

IA : quelles alternatives à Nvidia ?
La domination de Nvidia provoque des effets collatéraux sur le marché. Difficultés d’approvisionnement, coûts stratosphériques de ses précieuses puces…Beaucoup d’entreprises cherchent aujourd’hui des alternatives.

Sommaire
La légende veut que ce soient les étudiants en IA du professeur Geoffrey E. Hinton qui, en tant que gamers, ont eu l’idée d’utiliser les cartes graphiques pour entraîner les réseaux de neurones, objet de leur recherche.
Résultat, à l’occasion du NIPS 2012, ceux-ci publient un papier de recherche où ils explosent littéralement les performances de reconnaissance d’image sur le jeu de données ImageNet, véritable benchmark de la communauté scientifique d’alors.
Leur réseau de neurones compte alors 60 millions de paramètres et 500 000 neurones en 5 couches… A partir de ce moment, l’IA va sortir de l’hiver dans laquelle la discipline est plongée depuis les années 70.
DNNresearch, la start-up créée par IA Geoffrey E. Hinton et ses deux étudiants Alex Krizhevsky et Ilya Sutskever est rachetée par Google en 2013.
On connaît la suite. Toutes les librairies Open Source majeures du Machine Learning et du Deep Learning vont exploiter les capacités matérielles des cartes graphiques via la librairie Cuda créée par Nvidia en 2006.
Cette couche logicielle alliée à des GPU de plus en plus puissants vont faire la fortune de NVidia. Lors du GTC 2018 (GPU Technologie Conference), Jensen Huang résumait d’une phrase sa stratégie : « L’innovation n’est pas seulement dans les puces, il s’agit d’un stack complet ».
Très rapidement, Jensen Huang, le CEO de Nvidia, a saisi la balle au bond en tirant profit de cet écosystème logiciel unique et en offrant des puces de plus en plus adaptées à l’entraînement des modèles et à l’exécution des inférences.

Illustration de la domination de Nvidia sur l’écosystème IA, Jensen Huang le CEO de Nvidia est venu remettre lui-même le tout premier H200 à Sam Altman et Greg Brockman dans les locaux d’OpenAI.
La commercialisation du P100 en 2016, suivi du V100 un an plus tard, puis le Q800, le A100 en 2020 et enfin le H100 en 2020 ont chacun apporté des innovations majeures pour la communauté IA si bien qu’on ne parle plus de loi de Moore dans la discipline, mais de loi de Huang.
Le A100, lancé en 2021, a vu tous les fournisseurs Cloud et quelques grandes multinationales faire des pieds et des mains afin d’être livrés en priorité et pouvoir répondre à la demande. Le H100 est venu asseoir cette domination en 2023, pour enfin aboutir cette année au H200. En moins de 10 ans, Nvidia s’est imposé comme la solution de référence dans le monde de l’IA et en tire pleinement profit aujourd’hui.
1 Intel et AMD contre-attaquent !
Mais si Nvidia est la star incontestée de l’IA comme ses résultats financiers et son cours de bourse en attestent, Intel ne s’est pourtant pas fait surprendre par l’essor de l’IA.
Si on met à part ces composants HD Graphics embarqués sur les toutes les cartes mères Intel, l’américain n’arrive pas à imposer ses GPU sur le marché des cartes accélératrices.
Intel a pourtant énormément investi dès les années 2010 avec des architectures extrêmement sophistiquées alliant des processeurs Xeon, sa puce massivement multi-cœur Xeon Phi ou des FPGA. La mayonnaise ne prenant pas, le fondeur a doté son Xeon Scalable des fonctions d’accélération « IA Intel Deep Learning Boost » depuis 2020.
Intel a aussi massivement investi dans les couches logicielles pour convaincre les data scientists, mais n’a jamais pu ébrécher réellement l’essor de Nvidia. L’autre axe d’attaque d’Intel sur l’IA porte sur les endpoints.
Lancé en décembre 2023, le Core Ultra doté d’un NPU (Neural Processing Unit) équipe désormais plus de 5 millions de PC et l’objectif est d’atteindre 40 millions fin 2024. Sa future architecture Lunar Lake verra la performance IA multipliée par 3 pour atteindre plus de 100 AI TOPS dont 45 délivrés par son NPU seul. Ces coprocesseurs IA sont amenés à se généraliser dans les PC comme c’est le cas sur les smartphones et tablettes.
Apple a bien évidemment doté ses puces M1, M2 et M3 d’un Neural Engine de plus en plus puissant, comme c’est aussi le cas des puces A11 à A17 des iPhone et même de la série S4 à S9 qui équipe les Apple Watch.
