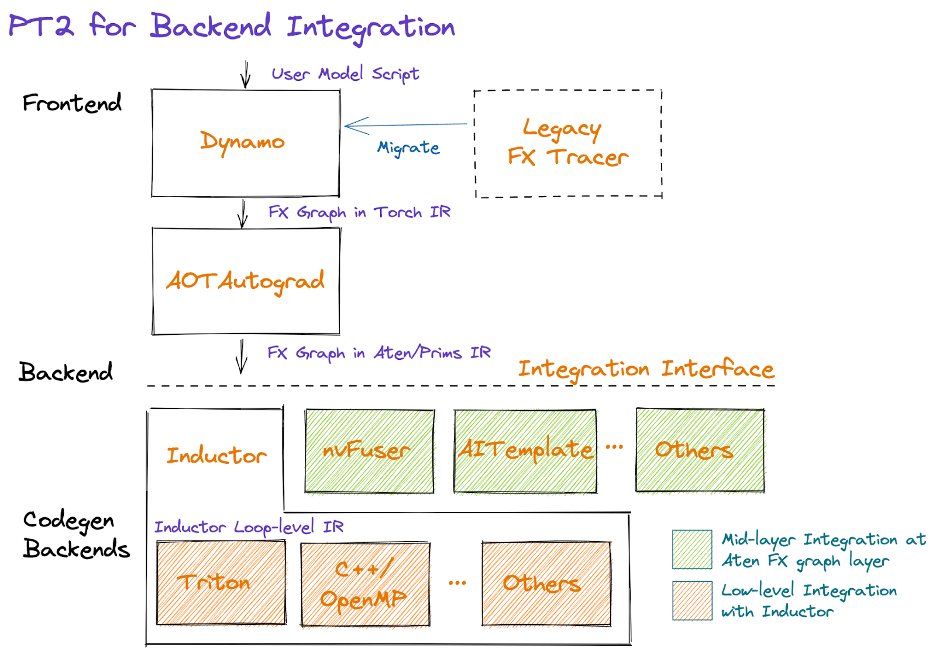
Les briques en question sont au nombre de quatre. En front-end, TorchDynamo génère des graphes à partir du bytecode, à l'appui de l'API d'évaluation de frames de CPython. Testé sur quelque 7000 projets GitHub, il a « fonctionné 99 % du temps ».
AOTAutograd intervient ensuite pour générer, de façon anticipée, le graphe de rétropropagation correspondant au graphe de propagation capturé par TorchDynamo. Il exploite le mécanisme d'extensibilité torch_dispatch pour se superposer à autograd (moteur de différentiation de PyTorch).
PrimTorch peut être mis à contribution - sur opt-in - au stade de la réduction de graphe. Il consiste en un jeu réduit d'opérateurs PyTorch : 250 environ (contre les quelque 1200 que regroupe le framework, hors surcouches), simplifiant la sémantique.
TorchInductor est le back-end de compilation par défaut. Il utilise la technique du define-by-run (définition dynamique du réseau, à l'exécution, à partir de l'historique des calculs) pour générer du code Triton (pour les GPU) ou C++/OpenMP (pour les CPU). Son coeur fonctionnel comprend une cinquantaine d'opérateurs.

Ces quatre briques prennent en charge les tenseurs dynamiques. C'est-à-dire la capacité à en faire varier la taille sans induire de recompilation.
PyTorch 2.0 stabilisé en mars ?
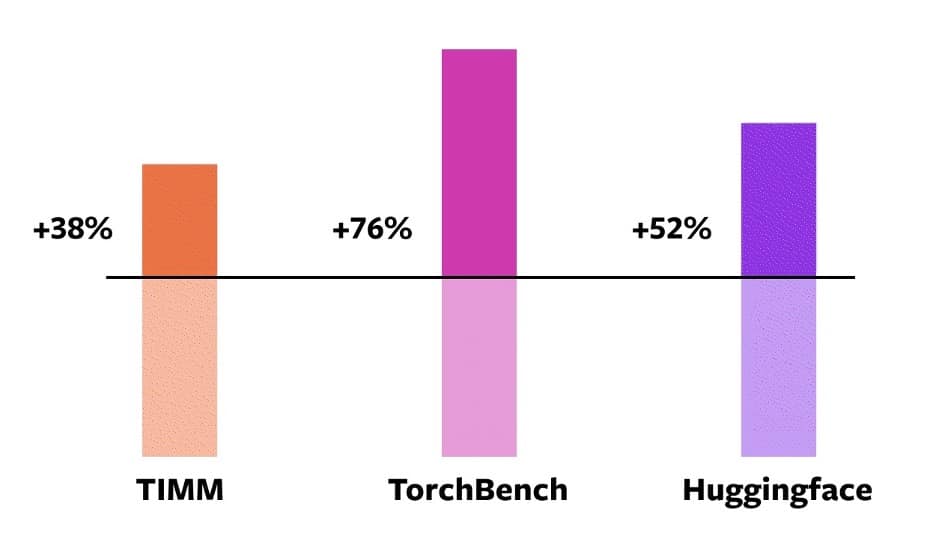
Testé sur 163 modèles open source, torch.compile a fonctionné 93 % du temps. Il est, nous annonce-t-on, globalement 43 % plus rapide en entraînement sur GPU A100 que le mode eager.

La version stable de PyTorch 2.0 est prévue pour début mars. En attendant, c'est dans les nightlies que ça se passe. Sur la feuille de route, entre autres :
- Portage d'autres éléments en Python
- Prise en charge des tenseurs symboliques
- Système d'exportation de modèles entiers
- Simplification de la quantisation
- Gestion avancée du parallélisme sur environnements distribués
* La communauté PyTorch estime que depuis le lancement du framework en 2017, les accélérateurs comme les GPU sont devenus 15 fois plus rapides en calcul. Et que les accès mémoire se font 2 fois plus rapidement.
Illustration principale © Meta
Sur le même thème
Voir tous les articles Data & IA![{ Tribune Expert } - IA générative : entre promesses et [...]](https://cdn.edi-static.fr/image/upload/c_lfill,h_201,w_298/e_unsharp_mask:100,q_auto/f_auto/v1/Img/BREVE/2024/11/465144/generative-entre-promesses-realites-entreprise-L.jpg)
Par Karim Zegour *
Par La rédaction
Par Clément Bohic
Par Shaked Reiner *
Par Clément Bohic







{kind=link}
{kind=link}
{kind=link}