

Keyframer : quand Apple applique GPT-4 au motion design
Des chercheurs d’Apple ont conçu Keyframer, un outil expérimental qui exploite GPT-4 pour l’animation graphique.

Qu’attendre de GPT-4 dans le domaine du motion design ? Trois chercheurs d’Apple ont signé un article qui donne des éléments de réponse. Le sujet : Keyframer, un outil expérimental qui s’appuie sur ce modèle à travers l’API Chat Completion d’OpenAI.
Keyframer crée des animations CSS à partir de fichiers SVG. Il encourage une démarche itérative, autant en autorisant les séquences d’invites que l’édition du code ou de ses propriétés.
La première phase de l’expérience a consisté à interroger, dans une « grande entreprise technologique », des profils – designers, devs front-end, techniciens de prototypage… – dont le métier touchait à l’animation graphique. Sur 27 réponses, les chercheurs en ont retenu 9. Sur cette base, ils ont défini les grands axes de Keyframer. Parmi eux, l’affinage itératif, donc, mais aussi la capacité d’exploration (création et comparaison de variantes) et de prise en main par les non-experts en code.
Keyframer comprend :
– Une zone d’insertion du code SVG
Le rendu s’affiche à côté du code. Le langage SVG étant basé sur XML, le LLM peut exploiter des éléments comme les identifiants d’objets.
– La zone d’invite
– La zone de sortie
La réponse, composée d’un ou plusieurs fragments de CSS, est diffusée en flux. Pour faciliter la tâche aux utilisateurs novices, GPT-4 génère des noms descriptifs pour les images clés (keyframes).
– La zone de rendu
Le rendu visuel de chaque animation s’accompagne d’une phrase explicative. En cas d’affichage de plusieurs versions, chaque fragment CSS se voit attribuer une classe. Un bouton permet d’affiner un design par davantage d’invites. Deux éditeurs permettent de modifier respectivement le code et les propriétés CSS. Le premier repose sur CodeMirror. Il gère coloration syntaxique et saisie semi-automatique. Le second propose une UI spécifique à chaque propriété. Par exemple, un sélecteur pour éditer les couleurs ou un menu déroulant pour éditer les courbes de fonctions temporelles.
« Décomposé » ou « holistique » ? Keyframer, révélateur de stratégies
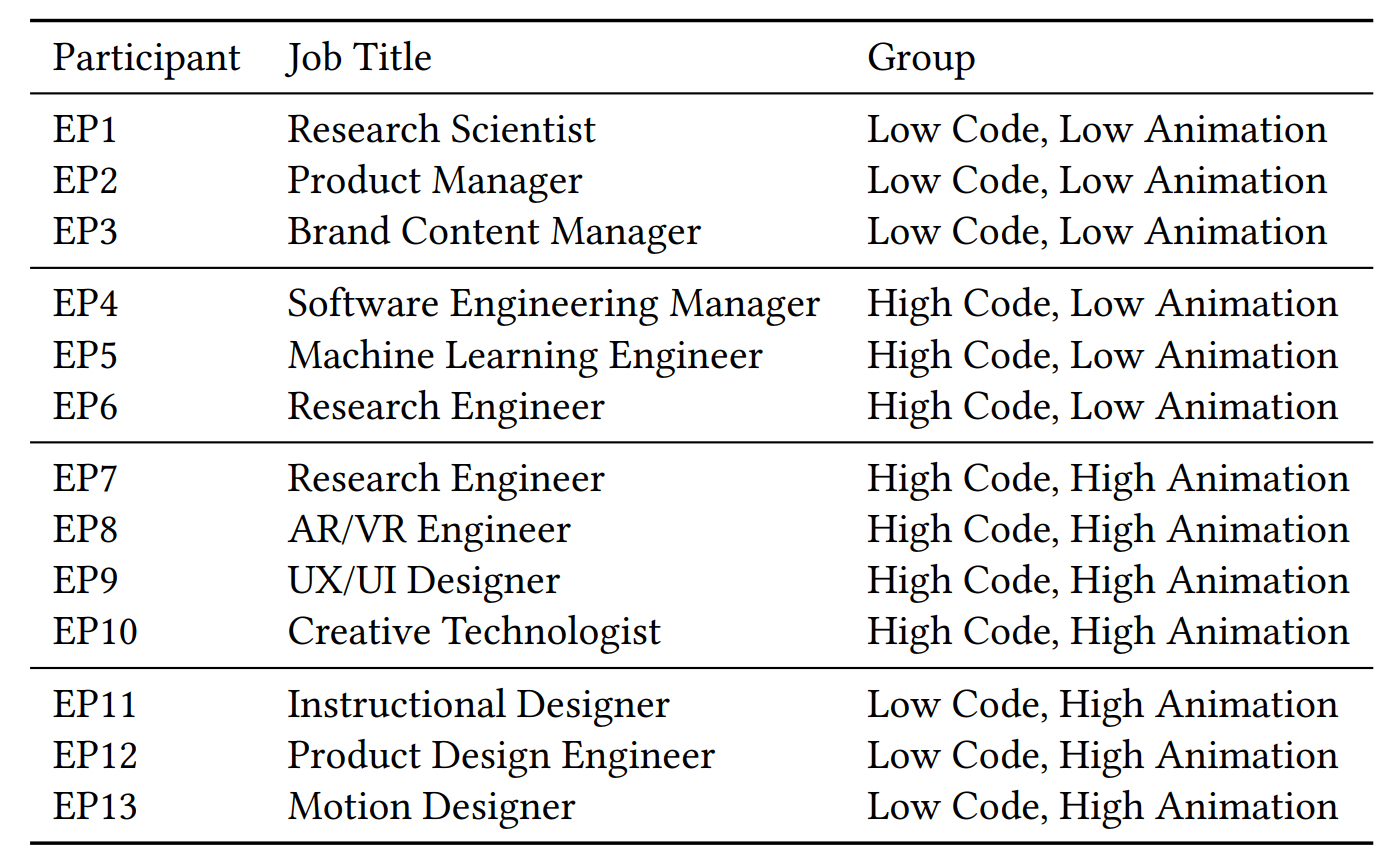
Keyframer a fait l’objet d’une expérimentation auprès de 13 personnes, réparties de manière quasi homogène entre quatre groupes.

