

SpreadSheetLLM ou la promesse d'une GenAI plus à l'aise avec Excel
Sous la bannière SpreadSheetLLM, Microsoft propose un framework destiné à optimiser le traitement des feuilles de calcul par les grands modèles de langage.

Optimiser le traitement des feuilles de calcul par les grands modèles de langage ? Microsoft a un framework pour ça : SpreadSheetLLM.
Expérimental, il aborde les défis liés à ce type de document. Par exemple, la variété des options de formatage et les éléments spécifiques comme les adresses des cellules. Ou la structure à deux dimensions, peu adaptée aux modèles d’input linéaire et séquentiel.
Ce dernier aspect, associé à l’étendue potentielle des feuilles de calcul, est susceptible d’entraîner des dépassements de tokens. Dans ce contexte, SpreadSheetLLM comprend tout un volet consacré à la compression. Il se matérialise en trois modules indépendants qu’on peut associer « à la carte ».
Lire aussi : Du RAG aux agents, les choix GenAI de Doctolib
Éliminer les zones homogènes, les cellules vides et les valeurs répétées
L’un d’eux (module 1) opère une extraction basée sur des « ancres structurelles ». Le principe : éliminer les lignes et les colonnes homogènes, qui ne contribuent pas à l’interprétation de la structure et de la mise en page.
Les « ancres structurelles », au contraire, offrent des informations importantes. Une méthode heuristique identifie ces lignes et ces colonnes hétérogènes situées à la limite des tables. Elle écarte ensuite les zones de données non homogènes (celles qui se trouvent à plus d’une certaine distance). Il en résulte un « squelette condensé » de la feuille de calcul. Après extraction, on opère une réorganisation des coordonnées.
Le module 2 opère une traduction à index inversé. Il s’agit ici d’éliminer les cellules vides et les valeurs qui se répètent. Première étape : convertir l’encodage traditionnel de type matrice en un dictionnaire. Les valeurs des cellules font office de clés indexant les adresses. Deuxième étape : fusionner les cellules partageant une même valeur, exclure les cellules vides et regrouper les adresses en plages.
Le module 3 réalise une agrégation basée sur les formats de données. Ceux-ci, au contraire des valeurs numériques, sont essentiels pour comprendre la structure et la sémantique. Ils présentent en outre l’avantage de pouvoir être clusterisés.
L’agrégation en question exploite le NFS (Number Format String). Cet attribut lié aux cellules peut être extrait et utilisé pour décrire, sous forme de chaînes, le format de données d’une cellule. Comme il n’est pas toujours explicite (l’utilisateur ne paramètre pas systématiquement le format de données), on ajoute un détecteur à base de règles.
