

Deep learning : que projette Microsoft avec Singularity ?
Comment optimiser l'exécution des tâches d'apprentissage profond sur une infrastructure à grande échelle comme Azure ? Microsoft y travaille sous la bannière Singularity. Tour d'horizon.

Planifier les tâches d'apprentissage profond pour optimiser l'utilisation des ressources matérielles sous-jacentes. Mais le faire à l'échelle de centaines de milliers d'accélérateurs... et en toute transparence, sans impliquer les utilisateurs. Ainsi pourrait-on résumer l'objectif de Singularity. Porteur du projet, Microsoft vient de fournir des détails techniques, dans un article signé de 26 de ses chercheurs.
Deux principes-clés à en retenir : la préemption et l'élasticité. Dans les grandes lignes :
- L'ensemble des ressources sont traitées comme un cluster unique partagé (pas de fragmentation ou de réservation de capacité).
- Les tâches - instanciées sous forme de microservices - peuvent à tout moment se déplacer sur cette infrastructure... et reprendre là où elles s'étaient arrêtées.
- On peut les redimensionner peu importe le socle d'exécution, et sans dépendances.
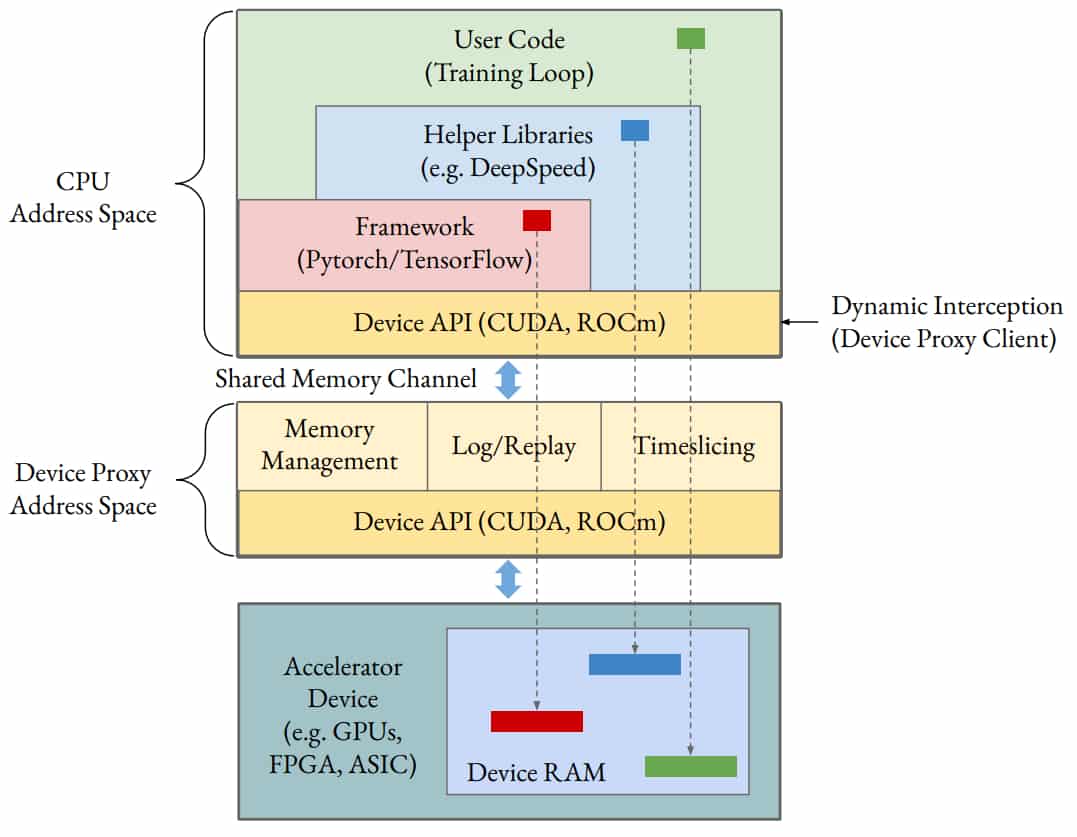
Au coeur du réacteur, il y a un mécanisme de découpage temporel. Singularity peut ainsi placer de multiples tâches sur un même accélérateur tout en permettant à chacune d'entre elles d'exploiter l'intégralité de la mémoire à disposition.
Plusieurs leviers sont mis à contribution pour limiter l'empreinte de ce mécanisme. En particulier, un proxy. Son cycle de vie est découplé de celui des tâches. Il se place sur l'interface CPU-accélérateur pour intercepter les appels des bibliothèques de deep learning (CUDA pour les GPU NVIDIA, ROCm pour AMD...).