2 Gaudi3, le H100 Killer d’Intel
Dans les datacenters, Intel pousse toujours son Xeon dont la version 6 (Granite Rapids) apporte une puissance par Watt multipliée par 2,5 mais propose désormais un accélérateur IA : Gaudi 3. Cet accélérateur est livré sur une carte mezzanine et un serveur complet sur le modèle du H100 de Nvidia qu’il vient directement défier.
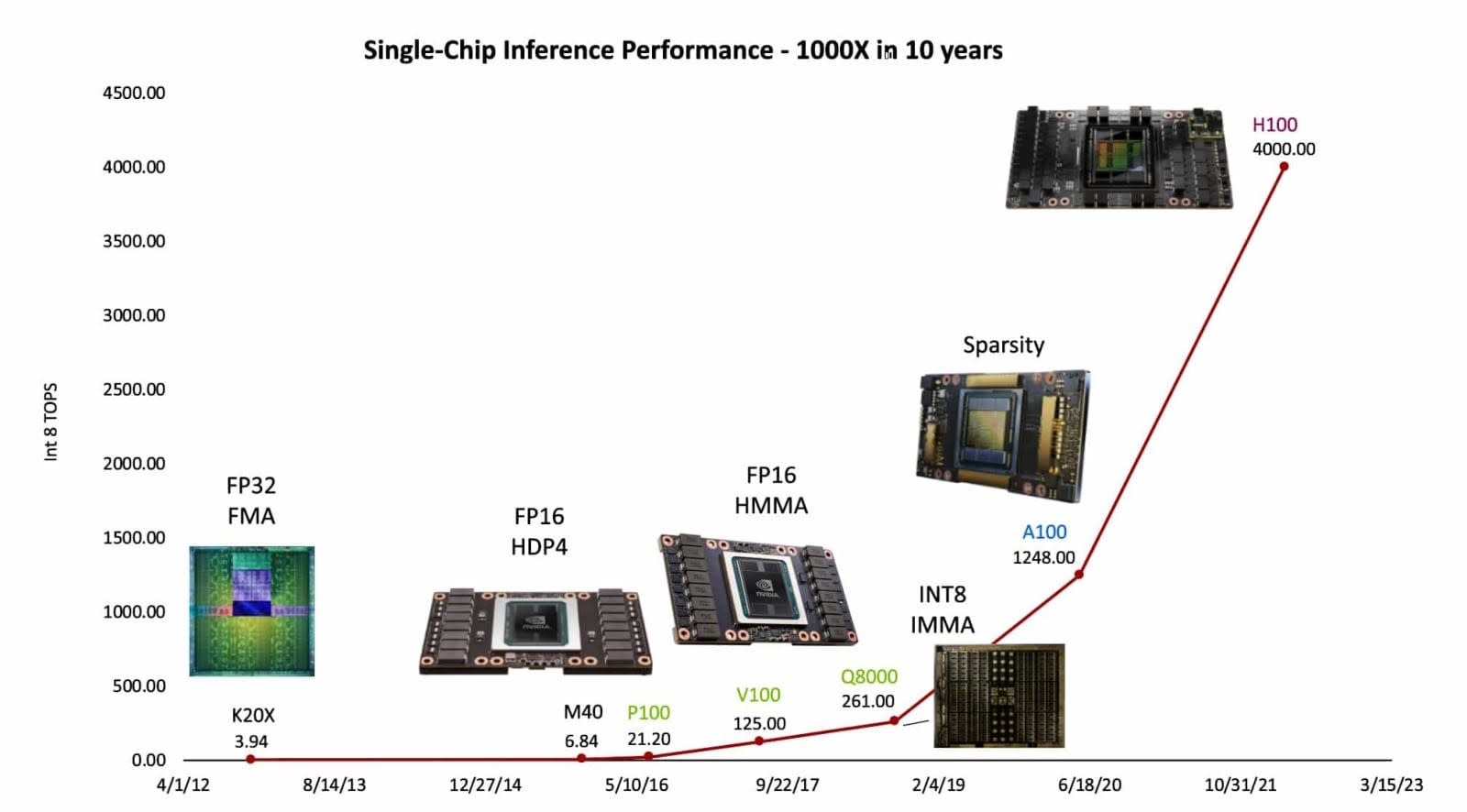
Avec une multiplication par 1 000 de la puissance des GPU en 10 ans, la loi de Huang a pris le relai de la célèbre loi de Moore pour les CPU.
