

Comment Uber a unifié ses déploiements de configuration
Uber a mis en place un système unifié pour distribuer ses mises à jour de configuration. Comment s’architecture-t-il et quels en sont les bénéfices ?

Comment faire le pont entre déploiement de code et déploiement de configuration ? En utilisant une brique partagée de gestion du changement. Telles sont en tout cas les perspectives d’Uber, maintenant qu’un autre chantier est terminé.
Ce chantier a consisté à consolider en un système la gestion et la distribution des mises à jour de configurations. Au départ, il y avait de multiples produits. Certains avec une UI web, d’autres avec une interface Git. Mais aussi avec des composantes communes… et par là même mutualisables. En l’occurrence, principalement :
– Magasin pour stocker les configurations
– Générateur pour traduire les configurations en un format consommable
– Pipeline de distribution
– Mécanisme de déploiement
– Clients de configuration
Les pipelines existants posaient divers problèmes. Par exemple en matière d’élasticité – certains fonctionnaient en pull, alourdissant la charge réseau. Plus globalement, avoir plusieurs pipelines – et donc d’autant plus d’agents – était coûteux en ressources. Il n’existait par ailleurs pas de SLA clair pour les délais de propagation. Et certains pipelines ne prenaient pas en charge le déploiement incrémental.
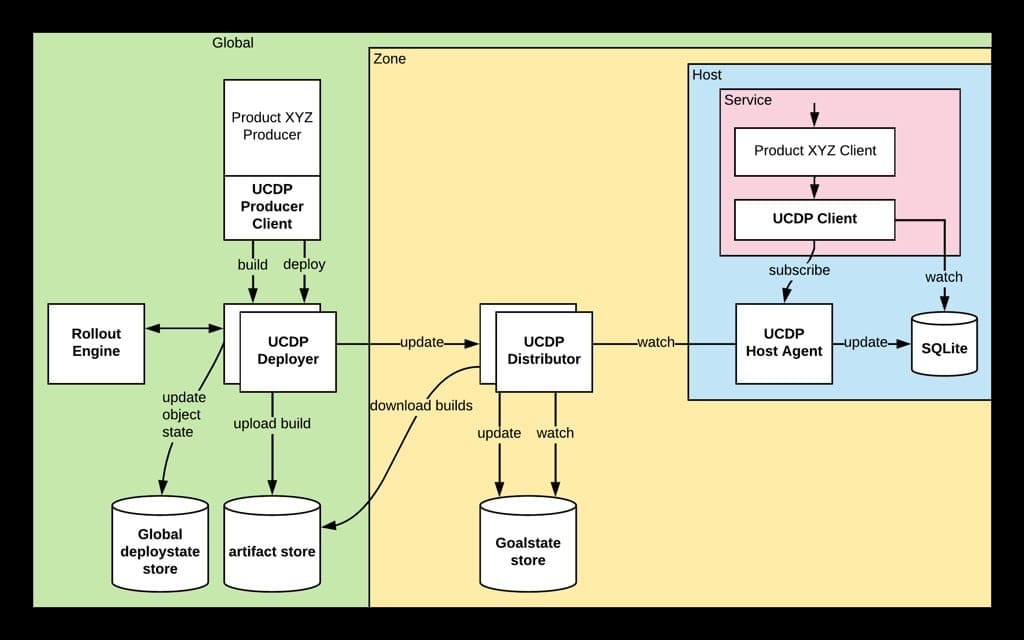
La solution ? UCDP (Unified Configuration Distribution Platform). Cette plate-forme expose une API et fournit une bibliothèque de clients de configuration. Son agent fonctionne sur tous les serveurs de prod d’Uber.
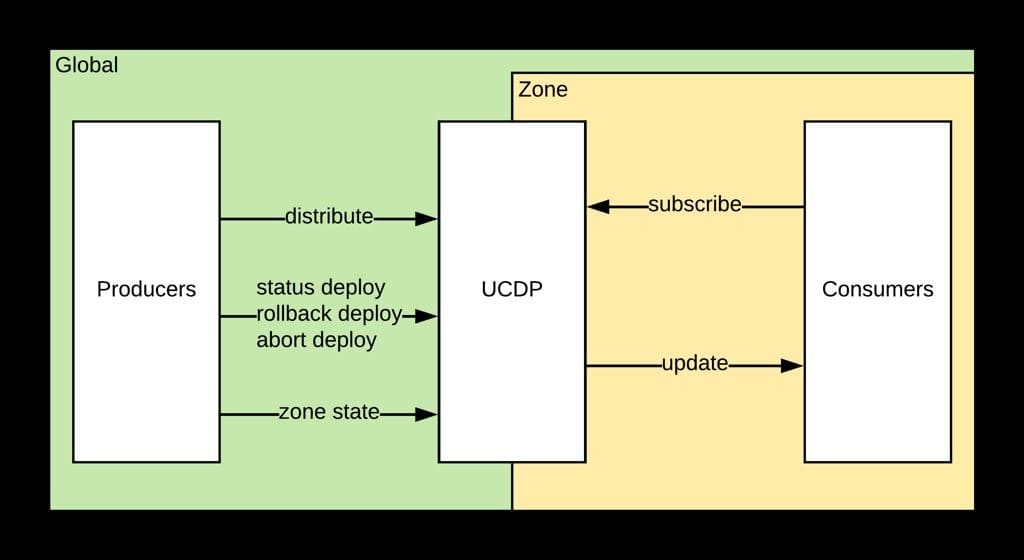
Les « producteurs » exploitent les API RPC de déploiement pour envoyer soit des mises à jour complètes (snapshots) de namespaces de configuration (ensemble de propriétés liées), soit des correctifs complémentaires (patchs).
Les « consommateurs » souscrivent à un ou plusieurs namespaces et les mettent en cache.
Uber s’appuie sur Apache Zookeeper
UDCP s’architecture en trois couches.
Le niveau global correspond au plan de contrôle. Il englobe des zones. Au sein de chacune se trouve un « distributeur » qui récupère les mises à jour et les transmet aux hôtes. Pour en coordonner les instances, Uber a mis en place un magasin d’états désirés fondé sur Apache Zookeeper.
Lire aussi : Data quality : un marché segmenté par l'IA ?
Pour illustrer l’interaction entre ces couches, Uber prend l’exemple d’un de ses « producteurs » : Flipr, un outil de gestion dynamique de configuration.
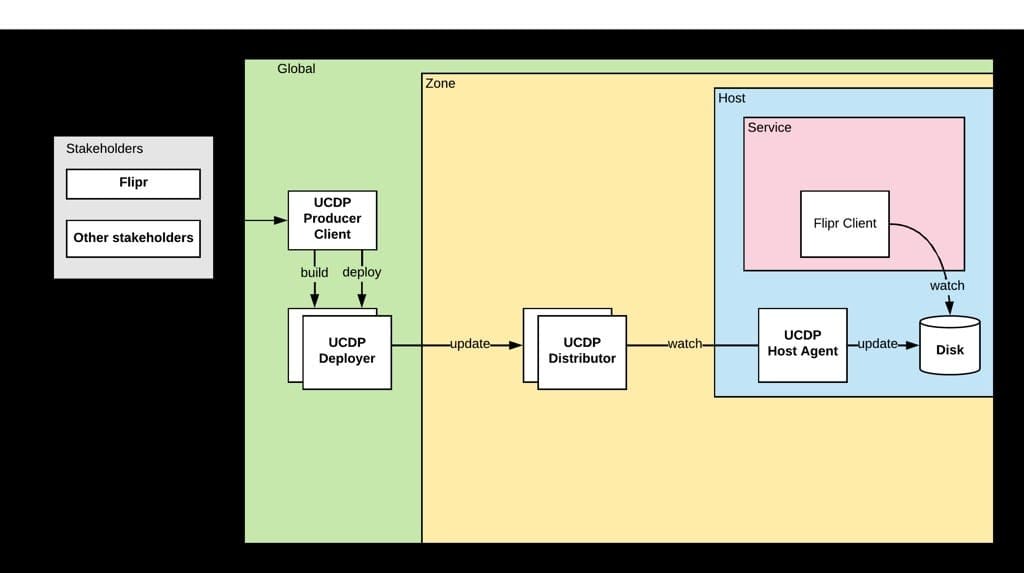