Singularity : des SLA aussi pour l'entraînement
Tous ces appels sont envoyés au serveur (un par accélérateur), situé dans un espace d'adressage isolé. Le proxy peut alors être partagé entre les sous-tâches. Avec une faible latence, assurent les chercheurs, en particulier grâce à l'utilisation de canaux de mémoire partagés. Et sans entraver le fonctionnement de CRIU.
Cet outil logiciel permet de « geler » une application et de la contrôle dans un stockage persistant. Singularity le met à profit pour réaliser des instantanés des tâches.
Ces instantanés englobent quatre états : CPU (programme), GPU (modèle), interaction CPU-GPU et communication inter-GPU/internoeuds. Et selon deux modes : soit périodiquement (intervalle en temps ou en cycles, défini par l'utilisateur), soit à la demande (quand le planificateur décide de préempter une tâche).
CRIU intervient sur la partie CPU, moyennant l'isolation des espaces d'adressage des bibliothèques de deep learning. Pour gérer l'état du GPU, Singularity utilise memcpy. Sur la partie communications, il a recours à un algorithme d'orchestration. Diverses techniques sont mises en oeuvre pour limiter le poids des instantanés. Par exemple, chaque sous-tâche calcule le checksum de son contenu et ne le transfère que si aucun autre worker ne l'a déjà fait.
De cette capacité de migration « transparente » associée au découpage temporel découle l'élasticité elle aussi « transparente ». Évidemment, sous le capot, il y a de nombreux ajustements. Comme l'apport d'une couche sémantique au niveau du découpage temporel, l'optimisation des changements de contexte ou une gestion différenciée des tampons « stables » (paramètres, optimiseur) vs les « instables » (gradients, activations).
En décorrélant les tâches des ressources sous-jacentes, Singularity offre une résistance aux pannes. La préemption lui permet d'assurer des SLA, y compris pour l'entraînement. Tout en exploitant plus idéalement la capacité disponible, avec mises à jour « à chaud » et défragmentation en arrière-plan.

Les SLA auxquels s'attendre en l'état. Une tâche qui nécessiterait h heures sur une capacité dédiée exigerait au plus 0,95h au niveau Premium et 0,7h au niveau Standard.
Le stockage objet d'Azure, un goulet d'étranglement
Le gros de l'article concerne les cas où on parallélise les données. Les chercheurs expliquent toutefois les techniques qu'ils ont mises en place pour les tâches fondées sur des modèles, des tenseurs ou des pipelines parallèles. Pour ces dernières par exemple, il a fallu tenir compte du système d'échange de gradients entre noeuds (P2P) pour chaque microbatch. Et côté tenseurs, sur l'opération de réconciliation (allreduce) appliquée avec chaque multiplication matricielle.
Pour mettre Singularity à l'épreuve, les chercheurs lui ont donné 7 modèles, à entraîner et à exécuter sur des serveurs DGX-2 (2 Xeon Platinum 8168 à 20 coeurs, 692 Go de RAM, 8 GPU V100 par noeud avec NVLink) connectés en InfiniBand. Ils communiquent les données suivantes :
- Le proxy induit une surcharge de moins de 3 % par minibatch sur la plupart des modèles. Dont GPT-2 et InternalT, qui combinent parallélisme des données, des tenseurs et des pipelines.