Selon les benchmark fournis par Intel d’afficher une performance de 1,5 fois supérieure à un Nvidia H100 sur les modèles Llama-7B, Llama-70B et Falcon-180B et de 1,3 sur le H200. Intel livre sa puce sous forme de carte mezzanine, de carte PCIe ou sur une lame de calcul comprenant 8 cartes mezzanines.
Lors du lancement, Michael Dell a annoncé la commercialisation de PowerEdge XE9680 dans le courant de cette année : « Gaudi3 renforce notre partenariat en répondant aux besoins d’infrastructure des clients, en réduisant le coût total de possession et en facilitant le déploiement. Et tout cela grâce à un écosystème ouvert comprenant des frameworks d’IA optimisés pour Dell et Gaudi3, ainsi que des tissus d’IA évolutifs basés sur Ethernet. »
3 AMD sort enfin du bois
Rival de toujours d’Intel, AMD est l’autre grand perdant du boom de l’IA de ces dernières années.
En réalisant l’acquisition du fabricant de GPU ATI en 2006, il était pourtant bien placé pour monter dans le train de l’IA. Avec le recul, la stratégie d’hybridation entre les fonctions CPU et GPU mise en œuvre par AMD au moment de l’acquisition, les fameux APU (Accelerated Processing Unit), ne correspond pas aux attentes du marché IA.

AMD de retour dans l’arène de l’IA avec son GPU Instinct MI300X. Celui-ci est notamment disponible chez plusieurs constructeurs de serveurs et sur certaines instances Azure. © DR
Depuis 2023, AMD tente un retour avec sa puce MI300X, un pur GPU qui contient 153 milliards de transistors gravés en 5nm. AMD annonce une bande passante de 128 Gb/s et une mémoire HBM3 très performante. Sur le papier, une lame avec 8 modèles MI300X présente plus de capacité mémoire et de bande passante qu’une lame Gaudi3 avec 128 Go et que les H100 et H200 qui comptent respectivement 5 et 6 modules.
Tout comme chez Intel, les têtes pensantes d’AMD ont bien compris que le succès de Nvidia était aussi du à son exceptionnel écosystème logiciel et l’américain fait feu de tout bois pour donner aux développeurs et Data Scientists les moyens d’utiliser ses puces.
En août 2023, AMD réalisait l’acquisition de Mipsology, une start-up française qui avait développé la pile logicielle Zebra AI. Celle-ci permettait de déployer des modèles d’IA bâtis sur des frameworks standards comme TensorFlow, Pytorch ou ONNX sur une infrastructure de type FPGA sans recompilation et sans avoir à refaire l’entraînement du modèle.
Un partenariat entre Mipsology et AMD permettait à ce dernier de proposer cette solution sur ses cartes FPGA Alveo. L’idée est de disposer d’un stack logiciel AMD Unified AI complet pour l’entraînement et l’exécution des inférences sur les infrastructures Cloud, Edge et endpoint.
Le clan des rouges ne s’est pas arrêté là puisqu’en octobre 2023, AMD annonçait la prise de contrôle de Nod.ai.
L’objectif reste le même : renforcer le stack logiciel avec les compilateurs de la start-up afin de faciliter le déploiement de modèles d’IA sur le hardware AMD. « Nod.ai va accélérer notre capacité à faire progresser la technologie des compilateurs open-source et à permettre des solutions d’IA portables et performantes dans l’ensemble du portefeuille de produits AMD. Les technologies de Nod.ai sont déjà largement déployées dans le Cloud, en Edge et sur une large gamme de terminaux. » explique Vamsi Boppana, vice-président de l’activité d’intelligence artificielle chez AMD.
4 Les hyperscalers poussent leurs pions
De nouveaux entrants sont néanmoins en train de prendre position face aux fabricants de puces, ce sont les hyperscalers.
Tous doivent proposer des instances et services managés mettant à disposition des GPU NVidia, mais le « Big Three » propose depuis plusieurs années ses propres composants. Google a montré la voie en créant les TPU (Tensor Processing Units) pour ses besoins internes dès 2015, puis en les commercialisant sur Google Cloud en 2018.
Refroidis par « water cooling », ces composants nécessitent des serveurs lames et des racks très spécifiques. L’avantage du modèle Cloud est de pouvoir utiliser ses ressources sous forme de services managés, sans investissement initial et avec la possibilité de bénéficier des améliorations régulièrement apportées par le Cloud provider.
