

Vers une pénurie de données d'entraînement pour l'IA ?
À quand l'éventuel épuisement des stocks de données pour les modèles de langage et de vision ? Une étude se penche sur le phénomène.

De la data « de haute qualité », c'est quoi au juste ? Des chercheurs se sont confrontés à la question en examinant trois jeux de données : The Pile, MassiveText et celui qui a servi à entraîner PaLM. En toile de fond, une question : risque-t-on un jour de manquer de matière pour former des modèles de machine learning ?
Cette étude n'est pas, et de loin, la première sur le sujet. Elle s'inspire d'ailleurs de travaux précédents ayant par exemple permis d'estimer le taux annuel de croissance des datasets. La méthodologie est toutefois spécifique, et pas seulement parce qu'elle touche à la qualité des données.
Le périmètre d'étude a englobé deux disciplines : le traitement du langage et la vision. Sur chacun de ces plans, on a estimé l'évolution du stock disponible de données non étiquetées. Puis on l'a rapporté à l'évolution de la taille des datasets pour déterminer à partir de quand il serait théoriquement épuisé.
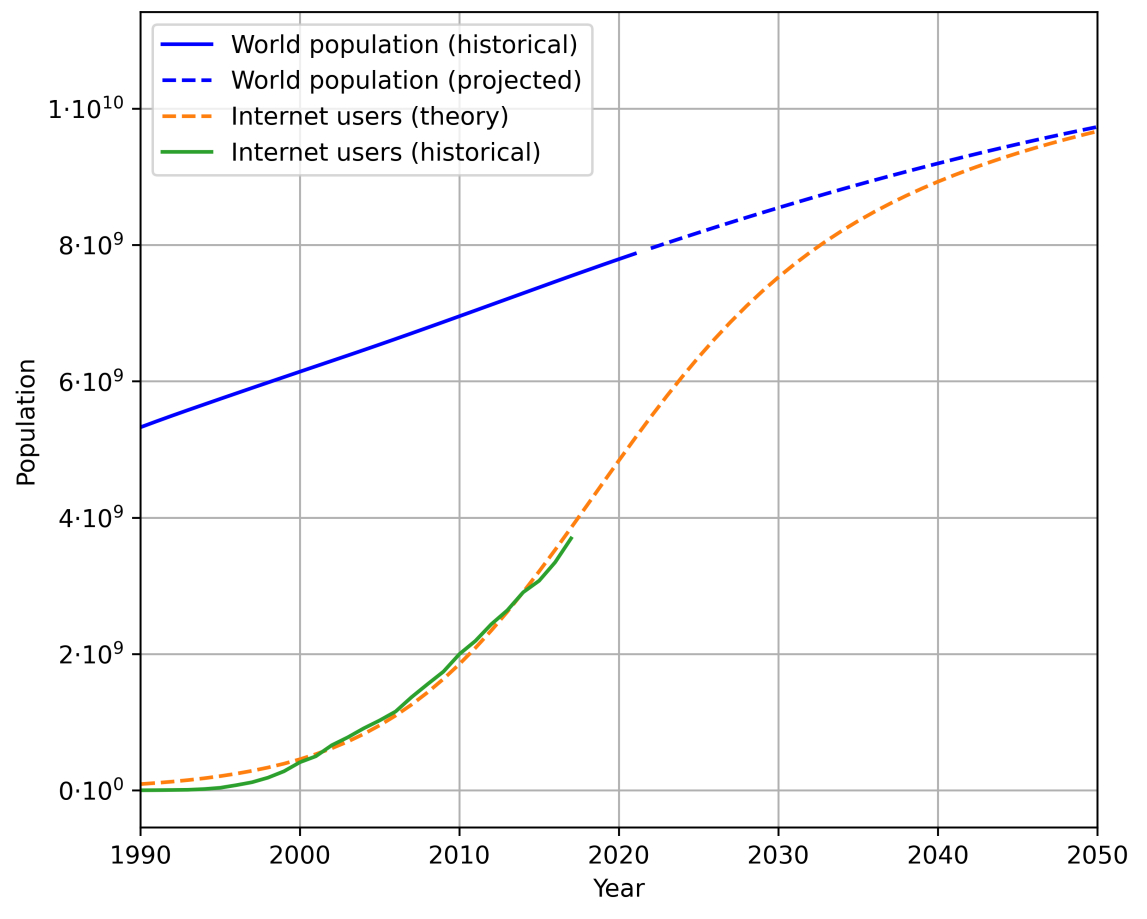
Le calcul de l'évolution du stock a reposé sur trois paramètres majeurs. En l'occurrence :
- Croissance de la population mondiale (projections de l'ONU)
- Taux de pénétration d'Internet (source : Our World in Data)
- Quantité moyenne de données produite par utilisateur (on la suppose constante)