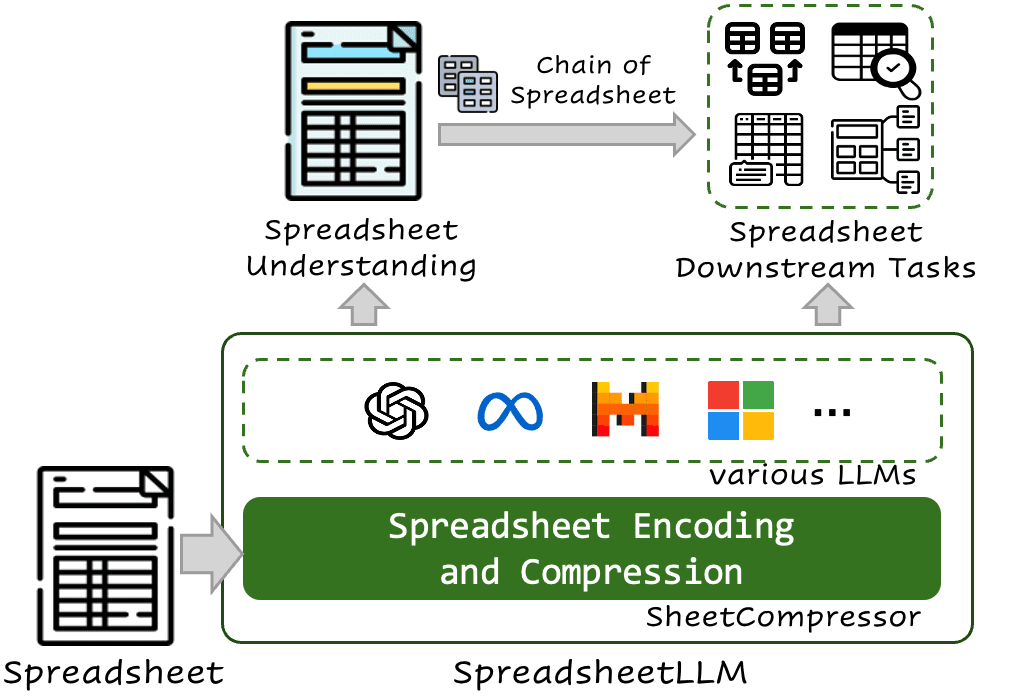
SpreadSheetLLM : détecter les tables… et les comprendre
Pour étendre SpreadSheetLLM à davantage de tâches en aval, Microsoft propose une méthode « Chain of Spreadsheet » en deux étapes. Dans un premier temps, on transmet au LLM la feuille de calcul compressée et la requête. Le modèle identifie la table et le contexte pertinents. On retransmet alors la requête, accompagnée de la section identifiée.
L’évaluation s’est fait sur deux plans : la détection de tables et leur compréhension (Q&A).
Pour la détection, le dataset de base provient de l’expérience TableSense. Même chose pour le modèle de référence (TableSense-CNN). Principal indicateur pris en considération : le F1-score.
Pour le Q&A, les datasets existants étant axés sur des scénarios à une seule table, il a fallu en développer un nouveau. Les modèles existants sélectionnés comme baseline (TaPEx et Binder) ont eu droit au même traitement : on les a ajustés en leur communiquant les zones pertinentes en fonction des requêtes.
De la généralisation à l’apprentissage contextuel, des bénéfices sur toute la ligne ?
En utilisant tous les modules, Microsoft revendique un ratio de compression proche de 25:1.
| Base | Mod. 1 | Mod. 2 | Mod. 3 | 1 & 2 | 1 & 3 | 2 & 3 | 1, 2 & 3 | |
| Tokens | 1 548 577 | 350 946 | 580 912 | 213 890 | 103 880 | 96 365 | 211 445 | 62 469 |
| Ratio | 1,00 | 4,41 | 2,67 | 7,24 | 14,91 | 16,07 | 7,32 | 24,79 |
Sur la détection de tables, le plus haut score est atteint avec GPT-4, généralement sans l’agrégation. Le gain de performance est d’autant plus grand que la feuille de calcul l’est.
La méthode d’encodage appliquée à Mistral-v2 augmente les performances de 18 %. Le gain est de 25 % pour Llama 3 ; 36 % pour Phi-3 ; 38 % pour Llama 2. Il en existe aussi un sur les scénarios ICL (apprentissage sur contexte, sans ajustement préalable).
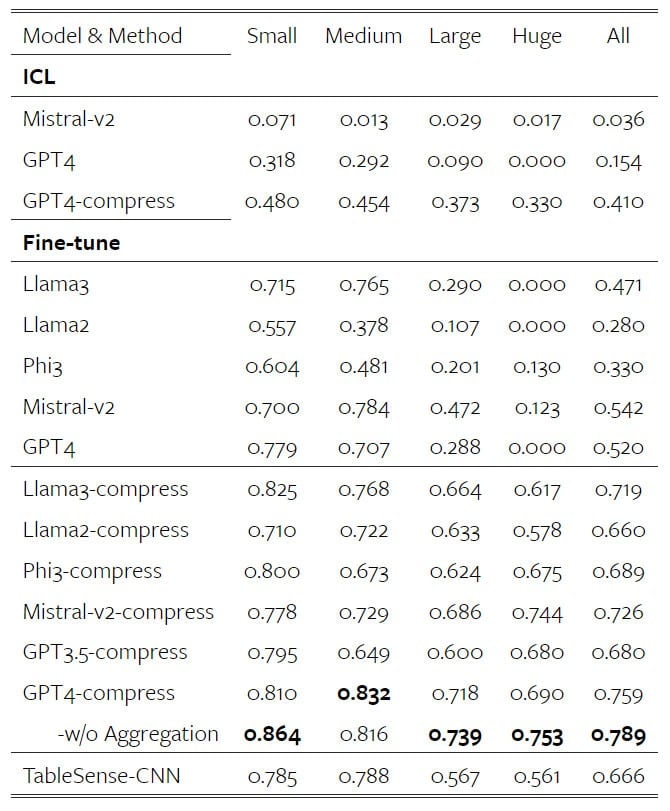
Quant au degré d’efficacité de la méthode CoS, on nous l’illustre par les scores suivants. En insistant sur un indicateur : + 22 % de performance avec GPT-4 par rapport à sa baseline.
Les modèles affinés sur la détection de tables démontrent de robustes capacités de généralisation sur le Q&A, ajoutent les chercheurs.

Illustration principale générée par IA
Sur le même thème
Voir tous les articles Data & IA
Par Clément Bohic
4 min.Par Clément Bohic
Par Clément Bohic
Par Clément Bohic
Par Clément Bohic








{kind=link}