Ainsi, Google Cloud a mis à jour l’architecture de son composant à plusieurs reprises, jusqu’au TPUv5p dont la bande passante atteint 2 765 Gb/s et la puissance de 459 TOPS sur les calculs en virgule flottante BF16 et 918 TOPS sur les entiers 8 bits (int8).
En parallèle, Google propose des TPU pour le Edge Computing, un ASIC disponible sur des cartes électroniques commercialisées par Coral et qui permet à l’américain de proposer une infrastructure IA de bout en bout.
Cette stratégie a certainement inspiré Amazon Web Service qui s’est adossé à Annapurna Labs en 2018 pour créer un composant conçu pour l’exécution des inférences, Inferentia.
En 2020, le catalogue AWS s’est étoffé avec le Trainium, une puce cette fois dédiée à l’entraînement des IA. Il s’agissait alors de créer des alternatives à la fois moins coûteuses et moins énergivores aux puces Nvidia.
Fin 2023, AWS lançait Trainium2 et évoquait à son lancement la possibilité de créer des clusters de 100 000 Trainium2 pour obtenir une puissance de calcul de 65 Exaflops…
Microsoft n’est bien évidemment pas en reste avec sa puce Maia 100 dévoilée avec le microprocesseur ARM Cobalt 100 lors de la conférence Microsoft Ignite 2023.
Comme ses concurrents directs, Microsoft se doit d’être pragmatique et répondre aux attentes de ses clients. Azure propose bien évidemment des H100 sur son Cloud et prochainement des H200, mais aussi des VM disposant de l’accélérateur MI300X d’AMD.
Néanmoins, l’américain a aussi travaillé sur le design de ses propres puces IA. La puce Maia 100 est le fruit de ces efforts des conseils des ingénieurs d’OpenAI puisque le partenaire de Microsoft dans l’IA générative a été impliqué dans la conception de ce composant.
Sam Altman, PDG d’OpenAI a ainsi déclaré : « Dès notre premier partenariat avec Microsoft, nous avons collaboré pour concevoir conjointement l’infrastructure d’IA d’Azure à chaque couche pour nos modèles et nos besoins de formation sans précédent. Nous avons été enthousiasmés lorsque Microsoft a partagé pour la première fois ses conceptions pour la puce Maia, et nous avons travaillé ensemble pour l’affiner et la tester avec nos modèles. L’architecture d’IA de bout en bout d’Azure, désormais optimisée jusqu’au silicium avec Maia, ouvre la voie à la formation de modèles plus performants et à la réduction du coût de ces modèles pour nos clients. »
Au-delà de l’effet d’annonce, peu d’informations ont filtré sur les performances de ce composant, si ce n’est qu’il est gravé en 5nm par TSMC et compte 105 milliards de transistors… le maximum de ce qui est faisable actuellement assure Satya Nadella.
Les racks spécifiques intégrant le « water cooling » seront utilisés dans les datacenters d’Azure pour porter les applications Microsoft dont Copilot dans un premier temps. Puis, ils seront proposés aux utilisateurs du Cloud Azure dans une deuxième phase.
En proposant à la fois les GPU de Nvidia, d’AMD et ses propres composants, Microsoft offre le choix le plus large à ses clients, mais cherche aussi un moyen de faire face à la pénurie de GPU hautes performances et accessoirement disposer d’un levier pour être en meilleure position pour négocier les prix et les volumes avec Nvidia.
5 Europe : STMicrolectronics , Kalray, SiPearl et cie
Le juteux marché des GPU pour l’IA à déclencher de grandes manœuvres tant chez les fournisseurs de composants américains que les fournisseurs Cloud.
L’Europe est clairement à la traîne tant dans l’adoption de l’IA que pour en fournir les composants clés. Les fournisseurs de Cloud européen n’ont pas les reins suffisamment solides pour suivre les hyperscalers dans la conception de puces ad-hoc et doivent se contenter d’envoyer leurs bons de commande à Nvidia.
De même, du côté des fournisseurs de composants électroniques, le champion européen STMicrolectronics doit se contenter de jouer en deuxième division en proposant des puces IA pour le Edge seulement. Des inférences de Machine Learning peuvent être chargées sur ses microcontrôleurs et microprocesseurs STM32 ainsi que ses DSP destiné à l’IoT.
De même, pour le marché automobile, STMicrolectronics propose son outil SPC5Studio.AI pour déployer des modèles d’IA sur ses microcontrôleurs SPEC58 et Stellar E conçus pour les véhicules électriques. Elle joue la complémentarité avec les hyperscalers, notamment avec sa solution AWS STM32 ML at the Edge Accelerator dès mise en œuvre par Lacroix dans le cadre d’application IoT pour la Smart City.
