


AIOS : l'esquisse d'un système d'exploitation pour LLM
Améliorer les agents autonomes basés sur des LLM en les englobant dans une forme de système d’exploitation : c’est l’objet du projet AIOS.

Comment améliorer les performances d’agents autonomes basés sur des LLM ? En les encapsulant dans une forme de système d’exploitation.
Des chercheurs de l’université Rutgers (New Jersey) ont suivi cette voie. Il en résulte AIOS.
Ce projet implique un noyau LLM spécifique, distinct du kernel. Il comprend un planificateur ainsi que divers gestionnaires : de contexte (sauvegarde et restauration d’état + gestion de la fenêtre), de mémoire et de stockage (mémoires à court et long terme), d’outils (exploitables par API) et d’accès.
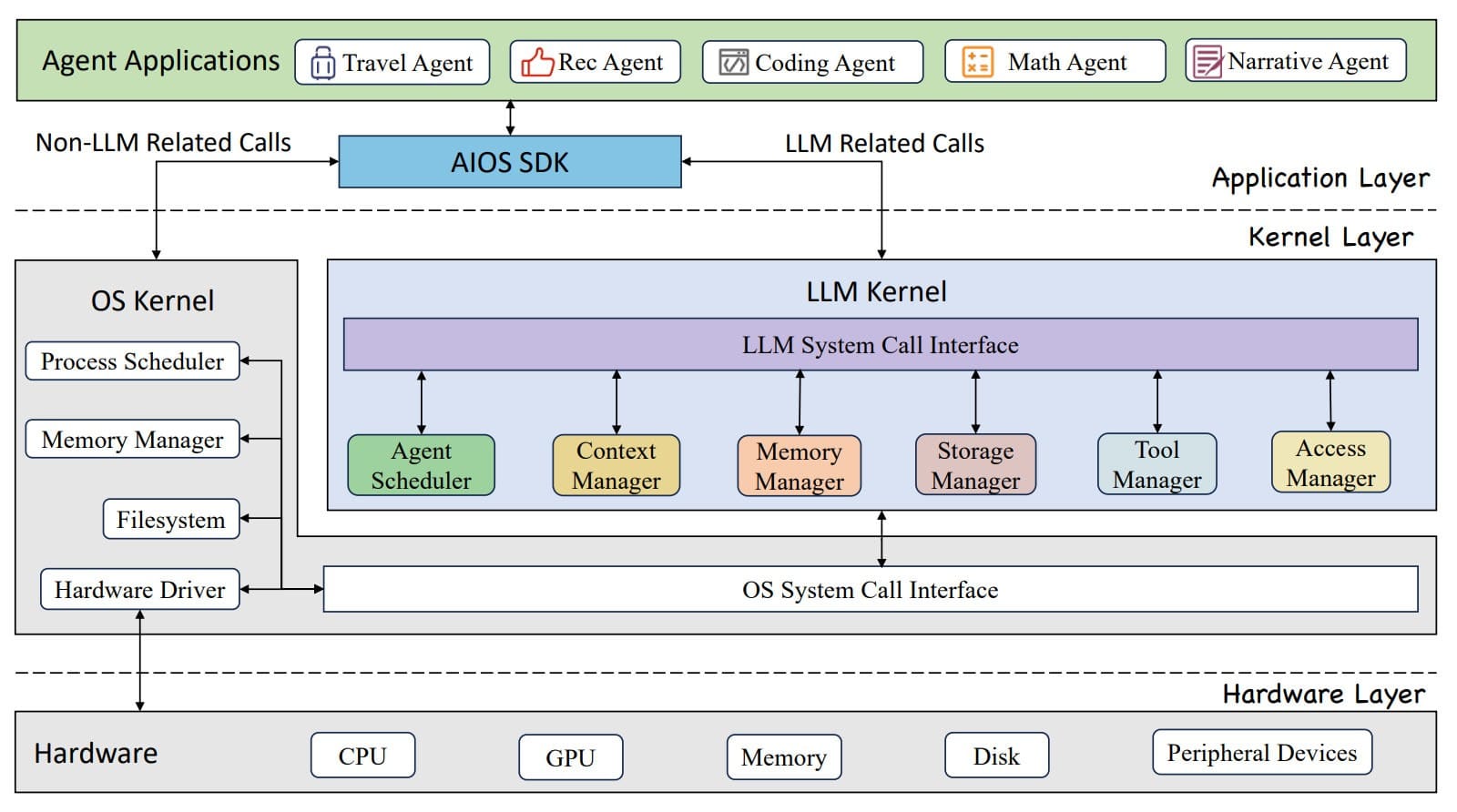
La couche hardware est interfacée exclusivement avec le noyau de système d’exploitation. La couche application comprend un SDK qui gère les fonctions suivantes :