Pour ce qui est de l'évolution de la taille des datasets, on a utilisé deux méthodes d'extrapolation. L'une basée sur les données historiques (tableau ci-dessous). L'autre, sur la « taille optimale »* étant donné les ressources de calcul à disposition et les lois actuelles de mise à l'échelle.

En octobre 2022, le plus gros jeu de données dans le domaine du langage contenait 2 x 1012 mots.
Qu'en est-il du stock de données disponible ?
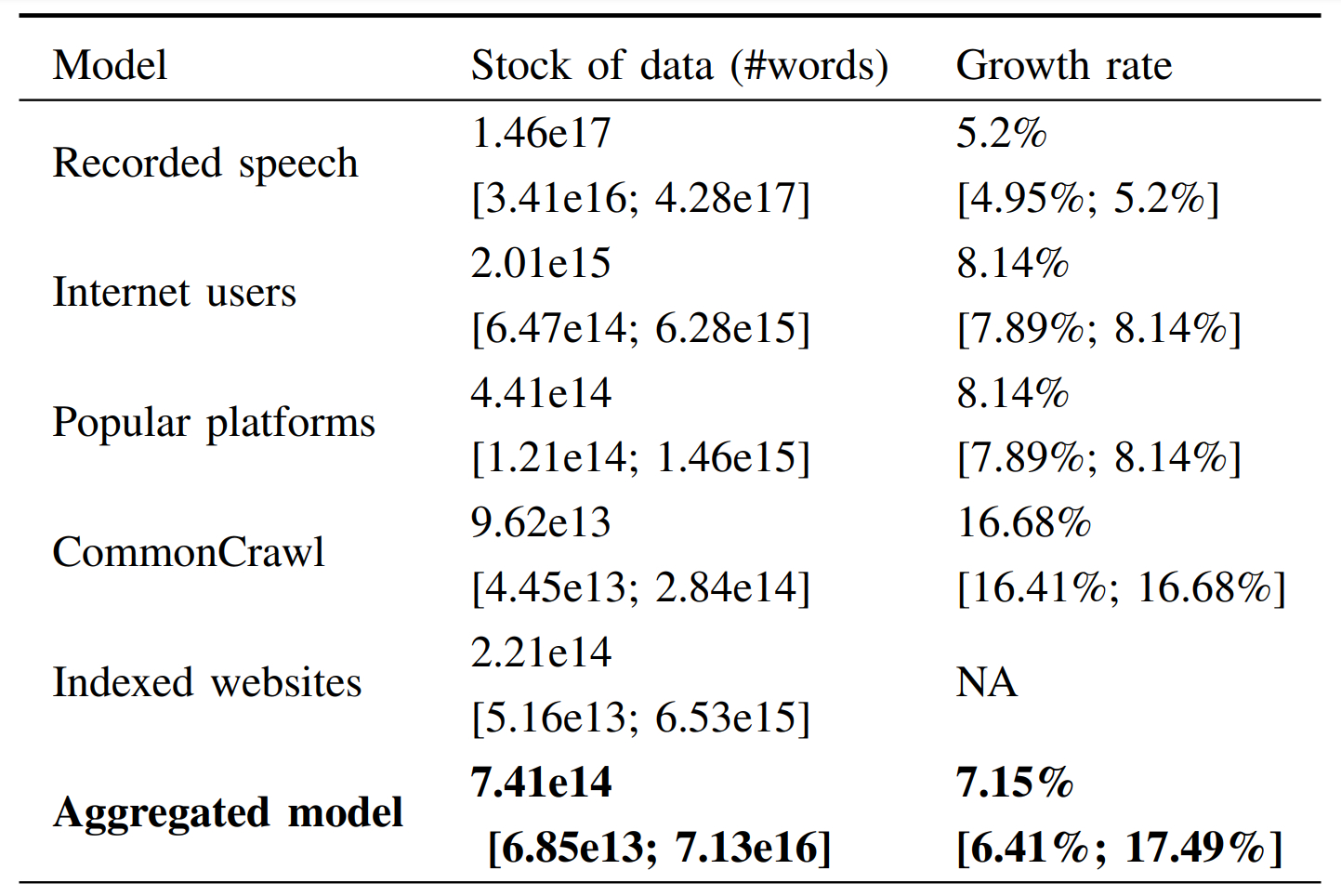
Sur la partie langage, la médiane des estimations ressort à 7,41 x 1014 mots, avec un taux de croissance annuel médian de 7,15 %.
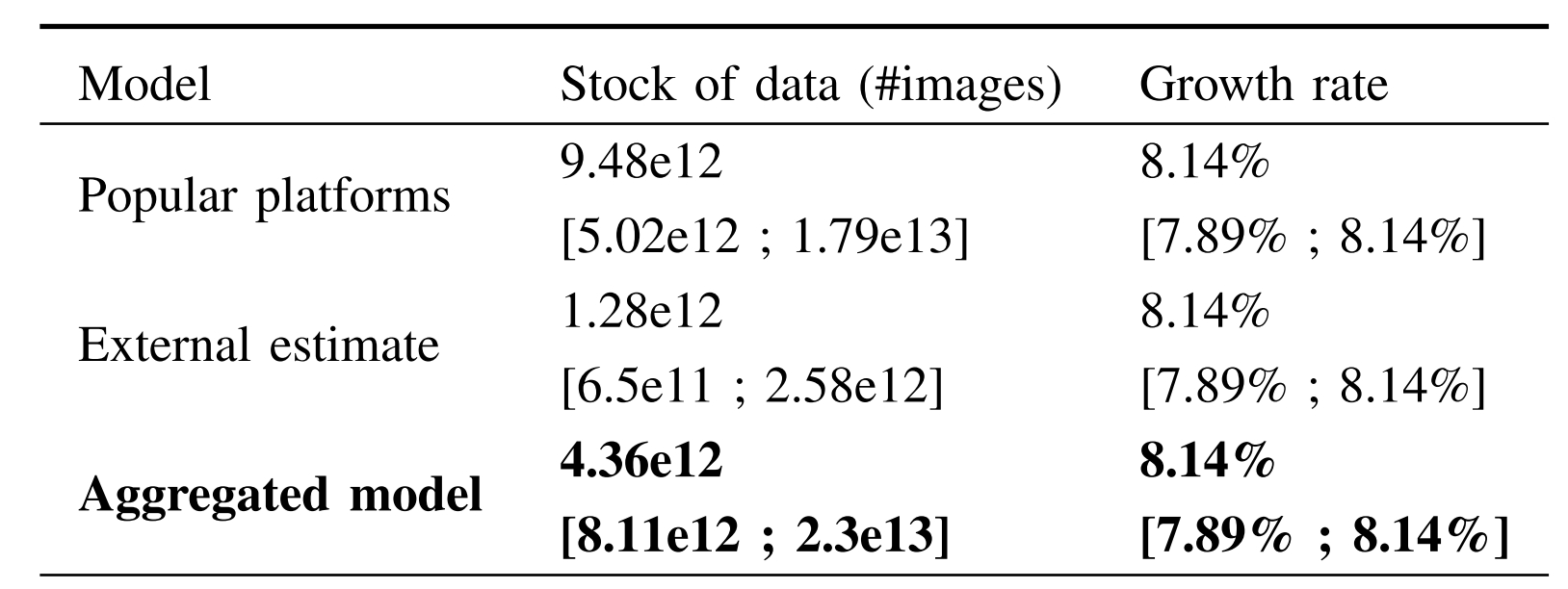
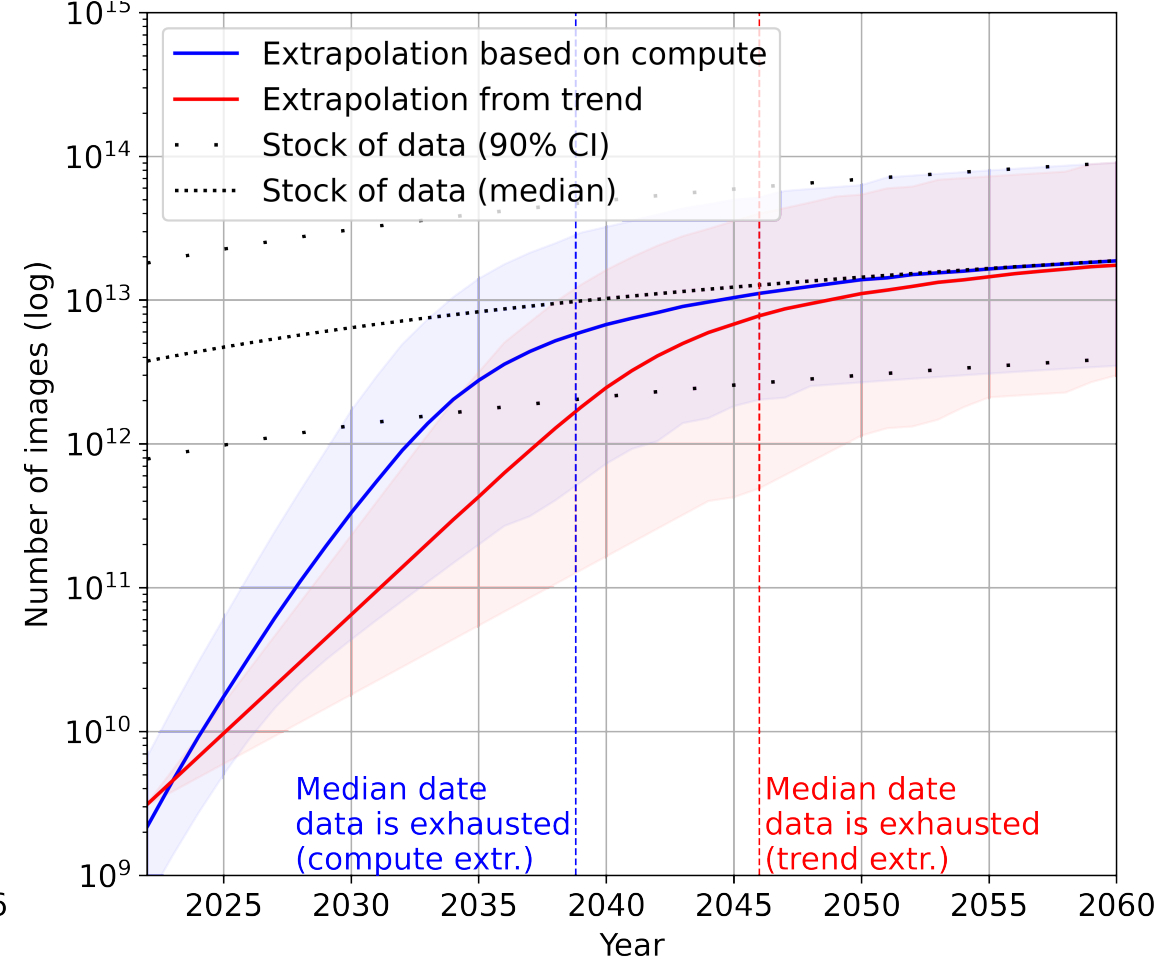
Sur la partie vision, on en est à 4,36 x 1012 images (croissance annuelle : 8,14 %).