De même, STMicrolectronics joue la carte de la complémentarité avec Nvidia et son toolkit TAO. Les modèles conçus et entraînés via la solution Nvidia sont convertis en code C et exécutés sur les microcontrôleurs STM32H7. Ceux-ci ont une consommation énergétique très faible et peuvent être déployés directement sur des équipements où le coût et la consommation électrique d’un GPU sont rédhibitoires.
Le projet de processeur européen EPI (European Processor Initiative) qui est entré dans sa deuxième phase intègre bien un volet accélérateur. Celui-ci sera basé sur une architecture Risc-V et disposera de STX (Stencil/Tensor Accelerator) pour accélérer l’apprentissage machine.
Le français SiPearl participe à ce vaste programme de recherche et développement et va notamment équiper le futur supercalculateur européen exascale JUPITER avec ces processeurs Rhea1.
Quels seront la puissance et l’efficacité énergétique des puces issues du programme EPI par rapport à ses nombreuses concurrentes américaines lorsque celles-ci seront commercialisées ? La question reste posée.

Une carte d’accélération TC4 est une solution d’accélération souveraine conçue et assemblée en France. Son constructeur la destine en priorité aux applications d’IA Edge ou dans la préparation des données d’apprentissage des IA génératives. © DR
Une solution européenne existe déjà, c’est la carte d’accélération TC4 proposée par le français Kalray. La carte d’accélération TurboCard4 intègre 4 de ses composants multi-cœurs Coolidge V2. Chaque puce compte 80 cœurs offre une performance de 50 TOPS sur les entiers 8 bits et 25 TFLOPS sur les calculs en virgule flottante 16 bits.
Plutôt que de se placer en concurrence frontale avec Nvidia, le français estime que sa puce DPU (Data Processing Unit) est un complément du GPU.
Kalray vise le marché de la vision par ordinateur avec KANN, une solution complète pour créer des CNN (réseaux de neurones convolutifs) et les déployer en Edge. Enfin, la carte peut être exploitée pour l’indexation des données pour rendre les phases d’apprentissage et d’inférence des IA génératives plus rapides.
L’écosystème en microélectronique grenoblois est fécond. Outre SiPearl et Kalray, la start-up HawAI.tech s’est lancée dans l’aventure avec une puce conçues pour les algorithmes probabilistes. S’appuyant sur les travaux de recherche de l’INRIA et du développeur d’IA Probayes, l’entreprise devrait dévoiler sa première puce dans le courant de l’année 2024.
Image : Google Cloud TPU racks © Google
L’oeil expert
Philippe Wieczorek, Directeur R&D et Innovation de Minalogic

© DR
« Nvidia est parti du marché des cartes graphiques et a sans doute compris avant tout le monde que le calcul matriciel et vectoriel pouvait être mis à profit dans d’autres domaines. Ils ont créé le langage Cuda et, de fait, les cartes Nvidia ont été de plus en plus utilisées par les acteurs de l’IA.
Intel et AMD ont été décrochés de ce marché et même si des alternatives propriétaires sont apparues chez les fournisseurs Cloud, le vrai souci de cette prédominance de Nvidia sur ce marché c’est la pénurie de composants.
Depuis la crise du Covid, Nvidia peine à répondre à la demande et cela pose un problème de monopole et de souveraineté puisque l’Europe se voit totalement dépendante d’acteurs américains.
Plusieurs start-up françaises se sont lancées dans l’aventure avec des propositions extrêmement séduisantes et des ratios performances / consommation bien meilleurs de ceux de Nvidia. La technologie et le savoir-faire sont là, mais leur développement est entravé par le manque de capitaux. Là où une startup va lever x millions en France, une startup américaine va lever 10 à 1 000 fois plus. Or l’électronique est un domaine qui a un fort besoin de capitaux pour se développer. La mise pour mettre au point une génération de composant est de 4 millions € minimum et il faut 3 à 4 itérations pour disposer d’un composant performant…»
Sur le même thème
Voir tous les articles Workspace![Windows 11 : le casse-tête des 'expériences de Copilot+ PC' en [...]](https://cdn.edi-static.fr/image/upload/c_lfill,h_201,w_298/e_unsharp_mask:100,q_auto/f_auto/v1/Img/BREVE/2025/4/471783/windows-casse-tete-experiences-copilot-entreprise-L.jpg)
Par Clément Bohic
3 min.Par Clément Bohic
Par La rédaction
Par La rédaction





