

De BigScience à BigCode : la quête d'IA génératives « éthiques »
Dans la lignée du projet BigScience, BigCode tente d'appliquer la même logique « responsable » aux IA génératrices de code.

Vous souvenez-vous de BigScience ? Ce projet communautaire visait à concevoir « le plus grand modèle de langue multilingue et open source ». À la baguette, Hugging Face, entreprise que trois Français ont fondée à New York.
Les travaux avaient abouti, en juillet 2022, à la publication de BLOOM (BigScience Large Open-science Open-access Multilingual Language Model). Ils ont inspiré un autre projet, là aussi emmené par Hugging Face, en tandem avec ServiceNow : BigCode.
La notion d'IA « responsable » était au coeur de la démarche BigScience. Cela s'est reflété autant dans la composition du jeu de données d'entraînement que dans la licence du modèle qui en a découlé.
BigCode s'inscrit dans la même logique, mais sur le domaine de la programmation informatique. Et en allant plus loin sur plusieurs aspects. Notamment en détaillant, outre la composition du dataset, sa méthode de conception (masquage des données personnelles*, limitation du risque de production de code malveillant...).
BigCode : à licences permissives, dataset éthique ?
BigCode insiste sur le caractère « éthique » du dataset en question - nommé « The Stack » au sens où il ne contient que du code sous licences « permissives » (copyleft).
Comment en est-on arrivé à The Stack ? La première étape a consisté à détecter, via GHArchive, les dépôts GitHub publics actifs sur la période du 1er janvier 2015 au 31 mars 2022. Il en a résulté quelque 221 millions de résultats.
BigCode est parvenu à cloner environ 137 millions de dépôts qui étaient encore publiquement accessibles. Ensuite a commencé la phase de découverte des licences. Pour 26 millions de dépôts, elles étaient explicitement indiquées. Sur les 111 autres millions, on a utilisé le script go-license-detector... qui n'a rien détecté dans plus de 80 % des cas.
Une fois ce filtrage effectué, il restait un peu moins de 30 To de données. On a alors appliqué une double quasi-déduplication (procédure connue pour améliorer les performances des modèles entraînés). Ce qui a divisé le poids du dataset par près de dix.
On parle là de la première version de The Stack, qui incluait une trentaine de langages pour une vingtaine de licences. Depuis lors, on est passé à près de 400 langages et 200 licences (MIT et Apache 2.0 dominent au sein du corpus). Non sans en supprimer quelques-unes, considérées comme insuffisamment permissives. En l'occurrence, EPL, LGPL et MPL.
Pour qui souhaiterait qu'on n'inclue pas son code, il existe un moteur de recherche et un formulaire d'opt-out. L'outil permet autant les contrôles a priori (code intégré dans le dataset) qu'a posteriori (code que produisent les modèles de BigCode).
À portée de Codex ?
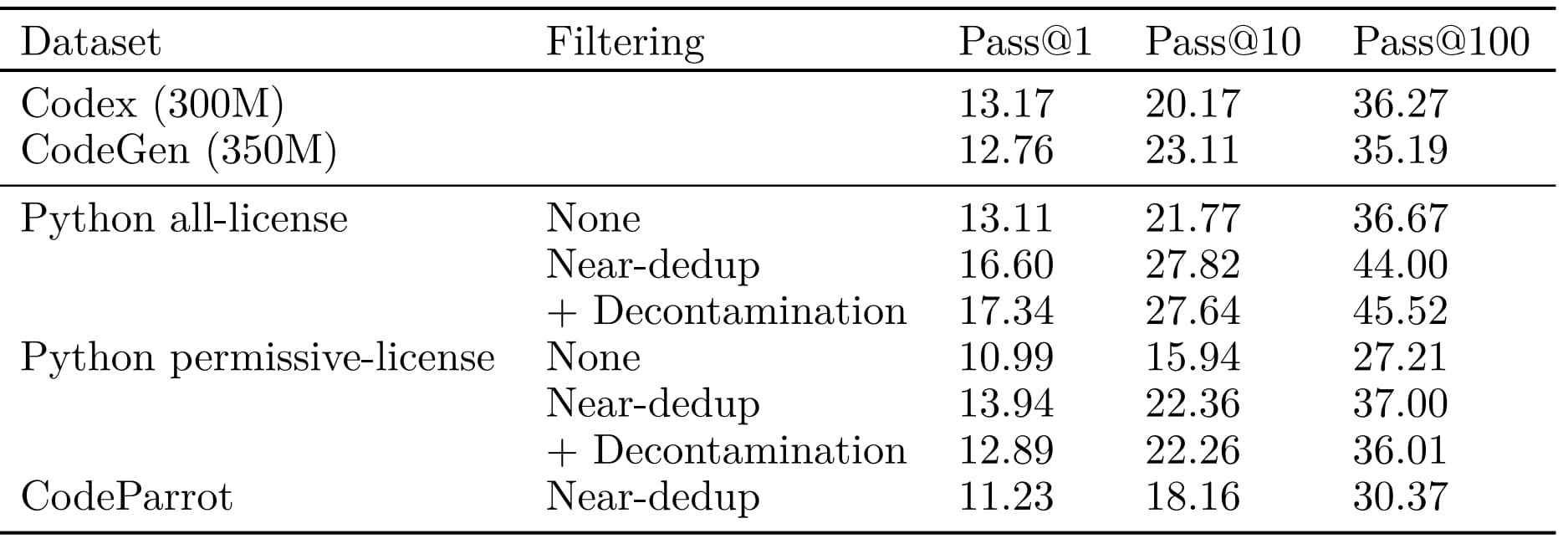
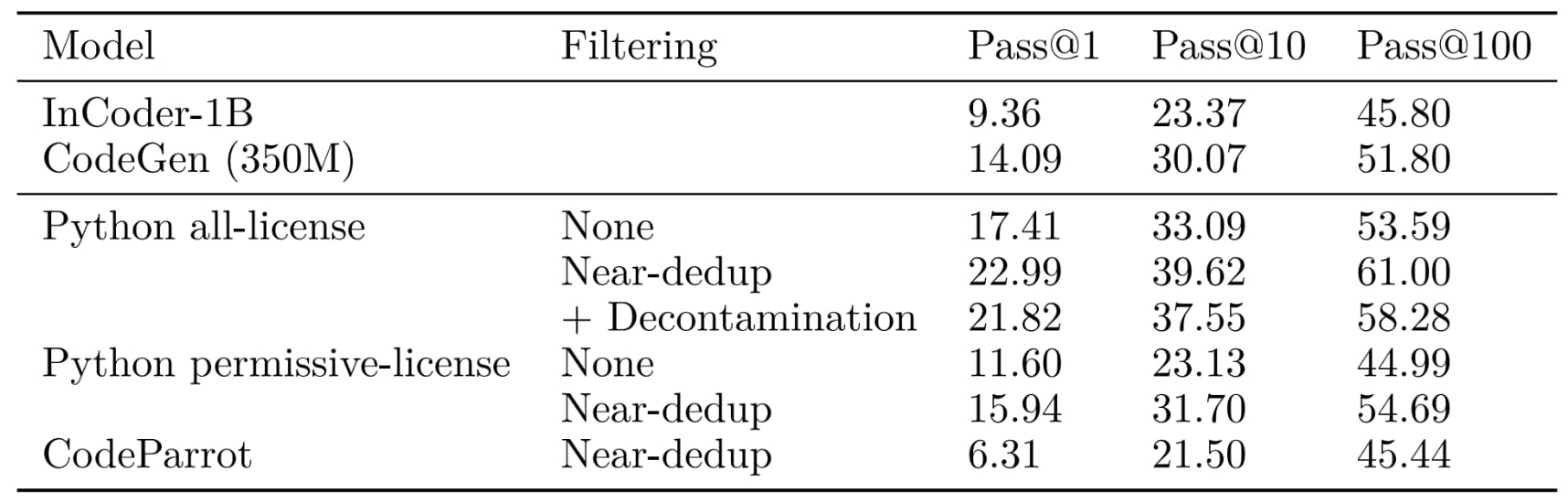
Se limiter à des licences permissives a-t-il un impact sur les performances ? Le benchmark référent de BigCode indique que non. Il a consisté à entraîner plusieurs modèles à 350 millions de paramètres sur un sous-ensemble Python issu de The Stack v1.
Conclusion : avec la quasi-déduplication, les performances sont équivalentes à celles de modèles Codex et CodeGen de taille similaire. En tout cas sur les tests de complétion HumanEval et MBBP.