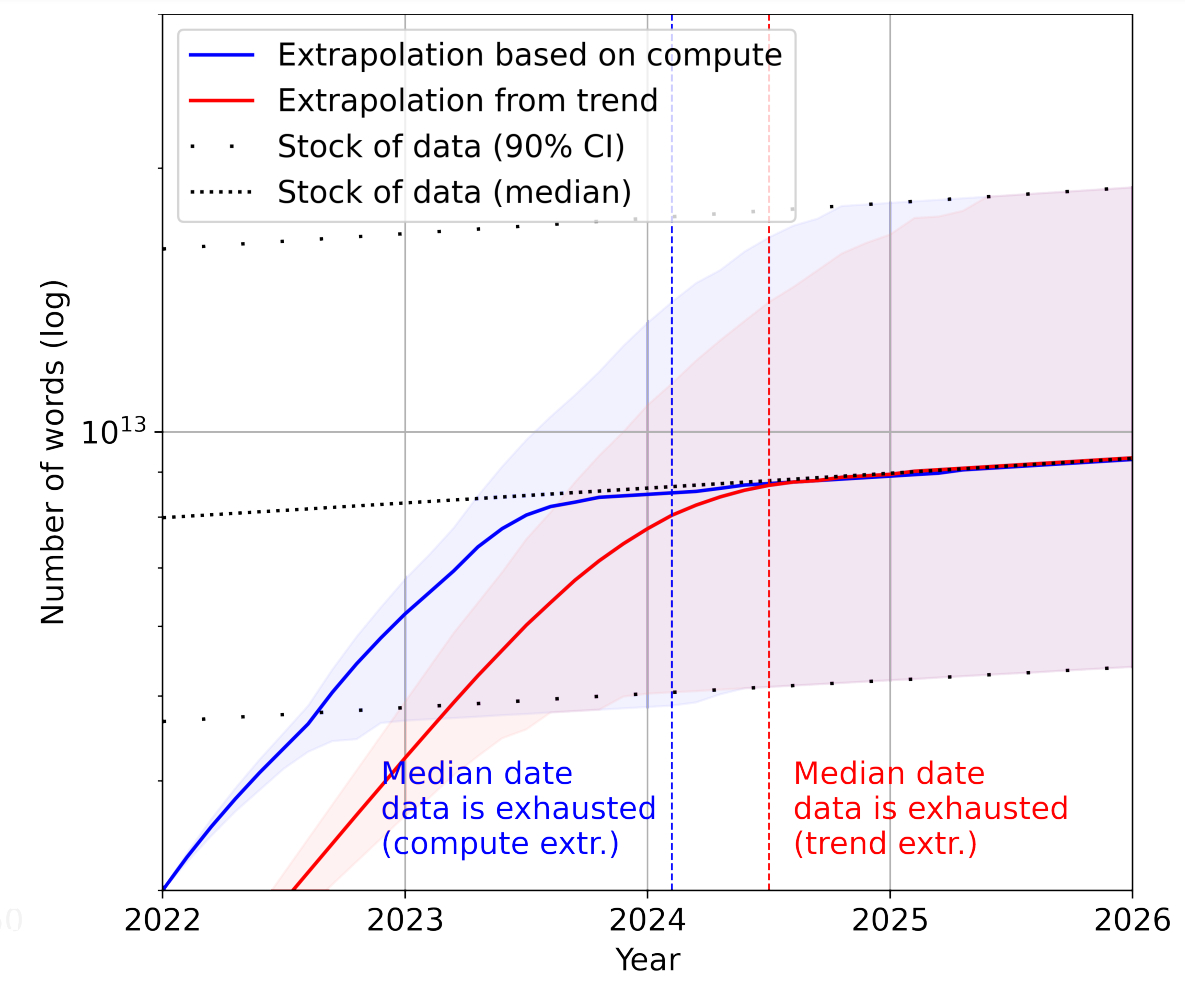
Certains stocks épuisés en 2026 ?
Sur la foi de ces estimations, on devrait commencer à manquer de données de langage entre 2030 et 2050.

