


Comment Dropbox applique le machine learning au nommage des fichiers
Dropbox relate son passage d'un moteur de règles à du machine learning pour l'identification de dates dans les noms de fichiers.

Détecter des dates dans des noms de fichiers ? Il y a DistilRoBERTa pour ça. Dropbox a en tout cas choisi cette option pour alimenter la définition de conventions d'appellation.
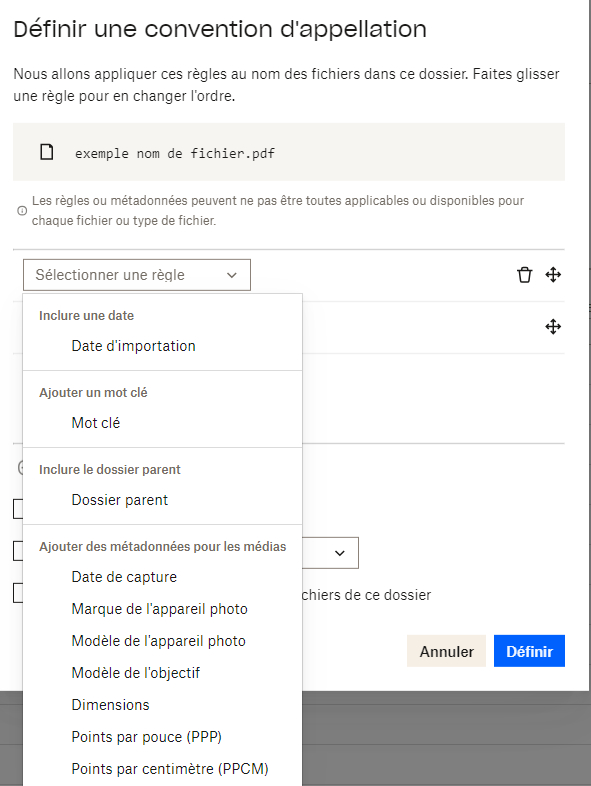
Cette fonctionnalité est disponible depuis fin 2021 sur la version web et l'application de bureau. Elle permet de renommer automatiquement les éléments déposés dans un dossier en fonction de règles qu'on aura définies au préalable.

Ces règles peuvent consister en l'ajout de mots-clés, l'inclusion du dossier parent ou l'insertion de métadonnées. On peut aussi inclure la date d'importation.

L'option « Date d'importation » permet de « remplacer les dates existantes détectées dans les noms de fichiers ». À l'origine, cela reposait sur un moteur à base de règles.

Face aux insuffisances de cette approche, Dropbox a formé un modèle d'apprentissage automatique. Et l'a mis en service en août 2022. À la clé, affirme-t-il, une augmentation de 40 % du nombre de fichiers renommés.
L'entreprise a eu recours à de l'apprentissage supervisé. Elle a conçu un jeu de données réunissant quelques milliers de noms de fichiers annotés - avec Doccano - afin de préciser la position des dates. Le développement d'un générateur de données synthétiques a permis de limiter le travail manuel.
Dropbox utilise DistilRoBERTa et SentencePiece
Les noms de fichiers ne comportent pas forcément que des dates. Pour permettre au modèle de comprendre le reste, on segmente l'ensemble en unités de sens, par tokenisation. Dropbox a opté pour l'algorithme SentencePiece, qui met en oeuvre une approche intermédiaire entre le découpages par mot et par caractère.
Les tokens qui en résultent sont étiquetés sur la base des annotations réalisées en amont. On utilise le système dit « Inside-Outside-Beginning » : chaque token est labellisé en fonction de sa position dans une entité (B s'il se trouve au début ; O à la fin ; I entre les deux).
L'ultime étape consiste à prédire ces « tags IOB ». C'est là que le transformer DistilRoBERTa entre en jeu. Pruning (suppression des paramètres non nécessaires) et quantisation (conversion en semi-précision) ont permis d'éliminer deux des six couches du modèle initial sans impacter les performances et en atteignant un niveau de latence acceptable, assure Dropbox.
Pour accompagner la prise en main par les utilisateurs, Dropbox a fini par suggérer automatiquement des conventions d'appellation en fonction des fichiers déjà présents dans un dossier donné. Il envisage, à l'avenir, de pouvoir identifier d'autres éléments, tels que des noms de lieux ou d'organisations. Et n'exclut pas, à ces fins, d'employer des LLM.
Illustration © natanaelginting - Adobe Stock
Sur le même thème
Voir tous les articles Data & IA
Par Clément Bohic
6 min.Par Clément Bohic
Par Clément Bohic
Par Clément Bohic
Par Clément Bohic








{kind=link}
{kind=link}
{kind=link}