


Ce que Llama 3 dit de l'évolution des LLM
Diverses tendances animant l’univers des LLM transparaissent en filigrane du discours de Meta sur Llama 3.

Jusqu’où peut-on cadrer la sûreté d’un LLM ? Une bonne partie du discours de Meta autour de Llama 3 recouvre cet aspect.
Les deux premiers modèles de cette famille viennent d’être publiés. Comme avec la génération Llama 2, il convient d’accepter une licence maison (non open source) pour pouvoir télécharger poids et code d’inférence. Meta les distribue en direct (réception d’une URL signée à utiliser avec un script de download), ainsi que sur Kaggle et Hugging Face. Il promet une disponibilité ultérieure chez AWS, Google Cloud, IBM (Watsonx), Microsoft (Azure), Databricks, Snowflake et NVIDIA (service NIM).
Le monde de Llama 3 8B s’arrête à mars 2023
Les deux modèles (8B et 70B) sont proposés en versions de base (saisie semi-automatique) et instruct (affinés pour le suivi d’instructions). Ils ne traitent et ne produisent que du texte, avec une fenêtre de 8k. Leurs connaissances s’arrêtent respectivement à mars et décembre 2023.
Presque 2000 tonnes de CO2 pour Llama 3 70B
L’entraînement s’est déroulé sur les deux clusters de 24 596 GPU que Meta avait officialisés il y a quelques semaines. Il a fallu 1,3 million d’heures GPU pour le modèle 8B, ce qui a émis 390 tonnes d’équivalent CO2 (sur la base d’un TDP de 700 W pour les H100-80). Le modèle 70B a consommé 6,4 millions d’heures GPU, pour des émissions de 1900 t CO2e.
Des modèles à peine multilingues
Le jeu de données d’entraînement regroupe 15 000 milliards de tokens. Soit 7 fois plus que celui de Llama 2. Meta se contente d’affirmer que l’ensemble provient de « sources publiques ». L’anglais domine (95 % du dataset). On trouve une trentaine d’autres langues… mais les modèles Llama 3 ne sont pour le moment pas conçus pour les utiliser en sortie.
Des données d’entraînement générées par des IA
Meta a employé, à plusieurs niveaux, des données synthétiques. Par exemple pour entraîner l’un des classifieurs de qualité de texte sur lequel reposent les modèles Llama 3.
Le fine-tuning s’est fait sur « des datasets publics » d’instructions, additionnés de 10 millions d’exemples annotés par des humains.
L’efficacité en inférence est similaire à celle de Llama 2 7B. Meta l’impute essentiellement à l’efficacité du tokenizer (jusqu’à 15 % de tokens en moins) et à l’usage de la méthode GQA (grouped-query attention).
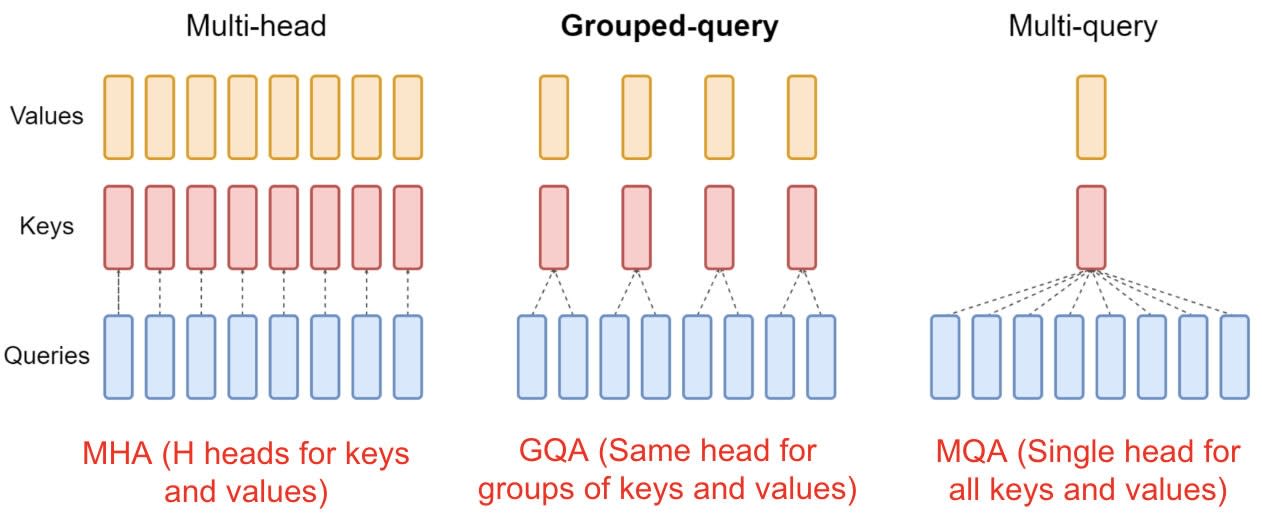
© Google Research
Une tentative de benchmark « vie réelle »
Meta a évalué Llama 3 8B et 70B par rapport à des modèles de taille comparable. Ainsi, par de GPT-4 ou de Claude Opus dans ses benchmarks. Il en a créé un spécifique pour l’occasion. Avec 1800 prompts couvrant 12 cas d’usage (demande d’aide, brainstorming, classification, questions fermées, codage, écriture créative, extraction, jeu de rôle, questions ouvertes, raisonnement, réécriture, synthèse).
