

BLOOM : les choses à savoir sur ce « méga-modèle » d'IA au sang français
Lancement acté pour BLOOM. Issu d'une démarche scientifique ouverte, ce modèle de langage multilingue a de multiples attaches en France.

Quel modèle de traitement du langage naturel entraîner quand on dispose d'un million d'heures GPU ? Le projet BigScience s'est trouvé face à cette question. Sa réponse s'incarne dans BLOOM.
Le projet @BigscienceW dévoile #Bloom, le plus gros modèle #TAL #NLP entraîné sur le #supercalculateur #JeanZay de manière complètement ouverte et transparente. Il gère plus de 46 langues et revêt un caractère #openscience @INS2I_CNRS @CNRS @huggingface https://t.co/pI8m3Aw0sE
- Genci (@Genci_fr) July 12, 2022
Les premiers jalons du projet BigScience avaient été posés au printemps 2021. À la baguette, Hugging Face. Cette entreprise, que trois Français ont fondée à New York, est à l'origine d'une plate-forme de data science / machine learning. L'objectif : entraîner, sur un modèle de science ouverte et participative, « le plus grand modèle de langue multilingue et open source ».
Au final, un millier de scientifiques se sont impliqués, représentant 72 pays et des sociétés comme Airbus, Meta AI, Mozilla, Orange Labs ou Ubisoft. La France a apporté un soutien dans le cadre de sa stratégie nationale pour l'IA.
3 millions d'euros pour un cycle d'entraînement
La phase d'entraînement s'est étalée sur 117 jours, entre mars et juillet 2022... sur le supercalculateur Jean Zay, localisé à Saclay (Essonne). Avec un environnement à 416 GPU NVIDIA A100 80 Go répartis sur une cinquantaine de noeuds AMD. La dotation en ressources de calcul - subvention CNRS + GENCI estimée à environ 3 millions d'euros - a permis de réaliser un peu plus d'un cycle.
À la base, il y a un fork de Megatron-DeepSpeed, qui lui-même dérive de Megatron-LM (modèle de langage made in NVIDIA à 345 millions de paramètres, architecturé sur le modèle de GPT-2 et entraîné sur Wikipédia, OpenWebText et CC-Stories).
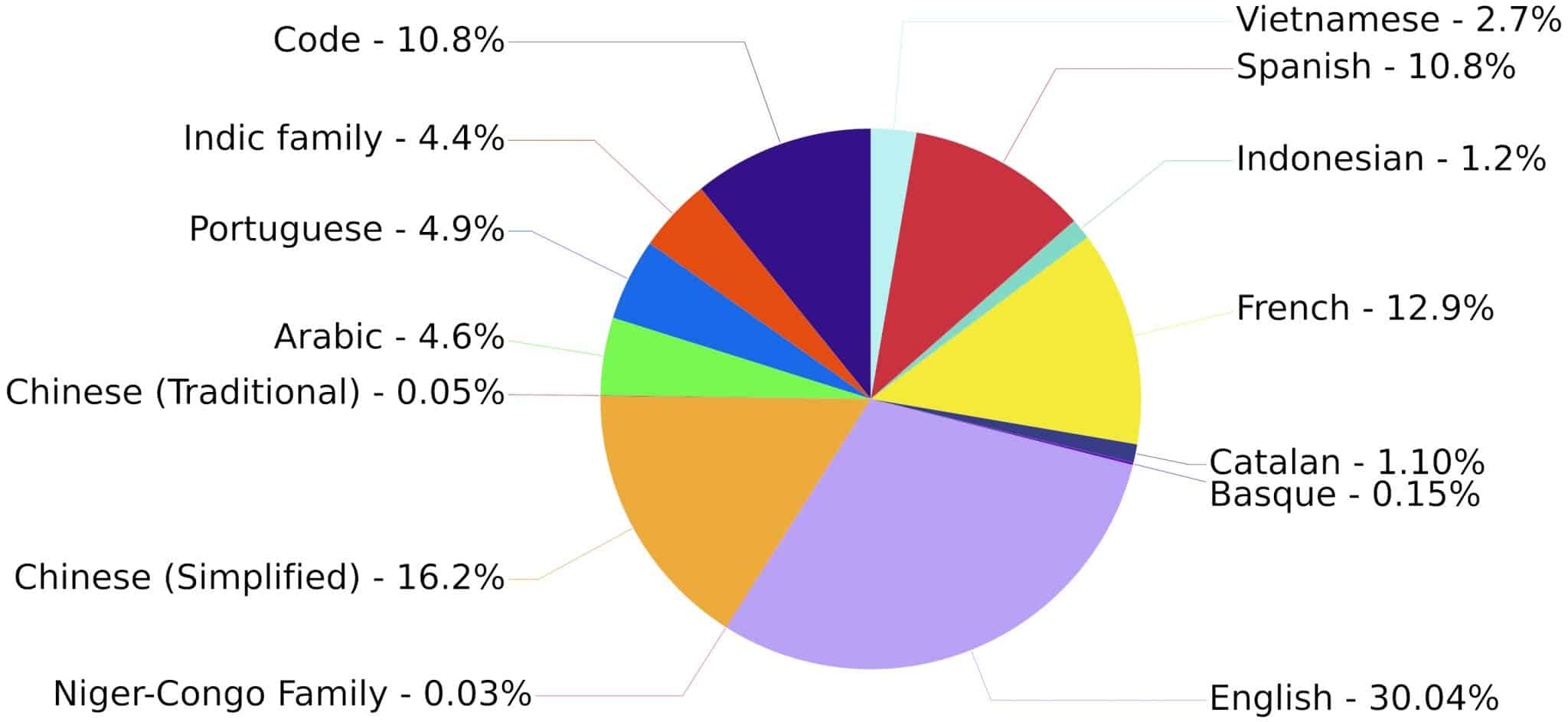
À l'arrivée, il y a BLOOM (BigScience Large Open-science Open-access Multilingual Language Model), ses 70 couches de neurones, ses 112 têtes d'attention et ses 176 milliards de paramètres. Par rapport à la référence GPT-3, il est entraîné sur un corpus plus varié : moins d'anglais, mais 45 autres langues. Ainsi que 13 langages de programmation (13 % du dataset) : C, C#, C++, Go, Java, JavaScript, Lua, PHP, Python, Rust, Scala et TypeScript. Au total, environ 1,6 To de données prétraitées, regroupées en 350 milliards de tokens.

