

Les recettes d'Apple pour entraîner des LLM multimodaux
Apple donne un aperçu supplémentaire de ses travaux LLM multimodaux avec un article consacré à leur entraînement.

Où en sont les travaux d'Apple sur les LLM multimodaux ? Ces dernières semaines, plusieurs articles scientifiques ont donné des éléments de réponse.
L'un d'entre eux propose de s'appuyer sur un tel modèle pour enrichir les instructions que donne l'utilisateur dans le cadre de l'édition d'images. Un autre présente un outil qui exploite GPT-4 pour créer des animations CSS à partir de fichiers SVG.
On peut désormais y ajouter un article consacré à l'entraînement de LLM multimodaux - traitant plus précisément texte et images en entrée et produisant du texte.
Lire aussi : MGIE : les travaux d'Apple sur les LLM multimodaux
Les chercheurs partent d'une configuration de base qu'ils modifient un composant après l'autre, qu'il s'agisse de modules ou de sources de données. Cette configuration est la suivante :
- Encodeur d'images : un modèle ViT-L/14 entraîné avec une perte CLIP sur DFN-5B et VeCap-300M ; images en 336 x 336 pixels
- Connecteur vision-langage : C-Abstractor avec 144 tokens d'image
- Données : 45 % d'images légendées, 45 % de documents mêlant texte et images, 10 % de texte
- Modèle : décodeur transformeur à 1,2 milliard de paramètres
Les choix d'architecture...
Au niveau de l'encodeur, la résolution d'image apparaît comme l'élément ayant le plus gros impact sur les performances finales. Passer de 224 à 336 pixels de côté améliore le score d'environ 3 % sur tous les indicateurs.
Doubler la taille du modèle (passage de ViT-L à ViT-H) a moins d'impact (moins de 1 % de gain). Ajouter un dataset de légendes synthétiques (VeCap-300M) en a encore moins (moins de 1 % de gain en few-shot).
Concernant la passerelle vision-langage, le nombre de tokens visuels est l'élément qui importe le plus. Suit la résolution de l'image. Le type de connecteur a peu d'effet.
... et de données
Sur le volet des données, les chercheurs d'Apple tirent quatre leçons :
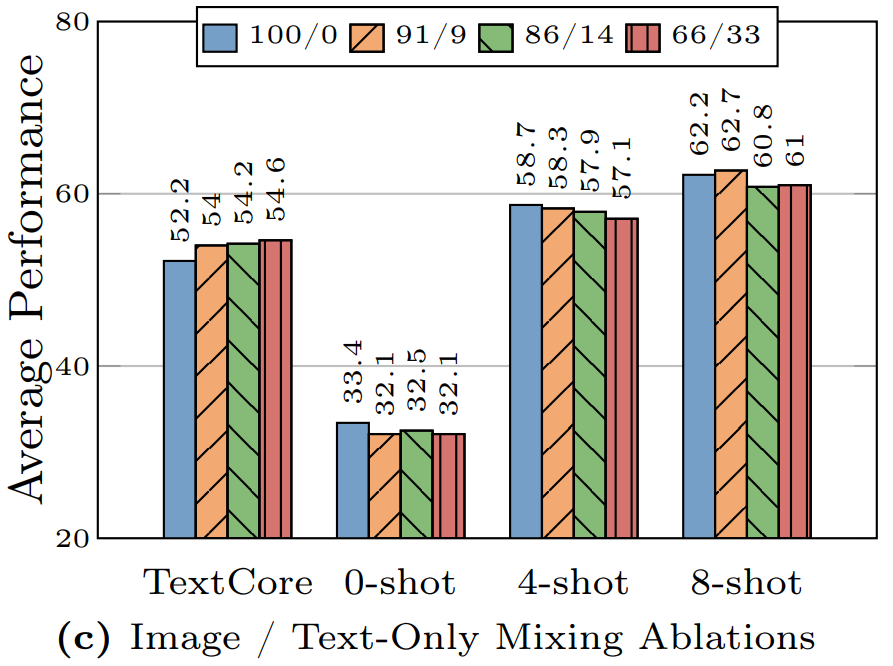
- Les paires image-légende tendent à améliorer les performances en 0-shot, tandis que les documents mêlant texte et image sont fondamentaux pour la performance en few-shot.
- Les données 100 % texte se révèlent utiles autant en few-shot que dans les situations où le modèle n'a que du texte en entrée.
- Pour optimiser à la fois la performance en entrée multimodale et texte seul, le ratio idéal entre paires images-légende, documents image-texte et données pur texte est de 5:5:1.
- Les données synthétiques aident à l'apprentissage en few-shot.
Des avantages conservés après finetuning
Ces expérimentations ont abouti au maintien de la « recette » de base, à l'exception de l'encodeur, modifié pour un Vit-H à 378 x 378 pixels.
À partir de ce socle, les chercheurs ont développé une famille de modèles 3B, 7B et 30B, les ont déclinés en version Instruct/Chat et y ont ajouté des versions MoE (3Bx64, 7Bx32, suivant les méthodes GShard et ST-MoE).
Pour tous, même recette d'entraînement : 200 000 étapes (environ 100 milliards de tokens), jusqu'à 16 images par séquence (512 séquences par lot), avec le framework AXLearn.
Lire aussi : Modèles text-to-video : avec qui voisine Sora ?
D'après les résultats qu'avance Apple, ses modèles MM1 s'en tirent systématiquement mieux en few-shot que les autres. Ces « autres » sont Flamingo, Emu2 et IDEFICS.
En 0-shot, les MM1 ont essentiellement l'avantage sur le benchmark de légendage TextCaps, y compris sans finetuning.
Ces avantages sont conservés après finetuning. Et les modèles MoE se révèlent plus performants que les modèles « standards ». Augmenter davantage la résolution d'entrée entraîne encore des gains supplémentaires (+15 % en passant de 336 x 336 à 1344 x 1344 pixels).
Illustration principale © faithie - Adobe Stock
Sur le même thème
Voir tous les articles Data & IA![Déployer l'IA à l'échelle : l'approche d'AXA, entre vision et [...]](https://cdn.edi-static.fr/image/upload/c_lfill,h_201,w_298/e_unsharp_mask:100,q_auto/f_auto/v1/Img/BREVE/2025/4/473364/deployer-echelle-approche-axa-L.jpg)
Par Philippe Leroy
4 min.Par Philippe Leroy
Par Clément Bohic
Par Clément Bohic
Par Clément Bohic






{kind=link}