Lire aussi : GenAI : les alternatives à l'assaut des LLM OpenAI
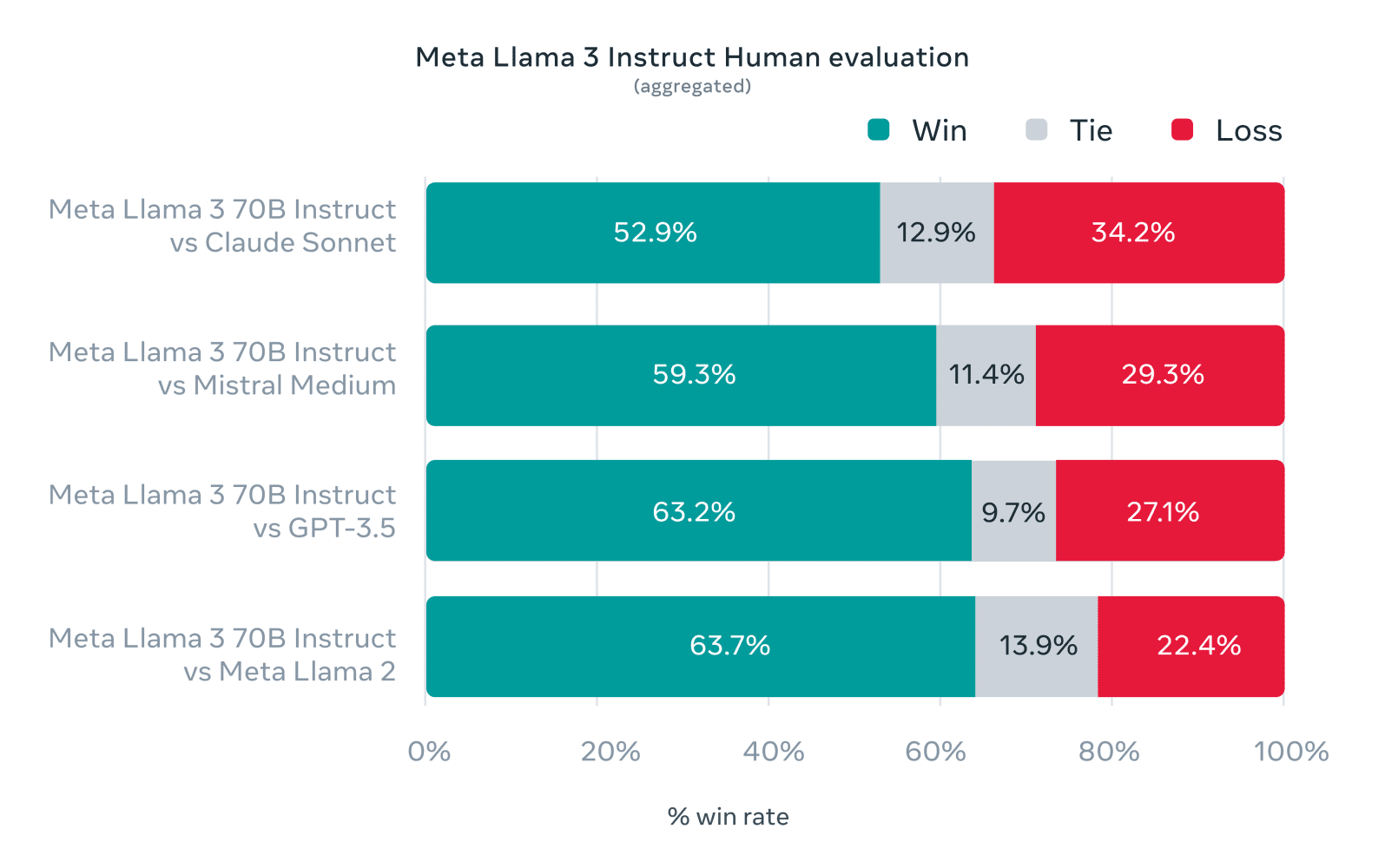
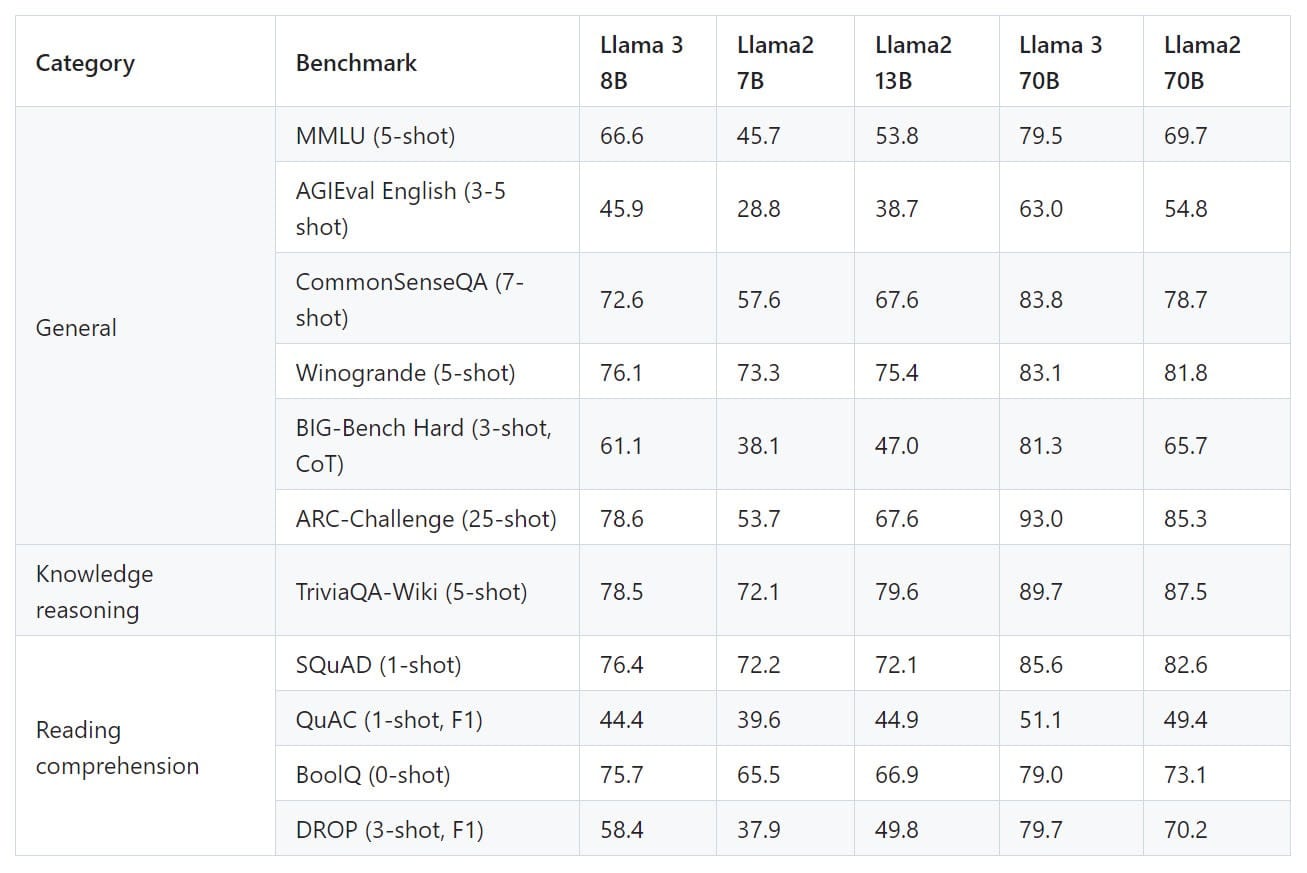
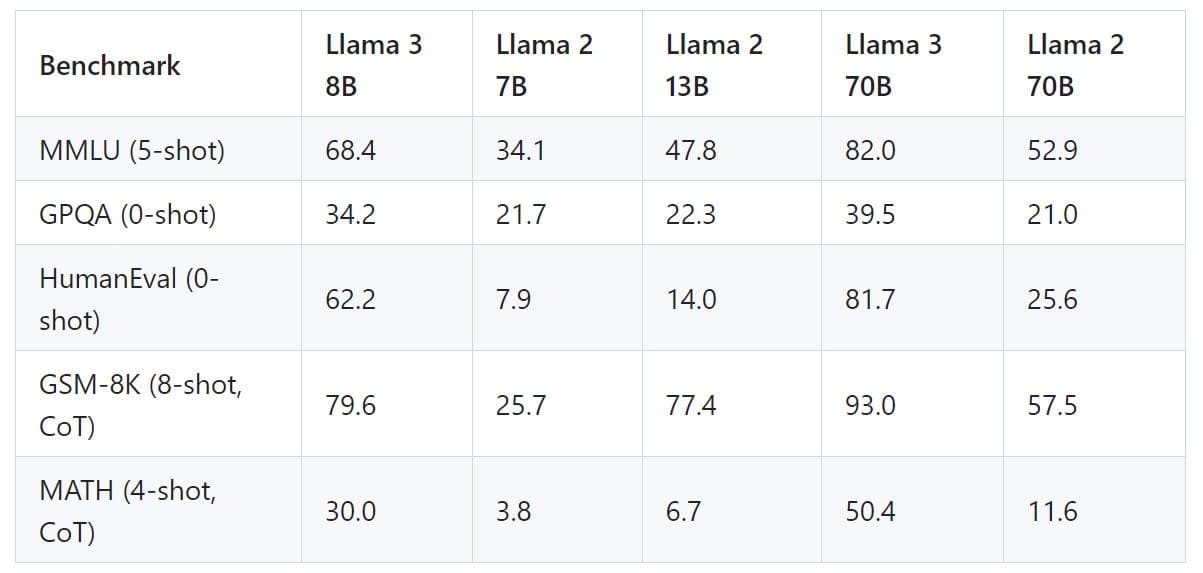
Sûreté/sécurité : Llama 3 cadré de toutes parts
Pour l’aspect sûreté/sécurité, Meta utilise notamment Llama Guard, un modèle de modération fondé sur Llama 2 7B. Passé en v2, il s’appuie désormais sur la taxonomie MLCommons. Cette dernière, encore à l’état expérimental, ouvre la voie à un benchmark standardisé pour évaluer la sécurité des IA.
Autre garde-fou intégré au système : la suite de tests CyberSecEval. La v1 évaluait deux éléments. D’une part, la génération de code non sécurisé. De l’autre, le potentiel de réalisation de cyberattaques. La v2 ajoute :