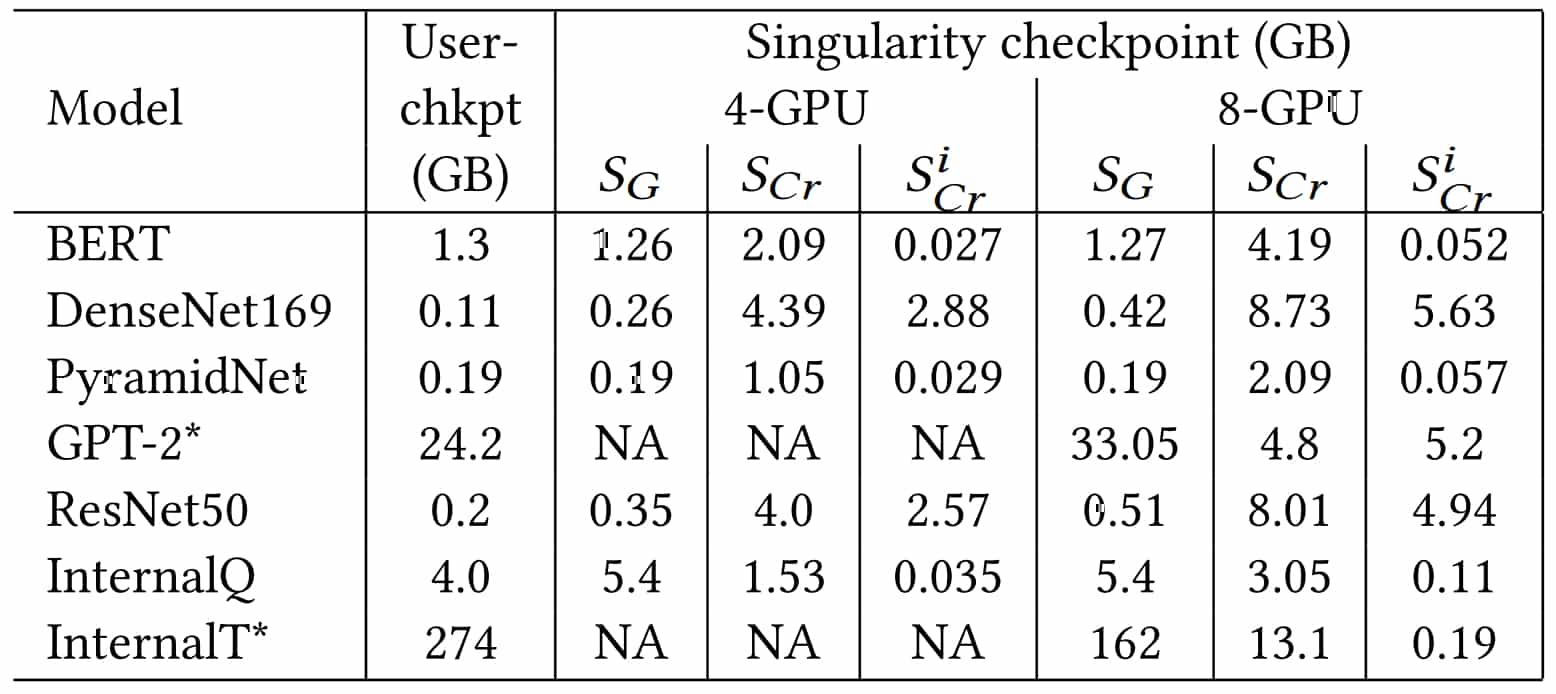
- La déduplication rend les instantanés d'états CPU plus légers que les équivalents réalisés au niveau utilisateur. C'est moins remarquable sur les états GPU.