On a présenté aux participants un scénario dans lequel ils devaient réaliser des animations pour le site perso d’un ami illustrateur de livres pour enfants. Le matériel : deux images. Une de la planète Saturne comportant 20 éléments uniques. Une autre d’une fusée comportant 19 éléments. Les surfaces : un en-tête et une newsletter.
En moyenne, Keyframer a mis 17,4 secondes pour répondre aux invites. Il a généré du CSS syntaxiquement erroné dans 6,7 % des cas.
La gestion du séquençage, en particulier, a posé des problèmes. Illustration avec l’invite « faire briller les étoiles ». Elle appliquait l’animation de manière uniforme, alors que les utilisateurs attendaient que les étoiles scintillent indépendamment les unes des autres. Raison : la présence d’une spécification de groupe dans le code SVG (<g id »sparkles »>).
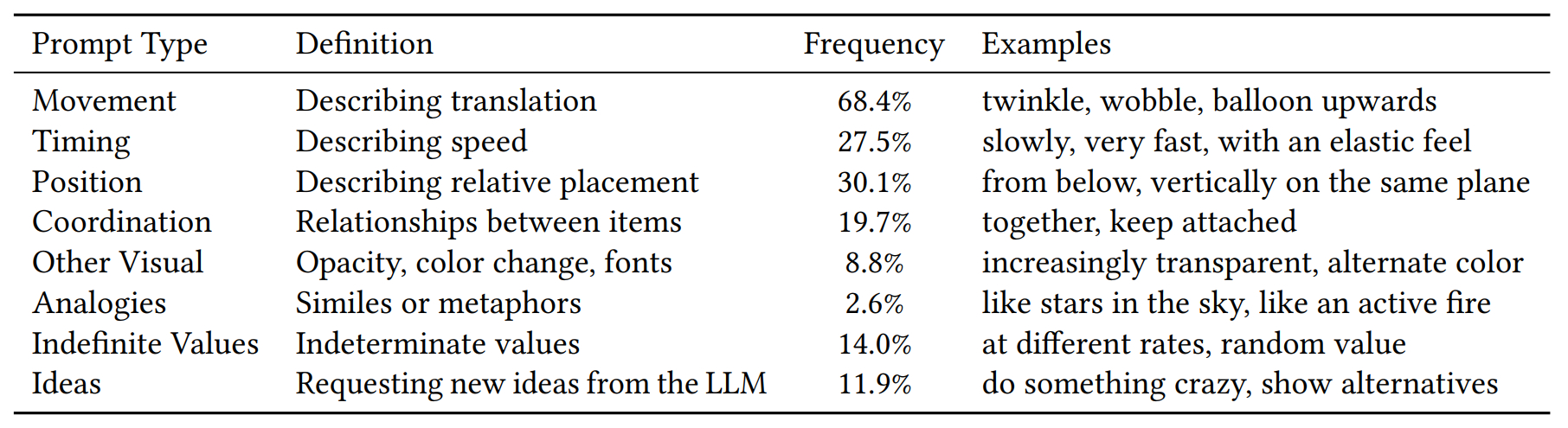
Les 205 invites uniques qu’on générées les participants ont permis de dégager deux grands aspects dans les stratégies de conception. D’un côté, l’approche « décomposée » vs l’approche « holistique ». De l’autre, les invites « spécifiques » vs les invites « sémantiques ».
Les stratégies « décomposées » impliquent l’animation des éléments un par un : parvenu à un état satisfaisant, on bascule sur un autre, etc. Les stratégies « holistiques », observées chez 4 utilisateurs, visent à animer simultanément plusieurs éléments, souvent en définissant la coordination ou le timing attendu.
Les invites « spécifiques » (34,6 % du volume de prompts uniques) impliquent l’usage de mots-clés (opacité, rotation, échelle…) et de valeurs attendues. Les invites « sémantiques » (84,4 % du volume global) sont plus génériques et descriptives (exemple : « faire bouger les nuages »). Elles sont plus fréquentes dans le groupe LCHA (Low Code, High Animation).