En rouge, la taille des datasets extrapolée à partie des données historiques. En bleu, à partir de l'évolution estimée des ressources de calcul.
Si on s'en tient aux données de haute qualité (entre 4,6 x 1012 et 1,7 x 1013 mots), l'épuisement des stocks interviendrait au plus tard en 2026.

Dans le domaine de la vision, le stock de données d'entraînement croît en moyenne de 8 % par an. Alors que la taille des datasets augmente de 18 à 31 %. Dans ces conditions, un épuisement est à prévoir entre 2030 et 2060. Une fourchette peu précise qui tient notamment à une moins bonne compréhension des lois de scaling que pour le langage.

L'étude présente d'autres limites. Elle n'aborde pas, entre autres, le cas des données synthétiques. Ni les progrès dernièrement constatés en matière de frugalité des modèles d'apprentissage automatique. De même, la disponibilité de ressources de calcul est sujette à variations. Le taux de production de données aussi (les chercheurs ont considérée qu'elle était proportionnel au taux de croissance de l'économie mondiale).
* La taille « optimale » est définie comme fonction de la racine carrée du budget calcul.
Illustration principale © aapsky - Adobe Stock
Sur le même thème
Voir tous les articles Data & IA
Par Clément Bohic
3 min.Par Clément Bohic
Par Clément Bohic
Par Alain Clapaud
Par Clément Bohic








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}