En fonction de la stratégie de déploiement, les updates sont poussés vers une ou plusieurs zones. Lorsqu’une zone reçoit un snapshot ou un patch, elle met d’abord à jour son magasin d’états désirés. Tout les instances du « distributeur » surveillent les changements sur ce magasin. Elles les téléchargent, en conservent une copie en mémoire, puis transmettent aux agents d’hôtes qui y ont souscrit. Ces derniers les écrivent sur le disque, puis les appliquent en fonction d’événements inotify.
L’agent UCDP est déployé sur plus de 150 000 hôtes. Sans optimisation, les relancer – ou relancer les distributeurs – entraîne le réenvoi de snapshots à tous les agents. Et donc, la consommation d’autant de ressources.
L’agent conservant une copie sur disque, lorsque son conteneur est mis à jour, il récupère les informations en local et les renvoie au distributeur auquel il est connecté. Si ces informations (namespace, version, checksum) ne correspondent pas à celles présentes sur le distributeur, on transmet un snapshot. Sinon, uniquement les patchs ultérieurs. Il se passe la même chose lorsque le conteneur d’un distributeur est mis à jour : l’agent se connecte à une autre instance.
Push, mise en cache et garde-fous
La généralisation du push a réduit la pression sur la stack réseau (environ 25 % des appels provenaient auparavant des pipelines de gestion de configuration). Introduire un cache au niveau zone a, en parallèle, réduit le temps de redémarrage des services. Ils se comptent en minutes, non plus en heures.
Sur les délais de propagation, Uber a défini des SLA par catégories de configurations : les petites, les moyennes et les grandes (aucune garantie pour ces dernières). Ces SLA se fondent sur la taille et le type d’update. Il est question d’y intégrer un autre paramètre : le nombre de souscripteurs.
Le système compte plus de 1,5 million de clients pour 150 000 hôtes. Avec quelque 400 000 déploiements de configuration par semaine, cela représente un volume hebdomadaire de 350 Tio de données. Pour éviter les goulets d’étranglement, Uber a introduit divers garde-fous. Parmi eux, des limites de volume de données sortantes au niveau zone et de nombre de nœuds enfants sur Zookeeper.
Illustration principale générée par IA
Sur le même thème
Voir tous les articles Business![OpenAI : SoftBank confirme une levée de fonds de 40 milliards [...]](https://cdn.edi-static.fr/image/upload/c_lfill,h_201,w_298/e_unsharp_mask:100,q_auto/f_auto/v1/Img/BREVE/2025/4/470011/openai-softbank-levee-fonds-milliards-L.jpg)
Par Philippe Leroy
2 min.Par La rédaction
Par Matthew Broersma
Par Philippe Leroy
Par La rédaction






{kind=link}