SantaCoder, dans la lignée de BLOOM
BigScience avait développé BLOOM sur la base d'un clone de Megatron-LM, un modèle de langage made in NVIDIA architecturé à la manière de GPT-2. BigCode a repris ce substrat pour créer, sur la base de The Stack, une série de huit modèles, sous la bannière SantaCoder.
Tous ces modèles ont été formés sur du code Python, Java et JavaScript. Le plus « gros » d'entre eux a été entraîné deux fois plus longtemps que les autres (six jours et quelques sur un setup à 96 GPU Tesla V100, pour 2,1 x 1021 Flops. Il a 1,1 milliard d'hyperparamètres.
BigScience avait publié BLOOM sous la licence OpenRAIL-M. Dans les grandes lignes, elle est non restrictive sur la réutilisation, la distribution, la commercialisation et l'adaptation, mais elle interdit certains usages, par exemple dans le cas de l'aide médicale.
BigCode a réexploité cette licence pour les modèles SantaCoder et les fonctionnalités associées (de type checkpoints), moyennant quelques modifications. À commencer par le préambule, adapté aux IA génératrices de code. Mais aussi en supprimant l'incitation à utiliser autant que possible les dernières versions des modèles. Et en ajoutant une clause : tout code source produit sera sous licence Apache 2.0.
La licence OpenRAIL-M sous cette forme est provisoire, en attendant le lancement officiel de SantaCoder. Celui-ci est prévu pour mars.
* Pour détecter les adresses e-mail, BigCode a fait le choix des expressions régulières. Même chose pour les adresses IP. Pour les secrets, le projet a recours à un outil spécifique.
Illustration principale © pro motion pic - Fotolia
Sur le même thème
Voir tous les articles Data & IA
Par Clément Bohic
6 min.Par Clément Bohic
Par Clément Bohic
Par Clément Bohic
Par Clément Bohic








{kind=link}
{kind=link}