Des pistes d’évolution pour AIOS
Le planificateur utilise des techniques traditionnelles (FIFO, tourniquet…) pour interlacer les tâches. Il n’est pas exclu d’y greffer, à l’avenir, des algorithmes plus avancés, prenant par exemple en compte les dépendances entre requêtes.
Le gestionnaire de fenêtre de contexte s’appuie autant sur des techniques de résumé que d’extension. Parmi ces dernières, l’interpolation (ajustement des positions de tokens à partir de valeurs intermédiaires non entières) et YaRN (prise en compte de la distance entre les tokens d’entrée et non simplement de leurs positions absolues).
Le gestionnaire de mémoire courte conserve l’information aussi longtemps qu’un agent est actif. Il ne gère pour le moment pas le partage de ressources (pools, caches hiérarchiques…).
AIOS gère l’interfaçage avec une quinzaine d’outils répartis en quatre catégories :
– Recherche web (Bing, Google)
– Données mathématiques/scientifiques (conversion de devises, Wolfram Alpha)
– Interrogation de bases de données (SQL, Wikipédia, Arxiv…)
– Traitement d’images (suppression de bruit, défloutage, classification, détection d’objets et de visages)
Le gestionnaire d’accès accorde à chaque agent un groupe à privilèges. Les autres agents peuvent y être inclus.
Gemma, LLaMA : le choix de LLM locaux
Les chercheurs ont axé leur évaluation sur deux questions. D’une part : les réponses du LLM aux requêtes des agents restent-elles cohérentes en dépit des interruptions que déclenche le planificateur ? De l’autre : dans quelle mesure la planification améliore-t-elle les performances par rapport à l’exécution séquentielle ?
Configuration de test :
– Une machine Ubuntu 22.04 avec 8 cartes RTX A5000
– Python 3.9 avec PyTorch 2.0.1 et CUDA 11.8
– Trois LLM publics (deux Gemma, un LLaMA), exécutés en local pour ne pas dépendre, entre autres, des performances réseau
– Trois agents, chacun conçu pour envoyer deux ou trois requêtes au LLM ; spécialisés respectivement en maths, en écriture de récits et en recommandation de restaurants
Peu importe l’agent, la cohérence est systématique. L’alignement est en tout cas parfait entre les outputs que les agents génèrent seuls et ceux qu’ils génèrent en exécution concurrente.
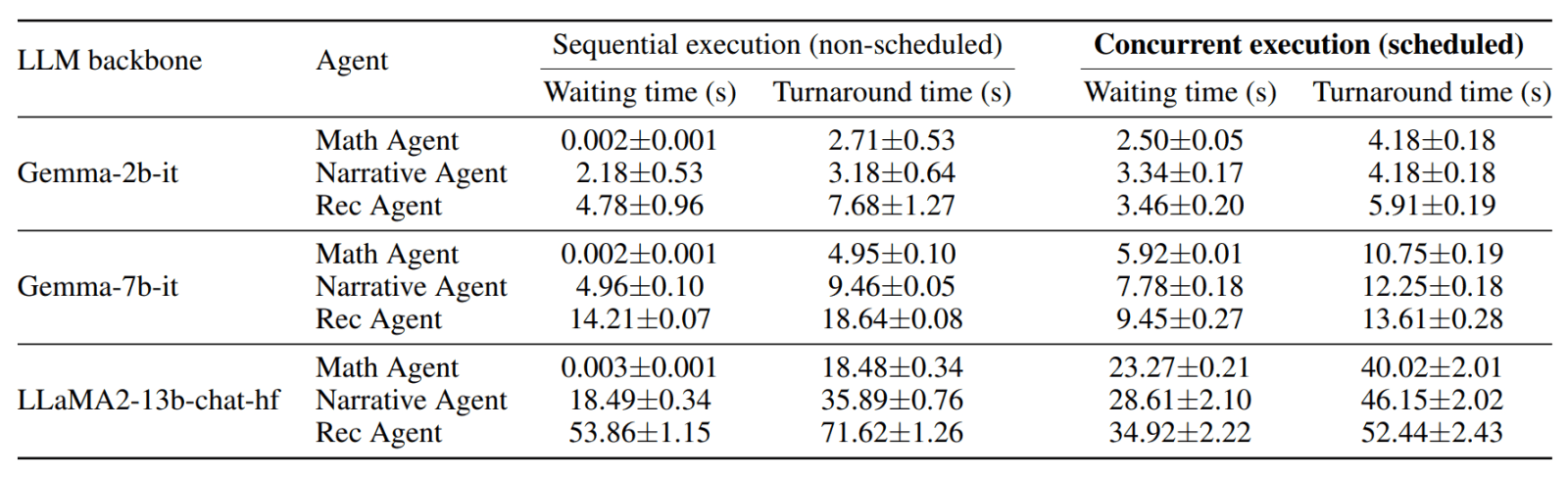
Pour répondre à la deuxième question, on compare le mode FIFO (premier entré, premier sorti) à une approche sans planification. Dans le cadre ce cette dernière, les trois agents s’exécutent dans un ordre prédéfini : maths, récit, restaurants.
On évalue deux indicateurs, mesurant l’intervalle entre la soumission d’une requête et respectivement, le début et la fin de l’exécution. Chaque agent adressant de multiples requêtes, on établit une moyenne.
Principale conclusion : sans planification, les performances déclinent à mesure qu’on avance dans la séquence de tâches.
Sur le même thème
Voir tous les articles Data & IA
Par Clément Bohic
8 min.Par Clément Bohic
Par Clément Bohic
Par Clément Bohic
Par Rémy Mandon *