Interactivité, explicabilité… Des pistes pour le motion design à base de LLM
Les chercheurs ont constaté une satisfaction globale vis-à-vis des résultats qu’ont produits les invites sémantiques. Et de leurs avantages en matière d’expression de la créativité du LLM.
Lorsque la réponse ne convenait pas, les explications générées en complément de chaque fragment CSS ont pu aider. Même chose pour les noms de keyframes. Et, dans une certaine mesure, la diffusion en flux, donnant une forme d’« aperçu dans la boîte noire », pour reprendre les termes d’un utilisateur.
Certains ont fait part de leur souhait d’un processus plus interactif, où le LLM pourrait fournir du feed-back. Par exemple en posant des questions : « Voulez-vous bien dire cela ? », « Voulez-vous faire ceci à la place ? »… D’autres ont proposé que l’outil fasse des suggestions au sein même des invites, comme colorer des mots-clés.
La capacité à générer plusieurs versions a essentiellement permis d’orienter le travail. Elle a moins servi une fois le cap fixé. Aussi beaucoup d’utilisateurs ont-ils demandé que cette fonctionnalité reste en opt-in.
La possibilité de modifier non pas le code mais les propriétés CSS a favorisé l’usage de l’éditeur, estiment les chercheurs (80 % de taux d’usage chez les Low Code).
À consulter en complément :
MGIE : les travaux d’Apple sur les LLM multimodaux
L’approche d’Apple pour des LLM frugaux en mémoire
LLM et smartphones : l’exemple MobileDiffusion
Peugeot va intégrer ChatGPT dans son assistant vocal
Illustration © faithie – Adobe Stock
Sur le même thème
Voir tous les articles Data & IA![Déployer l'IA à l'échelle : l'approche d'AXA, entre vision et [...]](https://cdn.edi-static.fr/image/upload/c_lfill,h_201,w_298/e_unsharp_mask:100,q_auto/f_auto/v1/Img/BREVE/2025/4/473364/deployer-echelle-approche-axa-L.jpg)
Par Philippe Leroy
4 min.Par Philippe Leroy
Par Clément Bohic
Par Clément Bohic
Par Clément Bohic








{kind=link}
{kind=link}