BLOOM : un modèle « inclusif » ?
Cette diversité était - et reste - au coeur de la démarche de BigScience. L'IA « responsable » aussi. Cela se reflète dans la licence de BLOOM. Globalement permissive, mais qui pose des limites sur l'usage du modèle. Elle interdit notamment de s'en servir dans le cadre de l'aide médicale. De manière générale, BLOOM n'est pas conçu pour accompagner des décisions critiques (création de contenu factuel, scoring, résumé « fiable »...).
Principal usage de BLOOM : générer du texte (complétion d'énoncés). On pourra aussi le spécialiser pour d'autres tâches liées au traitement du langage. En l'état, l'exécution du modèle en inférence nécessite encore des ressources importantes. Il est prévu d'en réduire le poids tout en ouvrant une API connectée à Google Cloud.
Right now, 8*80GB A100 or 16*40GB A100. With the « accelerate » library you have offloading though so as long as you have enough RAM or even just disk for 300GB you're good to go (but slower)
- Thomas Wolf (@Thom_Wolf) July 12, 2022
'Don't have 8 A100s to play with? An inference API, currently backed by Google's TPU cloud and a FLAX version of the model, also allows quick tests, prototyping, and lower-scale use. You can already play with it on the Hugging Face hub.' https://t.co/vD5ESGUojo
- Leo Boytsov (@srchvrs) July 12, 2022
Illustration principale © pro motion pic - Fotolia
Sur le même thème
Voir tous les articles Data & IA
Par Clément Bohic
6 min.Par Clément Bohic
Par Clément Bohic
Par Clément Bohic
Par Clément Bohic








{kind=link}