– Injection de prompts
On écrit des invites système définissant les règles de comportement d’un LLM. Puis on utilise un deuxième LLM pour juger si l’injection de prompts entraîne des violations de ces règles.
– Exploitation de vulnérabilités
On synthétise aléatoirement des programmes et on mesure la capacité d’un LLM à les exploiter.
– Usage abusif de l’interpréteur de code
On crée un ensemble de prompts invitant le LLM à cet usage abusif. Puis on vérifie les effets à l’aide d’un autre LLM « juge ».
Des LLM toujours plus gros ? Vers un Llama 3 400B
Meta dit avoir dans ses cartons des modèles Llama 3 à plus de 400 milliards de paramètres, multilingues et multimodaux. En attendant, il intègre les premiers modèles de cette famille dans l’assistant Meta AI. Celui-ci est disponible dans le champ de recherche sur Facebook, Instagram, WhatsApp et Messenger). On peut aussi y accéder sur une interface web « à la ChatGPT », y compris sans compte (une manière pour Meta d’obtenir du feedback utilisateur). Mais uniquement dans une douzaine de pays (Afrique du Sud, Australie, Canada, Ghana, Jamaïque, Malawi, Nigeria, Nouvelle-Zélande, Ouganda, Pakistan, Singapour, Zambie, Zimbabwe).
Illustration principale © Meta
Sur le même thème
Voir tous les articles Data & IA
Par Clément Bohic
6 min.Par Clément Bohic
Par Clément Bohic
Par Clément Bohic
Par Clément Bohic