- En mode scaled-down, le découpage temporel occasionne moins de 3 % de surcharge sur la plupart des modèles. On va jusqu'à 5 % pour les plus petits (minibatchs de moins de 200 ms).
Lire aussi : Les mini-PC petascale de NVIDIA prennent corps

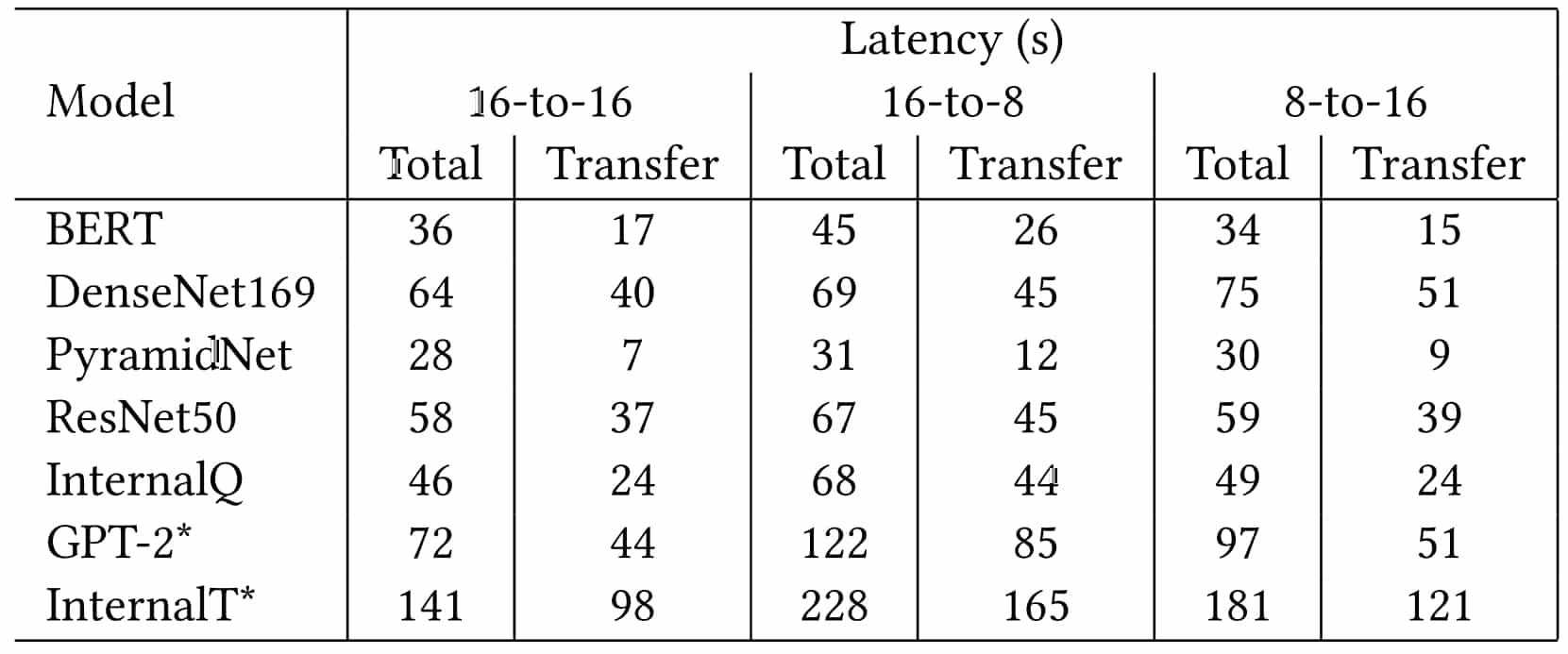
- Pour l'essentiel des modèles, la migration et le redimensionnement de tâches consomme quelques dizaines de secondes. Dont plus de la moitié pour les échanges avec le stockage objet Azure. Aussi, les chercheurs travaillent sur un système de transfert P2P sur InfiniBand.

Illustration principale © Waffals
Sur le même thème
Voir tous les articles Data & IA
Par Clément Bohic
3 min.Par Clément Bohic
Par Alain Clapaud
Par Clément Bohic
Par Clément Bohic






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}